Oct. 20, 2023

In keeping with a strong strategic focus on AI for the 2023-2024 Academic Year, the Institute for Data Engineering and Science (IDEaS) has announced the winners of its 2023 Seed Grants for Thematic Events in AI and Cyberinfrastructure Resource Grants to support research in AI requiring secure, high-performance computing capabilities. Thematic event awards recipients will receive $8K to support their proposed workshop or series and Cyberinfrastructure winners will receive research support consisting of 600,000 CPU hours on the AMD Genoa Server as well as 36,000 hours of NVIDIA DGX H-100 GPU server usage and 172 TB of secure storage.
Congratulations to the award winners listed below!
Thematic Events in AI Awards
Proposed Workshop: “Foundation of scientific AI (Artificial Intelligence) for Optimization of Complex Systems”
Primary PI: Peng Chen, Assistant Professor, School of Computational Science and Engineering
Proposed Series: “Guest Lecture Seminar Series on Generative Art and Music”
Primary PI: Gil Weinberg, Professor, School of Music
Cyber-Infrastructure Resource Awards
Title: Human-in-the-Loop Musical Audio Source Separation
Topics: Music Informatics, Machine Learning
Primary PI: Alexander Lerch, Associate Professor, School of Music
Co-PIs: Karn Watcharasupat, Music Informatics Group | Yiwei Ding, Music Informatics Group | Pavan Seshadri, Music Informatics Group
Title: Towards A Multi-Species, Multi-Region Foundation Model for Neuroscience
Topics: Data-Centric AI, Neuroscience
Primary PI: Eva Dyer, Assistant Professor, Biomedical Engineering
Title: Multi-point Optimization for Building Sustainable Deep Learning Infrastructure
Topics: Energy Efficient Computing, Deep Learning, AI Systems OPtimization
Primary PI: Divya Mahajan, Assistant Professor, School of Electrical and Computer Engineering, School of Computer Science
Title: Neutrons for Precision Tests of the Standard Model
Topics: Nuclear/Particle Physics, Computational Physics
Primary PI: Aaron Jezghani - OIT-PACE
Title: Continual Pretraining for Egocentric Video
Primary PI: : Zsolt Kira, Assistant Professor, School of Interactive Computing
Co-PI: Shaunak Halbe, Ph.D. Student, Machine Learning
Title: Training More Trustworthy LLMs for Scientific Discovery via Debating and Tool Use
Topics: Trustworthy AI, Large-Language Models, Multi-Agent Systems, AI Optimization
Primary PIs: Chao Zhang, School of Computational Science and Engineering & Bo Dai, College of Computing
Title: Scaling up Foundation AI-based Protein Function Prediction with IDEaS Cyberinfrastructure
Topics: AI, Biology
Primary PI: Yunan Luo, Assistant Professor, School of Computational Science and Engineering
- Christa M. Ernst
News Contact
Christa M. Ernst - Research Communications Program Manager
Robotics | Data Engineering | Neuroengineering
Oct. 20, 2023

The Institute for Data Engineering and Science, in conjunction with several Interdisciplinary Research Institutes (IRIs) at Georgia Tech, have awarded seven teams of researchers from across the Institute a total of $105,000 in seed funding geared to better position Georgia Tech to perform world-class interdisciplinary research in data science and artificial intelligence development and deployment.
The goals of the funded proposals include identifying prominent emerging research directions on the topic of AI, shaping IDEaS future strategy in the initiative area, building an inclusive and active community of Georgia Tech researchers in the field that potentially include external collaborators, and identifying and preparing groundwork for competing in large-scale grant opportunities in AI and its use in other research fields.
Below are the 2023 recipients and the co-sponsoring IRIs:
Proposal Title: "AI for Chemical and Materials Discovery" + “AI in Microscopy Thrust”
PI: Victor Fung, CSE | Vida Jamali, ChBE| Pan Li, ECE | Amirali Aghazadeh Mohandesi, ECE
Award: $20k (co-sponsored by IMat)
Overview: The goal of this initiative is to bring together expertise in machine learning/AI, high-throughput computing, computational chemistry, and experimental materials synthesis and characterization to accelerate material discovery. Computational chemistry and materials simulations are critical for developing new materials and understanding their behavior and performance, as well as aiding in experimental synthesis and characterization. Machine learning and AI play a pivotal role in accelerating material discovery through data-driven surrogate models, as well as high-throughput and automated synthesis and characterization.
Proposal Title: " AI + Quantum Materials”
PI: Zhigang JIang, Physics | Martin Mourigal, Physics
Award: $20k (Co-Sponsored by IMat)
Overview: Zhigang Jiang is currently leading an initiative within IMAT entitled “Quantum responses of topological and magnetic matter” to nurture multi-PI projects. By crosscutting the IMAT initiative with this IDEAS call, we propose to support and feature the applications of AI on predictive and inverse problems in quantum materials. Understanding the limit and capabilities of AI methodologies is a huge barrier of entry for Physics students, because researchers in that field already need heavy training in quantum mechanics, low-temperature physics and chemical synthesis. Our most pressing need is for our AI inclined quantum materials students to find a broader community to engage with and learn. This is the primary problem we aim to solve with this initiative.
PI: Jeffrey Skolnick, Bio Sci | Chao Zhang, CSE
Proposal Title: Harnessing Large Language Models for Targeted and Effective Small Molecule 4 Library Design in Challenging Disease Treatment
Award: $15k (co-sponsored by IBB)
Overview: Our objective is to use large language models (LLMs) in conjunction with AI algorithms to identify effective driver proteins, develop screening algorithms that target appropriate binding sites while avoiding deleterious ones, and consider bioavailability and drug resistance factors. LLMs can rapidly analyze vast amounts of information from literature and bioinformatics tools, generating hypotheses and suggesting molecular modifications. By bridging multiple disciplines such as biology, chemistry, and pharmacology, LLMs can provide valuable insights from diverse sources, assisting researchers in making informed decisions. Our aim is to establish a first-in-class, LLM driven research initiative at Georgia Tech that focuses on designing highly effective small molecule libraries to treat challenging diseases. This initiative will go beyond existing AI approaches to molecule generation, which often only consider simple properties like hydrogen bonding or rely on a limited set of proteins to train the LLM and therefore lack generalizability. As a result, this initiative is expected to consistently produce safe and effective disease-specific molecules.
PI: Yiyi He, School of City & Regional Plan | Jun Rentschler, World Bank
Proposal Title: “AI for Climate Resilient Energy Systems”
Award: $15k (co-sponsored by SEI)
Overview: We are committed to building a team of interdisciplinary & transdisciplinary researchers and practitioners with a shared goal: developing a new framework which model future climatic variations and the interconnected and interdependent energy infrastructure network as complex systems. To achieve this, we will harness the power of cutting-edge climate model outputs, sourced from the Coupled Model Intercomparison Project (CMIP), and integrate approaches from Machine Learning and Deep Learning models. This strategic amalgamation of data and techniques will enable us to gain profound insights into the intricate web of future climate-change-induced extreme weather conditions and their immediate and long-term ramifications on energy infrastructure networks. The seed grant from IDEaS stands as the crucial catalyst for kick-starting this ambitious endeavor. It will empower us to form a collaborative and inclusive community of GT researchers hailing from various domains, including City and Regional Planning, Earth and Atmospheric Science, Computer Science and Electrical Engineering, Civil and Environmental Engineering etc. By drawing upon the wealth of expertise and perspectives from these diverse fields, we aim to foster an environment where innovative ideas and solutions can flourish. In addition to our internal team, we also have plans to collaborate with external partners, including the World Bank, the Stanford Doerr School of Sustainability, and the Berkeley AI Research Initiative, who share our vision of addressing the complex challenges at the intersection of climate and energy infrastructure.
PI: Jian Luo, Civil & Environmental Eng | Yi Deng, EAS
Proposal Title: “Physics-informed Deep Learning for Real-time Forecasting of Urban Flooding”
Award: $15k (co-sponsored by BBISS)
Overview: Our research team envisions a significant trend in the exploration of AI applications for urban flooding hazard forecasting. Georgia Tech possesses a wealth of interdisciplinary expertise, positioning us to make a pioneering contribution to this burgeoning field. We aim to harness the combined strengths of Georgia Tech's experts in civil and environmental engineering, atmospheric and climate science, and data science to chart new territory in this emerging trend. Furthermore, we envision the potential extension of our research efforts towards the development of a real-time hazard forecasting application. This application would incorporate adaptation and mitigation strategies in collaboration with local government agencies, emergency management departments, and researchers in computer engineering and social science studies. Such a holistic approach would address the multifaceted challenges posed by urban flooding. To the best of our knowledge, Georgia Tech currently lacks a dedicated team focused on the fusion of AI and climate/flood research, making this initiative even more pioneering and impactful.
Proposal Title: “AI for Recycling and Circular Economy”
PI: Valerie Thomas, ISyE and PubPoly | Steven Balakirsky, GTRI
Award: $15k (co-sponsored by BBISS)
Overview: Most asset management and recycling use technology that has not changed for decades. The use of bar codes and RFID has provided some benefits, such as for retail returns management. Automated sorting of recyclables using magnets, eddy currents, and laser plastics identification has improved municipal recycling. Yet the overall field has been challenged by not-quite-easy-enough identification of products in use or at end of life. AI approaches, including computer vision, data fusion, and machine learning provide the additional capability to make asset management and product recycling easy enough to be nearly autonomous. Georgia Tech is well suited to lead in the development of this application. With its strength in machine learning, robotics, sustainable business, supply chains and logistics, and technology commercialization, Georgia Tech has the multi-disciplinary capability to make this concept a reality, in research and in commercial application.
Proposal Title: “Data-Driven Platform for Transforming Subjective Assessment into Objective Processes for Artistic Human Performance and Wellness”
PI: Milka Trajkova, Research Scientist/School of Literature, Media, Communication | Brian Magerko, School of Literature, Media, Communication
Award: $15k (co-sponsored by IPaT)
Overview: Artistic human movement at large, stands at the precipice of a data-driven renaissance. By leveraging novel tools, we can usher in a transparent, data-driven, and accessible training environment. The potential ramifications extend beyond dance. As sports analytics have reshaped our understanding of athletic prowess, a similar approach to dance could redefine our comprehension of human movement, with implications spanning healthcare, construction, rehabilitation, and active aging. Georgia Tech, with its prowess in AI, HCI, and biomechanics is primed to lead this exploration. To actualize this vision, we propose the following research questions with ballet as a prime example of one of the most complex types of artistic movements: 1) What kinds of data - real-time kinematic, kinetic, biomechanical, etc. captured through accessible off-the-shelf technologies, are essential for effective AI assessment in ballet education for young adults?; 2) How can we design and develop an end-to-end ML architecture that assesses artistic and technical performance?; 3) What feedback elements (combination of timing, communication mode, feedback nature, polarity, visualization) are most effective for AI- based dance assessment?; and 4) How does AI-assisted feedback enhance physical wellness, artistic performance, and the learning process in young athletes compared to traditional methods?
- Christa M. Ernst
News Contact
Christa M. Ernst | Research Communications Program Manager
Robotics | Data Engineering | Neuroengineering
christa.ernst@research.gatech.edu
Oct. 19, 2023
</p>")
 Annalisa Bracco, Taka Ito, Chris Reinhard</p>")
Three Georgia Tech School of Earth and Atmospheric Sciences researchers — Professor and Associate Chair Annalisa Bracco, Professor Taka Ito, and Georgia Power Chair and Associate Professor Chris Reinhard — will join colleagues from Princeton, Texas A&M, and Yale University for an $8 million Department of Energy (DOE) grant that will build an “end-to-end framework” for studying the impact of carbon dioxide removal efforts for land, rivers, and seas.
The proposal is one of 29 DOE Energy Earthshot Initiatives projects recently granted funding, and among several led by and involving Georgia Tech investigators across the Sciences and Engineering.
Overall, DOE is investing $264 million to develop solutions for the scientific challenges underlying the Energy Earthshot goals. The 29 projects also include establishing 11 Energy Earthshot Research Centers led by DOE National Laboratories.
The Energy Earthshots connect the Department of Energy's basic science and energy technology offices to accelerate breakthroughs towards more abundant, affordable, and reliable clean energy solutions — seeking to revolutionize many sectors across the U.S., and relying on fundamental science and innovative technology to be successful.
Carbon Dioxide Removal
The School of Earth and Atmospheric Sciences project, “Carbon Dioxide Removal and High-Performance Computing: Planetary Boundaries of Earth Shots,” is part of the agency’s Science Foundations for the Energy Earthshots program. Its goal is to create a publicly-accessible computer modeling system that will track progress in two key carbon dioxide removal (CDR) processes: enhanced earth weathering, and global ocean alkalinization.
In enhanced earth weathering, carbon dioxide is converted into bicarbonate by spreading minerals like basalt on land, which traps rainwater containing CO2. That gets washed out by rivers into oceans, where it is trapped on the ocean floor. If used at scale, these nature-based climate solutions could remove atmospheric carbon dioxide and alleviate ocean acidification.
The research team notes that there is currently “no end-to-end framework to assess the impacts of enhanced weathering or ocean alkalinity enhancement — which are likely to be pursued at the same time.”
“The proposal is for a three-year effort, but our hope is that the foundation we lay down in that time will represent a major step forward in our ability to track carbon from land to sea,” says Reinhard, the Georgia Power Chair who is a co-investigator on the grant.
“Like many folks interested in better understanding how climate interventions might impact the Earth system across scales, we are in some ways building the plane in midair,” he adds. “We need to develop and validate the individual pieces of the system — soils, rivers, the coastal ocean — but also wire them up and prove from observations on the ground how a fully integrated model works.”
That will involve the use of several existing computer models, along with Georgia Tech’s PACE supercomputers, Professor Ito explains. “We will use these models as a tool to better understand how the added alkalinity, carbon and weathering byproducts from the soils and rivers will eventually affect the cycling of nutrients, alkalinity, carbon and associated ecological processes in the ocean,” Ito adds. “After the model passes the quality check and we have confidence in our output, we can start to ask many questions about assessment of different carbon sequestration approaches or downstream impacts on ecosystem processes.”
Professor Bracco, whose recent research has focused on rising ocean heat levels, says CDR is needed just to keep ocean systems from warming about 2 degrees centigrade (Celsius).
“Ninety percent of the excess heat caused by greenhouse gas emissions is in the oceans,” Bracco shares, “and even if we stop emitting all together tomorrow, that change we imprinted will continue to impact the climate system for many hundreds of years to come. So in terms of ocean heat, CDRs will help in not making the problem worse, but we will not see an immediate cooling effect on ocean temperatures. Stabilizing them, however, would be very important.”
Bracco and co-investigators will study the soil-river-ocean enhanced weathering pipeline “because it’s definitely cheaper and closer to scale-up.” Reverse weathering can also happen on the ocean floor, with new clays chemically formed from ocean and marine sediments, and CO2 is included in that process. “The cost, however, is higher at the moment. Anything that has to be done in the ocean requires ships and oil to begin,” she adds.
Reinhard hopes any tools developed for the DOE project would be used by farmers and other land managers to make informed decisions on how and when to manage their soil, while giving them data on the downstream impacts of those practices.
“One of our key goals will also be to combine our data from our model pipeline with historical observational data from the Mississippi watershed and the Gulf of Mexico,” Reinhard says. “This will give us some powerful new insights into the impacts large-scale agriculture in the U.S. has had over the last half-century, and will hopefully allow us to accurately predict how business-as-usual practices and modified approaches will play out across scales.”
News Contact
Writer: Renay San Miguel
Communications Officer II/Science Writer
College of Sciences
404-894-5209
Editor: Jess Hunt-Ralston
Oct. 18, 2023

Josiah Hester sits at a desk in an electronics lab at Georgia Tech with an array of prototype projects and test equipment in front of him.
Edge devices, such as wearables, cameras, smartphones, and smart home devices, have become the foundation of our daily interactions with technology. But the exponential growth in the number of these devices comes at a significant environmental cost, currently accounting for more than a third of the 4% of global carbon emissions attributed to information and communication technologies. This ecological impact is projected to worsen as the number of edge devices surges into trillions over the next few decades.
Josiah Hester, associate professor in the College of Computing, along with researchers from Cornell and Harvard Universities, has received a $2 million grant from the newly established Design for Environmental Sustainability in Computing program at the National Science Foundation. The investigators aim to study and mitigate the environmental impact of edge computing devices. Their winning project will make carbon and sustainability a first-order design parameter for future edge computing devices that range from tiny, energy-harvesting Internet of Things devices — often found in manufacturing lines, cars, agriculture, and cities — to higher performance consumer electronics like tablets and smartphones.
As part of the research, investigators will capture a first-of-its-kind dataset on actual emissions and resource usage of complex fabrication processes, build and validate tools for carbon-aware design, and establish an Electronic Sustainability Record for edge devices, similar to nutrition labels for food, or a digital health record, that allows consumers and manufacturers to understand the carbon costs of computing devices and use that in decision-making. The grant proposal was catalyzed through the Brook Byers Institute for Sustainable Systems Initiative Leads program, with additional funds from the Institute for Data Engineering and Science.
“Right now, hardware designers, programmers, and consumers have only a vague idea of the actual carbon cost of the phone, wearable, or smart device they are working with. With rising e-waste and technology’s increasing contributions to climate change, we have to figure out how to do better. This project will lay the foundations for edge devices that can last for decades, or at least have a lifetime commensurate with the carbon cost, potentially reducing e-waste, emissions, and environmental footprint,” said Hester. “Our design tools, new datasets, and carbon models will consider factors like energy, e-waste, and water usage from the manufacturing of computational devices, as well as operational carbon footprint from factors like machine learning and software lifecycles.”
With the grant money, Hester’s team will develop an end-to-end framework that prioritizes environmental impact, while considering user experience, performance, and efficiency when designing edge devices. The framework, which they are calling Delphi, will enable sustainable technological growth by laying out a path for the design of environmentally conscious edge devices with substantially longer lifecycles.
“Eventually, this research could lead to a kind of ‘nutrition label’ for computing devices, like your phone, to empower consumers with data to make more sustainability-friendly purchasing and use decisions,” Hester said. “This could incentivize and enable hardware companies to build lower carbon devices meant to last for many years, versus trading up after a contract renewal. We have a long way to go before this is reality, but this project will lay foundational steps in data collection, model building, and design tools — a sustainable vision of edge computing.”
News Contact
Brent Verrill, Research Communications Program Manager, BBISS
Sep. 21, 2023

For the 10th Demo Day, the Tech community came out in droves to support 75 Georgia Tech startups created by students, alumni, and faculty. In booths spread out in Exhibition Hall, they displayed their products, which ranged from AI and robotic training gear to fungi fashion, and more. Over four hours, more than 1,500 people filed in and out of the hall. Founders pitched their innovations to business and community leaders, as well as students and the public, eager to witness groundbreaking innovations across various industries.
Kiandra Peart, co-founder of Reinvend, said the amount of people surprised her.
“After the first VIP session was over, hundreds of people were just flooding through the door at all times,” she said. “We had to give the pitch a million times to explain it to a lot of different people, but they seemed really, really engaged, and we were also able to get a few interactions.”
Reinvend is working through a potential deal with Tech Dining on using their vending machines, which would expand food options for students after dining halls close.
Demo Day is the culmination of the 12-week summer accelerator, Startup Launch, where founders learn about entrepreneurship and build out their businesses with the support of mentors. Along with guidance from experts in business, teams receive $5,000 in optional funding and $30,000 of in-kind services. This year, the program had over 100 startups and 250 founders, continuing the growth trend for CREATE-X. The program aims to eventually support the launch of 300 startups per year.
Peart said the experience taught the team how to better pitch to potential clients and formulate a call to action after a successful interaction.
Since its inception in 2014, CREATE-X has had more than 5,000 participate in their programming, which is segmented in three areas: Learn, Make, and Launch. Besides providing resources, the program also helps founders through its rich entrepreneurial ecosystem.
“We want to increase access to entrepreneurship. That’s the heart of the program, and it’s the goal to have everyone in the Tech community to have entrepreneurial confidence. The energy and passion of our founders to solve real-world problems — it’s palpable at Demo Day. I’d say it’s the best place to see what we’re about and understand what this program offers,” said Rahul Saxena, director of CREATE-X, who also reminded founders that the connections they make here would last for years.
At its core, CREATE-X is a community geared toward innovation. Participants were at the forefront of integrating OpenAI's GPT-3 when it was not yet widely adopted. They share their insights with each other, and the program has mentors coming back from even the very first cohort. Starting with eight teams, CREATE-X has now launched more than 400 startup teams, with founders representing 38 academic majors. Its total startup portfolio valuation is above $1.9 billion.
Peart compared CREATE-X to an energy drink.
“After going through the program, I was really able to refine my ideas, talk with other people, and now that the program is over, I feel energized,” she said. “I think that having an accelerator right at home allows students who may have never considered starting a company, or didn't have access to an accelerator, to actually utilize their resources from their school and their own community to get their companies started.”
Although Demo Day just ended, CREATE-X is already gearing up for the next cohort. Applications for Startup Launch opened Aug. 31, the same day as Demo Day.
“Consider interning for yourself next summer,” said Saxena. “We know you have ideas about solutions to address global challenges. You’re at Tech; you have the talent. Let us help you with the resources and support system.”
Georgia Tech students, alumni, and faculty can apply to GT Startup Launch now. The priority deadline is Nov. 6. To learn more about CREATE-X, find CREATE-X events to build a startup team, or learn more about entrepreneurship, visit th CREATE-X website
News Contact
Breanna Durham
Marketing Strategist
Jul. 28, 2023










In February, a major earthquake event devastated the south-central region of the Republic of Türkiye (Turkey) and northwestern Syria. Two earthquakes, one magnitude 7.8 and one magnitude 7.5, occurred nine hours apart, centered near the heavily populated city of Gaziantep. The total rupture lengths of both events were up to 250 miles. The president of Turkey has called it the “disaster of the century,” and the threat is still not over — aftershocks could still affect the region.
Now, Zhigang Peng, a professor in the School of Earth and Atmospheric Sciences at Georgia Tech and graduate students Phuc Mach and Chang Ding, alongside researchers at the Scientific and Technological Research Institution of Türkiye (TÜBİTAK) and researchers at the University of Missouri, are using small seismic sensors to better understand just how, why, and when these earthquakes are occurring.
Funded by an NSF RAPID grant, the project is unique in that it aims to actively respond to the crisis while it’s still happening. National Science Foundation (NSF) Rapid Response Research (RAPID) grants are used when there is a severe urgency with regard to availability of or access to data, facilities or specialized equipment, including quick-response research on natural or anthropogenic disasters and other similar unanticipated events.
In an effort to better map the aftershocks of the earthquake event — which can occur weeks or months after the main event — the team placed approximately 120 small sensors, called nodes, in the East Anatolian fault region this past May. Their deployment continues through the summer.
It’s the first time sensors like this have been deployed in Turkey, says Peng.
“These sensors are unique in that they can be placed easily and efficiently," he explains. "With internal batteries that can work up to one month when fully charged, they’re buried in the ground and can be deployed within minutes, while most other seismic sensors need solar panels or other power sources and take much longer time and space to deploy.” Each node is about the size of a 2-liter soda bottle, and can measure ground movement in three directions.
“The primary reason we’re deploying these sensors quickly following the two mainshocks is to study the physical mechanisms of how earthquakes trigger each,” Peng adds. Mainshocks are the largest earthquake in a sequence. “We’ll use advanced techniques such as machine learning to detect and locate thousands of small aftershocks recorded by this network. These newly identified events can provide new important clues on how aftershocks evolve in space and time, and what drives foreshocks that occur before large events.”
Unearthing fault mechanisms
The team will also use the detected aftershocks to illuminate active faults where three tectonic plates come together — a region known as the Maraş Triple Junction. “We plan to use the aftershock locations and the seismic waves from recorded events to image subsurface structures where large damaging earthquakes occur,” says Mach, the Georgia Tech graduate researcher. This will help scientists better understand why sometimes faults ‘creep’ without any large events, while in other cases faults lock and then violently release elastic energy, creating powerful earthquakes.
Getting high-resolution data of the fault structures is another priority. “The fault line ruptured in the first magnitude 7.8 event has a bend in it, where earthquake activity typically terminates, but the earthquake rupture moved through this bend, which is highly unusual,” Peng says. By deploying additional ultra-dense arrays of sensors in their upcoming trip this summer, the team hopes to help researchers ‘see’ the bend under the Earth’s surface, allowing them to better understand how fault properties control earthquake rupture propagation.
The team also aims to learn more about the relationship between the two main shocks that recently rocked Turkey, sometimes called doublet events. Doublet events can happen when the initial earthquake triggers a secondary earthquake by adding extra stress loading. While in this instance, the doublet may have taken place only 9 hours after the initial event, these secondary earthquakes have been known to take place days, months, or even years after the initial one — a famous example being the sequence of earthquakes that spanned 60 years in the North Anatolian fault region in Northern Turkey.
“Clearly the two main shocks in 2023 are related, but it is still not clear how to explain the time delays,” says Peng. The team plans to work with their collaborators at TÜBİTAK to re-analyze seismic and other types of geophysical data right before and after those two main shocks in order to better understand the triggering mechanisms.
“In our most recent trip in southern Türkiye, we saw numerous buildings that were partially damaged during the mainshock, and many people will have to live in temporary shelters for years during the rebuilding process,” Peng adds. “While we cannot stop earthquakes from happening in tectonically active regions, we hope that our seismic deployment and subsequent research on earthquake triggering and fault imaging can improve our ability to predict what will happen next — before and after a big one — and could save countless lives.”
Dec. 13, 2022
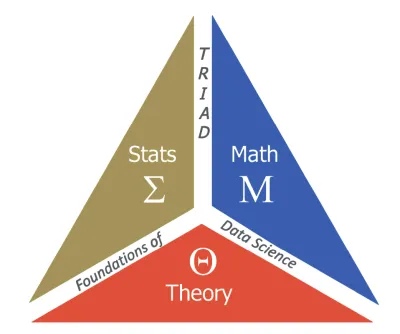

4 Questions with the IDEaS Leadership Team | Featuring Xiaoming Huo; A. Russell Chandler III Professor, H. Milton Stewart School of Industrial and Systems Engineering
This week we introduce Xiaoming Huo, A. Russell Chandler III Professor in the H. Milton Stewart School of Industrial and Systems Engineering at Georgia Tech and Associate Director for Research in the Institute for Data Science and Engineering.
Dr. Huo's research interests include statistical theory, statistical computing, and issues related to data analytics. He has made numerous contributions on topics such as sparse representation, wavelets, and statistical problems in detectability.
1. What is your field of expertise and what questions, or challenges sparked your current research?
My research is focused on the foundational principles of data sciences (also known as machine learning, artificial intelligence, etc.). A large spectrum of algorithms has been developed in the data science field, however, there remains a challenge to understand the performance and limitations of these algorithms and then provide helpful, practical guidelines for their usage by researchers. I began my journey to data science as an undergraduate mathematics major. I have been motivated by the emergence of data sciences and the fact that many of these challenging foundational problems are naturally mathematical. What I am doing now seems to be a perfect spot for someone who wants to explore fundamental mathematics while still making an impact in deployable applications.
2. Why is the field of Data Science and Engineering important to the development of Georgia Tech’s broader research strategy?
In the most recent science and engineering research endeavors, no matter the discipline, large amounts of data are generated and collected. Consequently, more and more research finding across colleges and schools at Georgia Tech, and globally, are data-driven. The ability to correlate and make meaningful connections within data will be essential for future researchers. Additionally, the innovative breakthroughs in science and engineering of the future are likely to rely heavily on the utilization of tools from data science and the availability of new data types.
3. What are the global and social benefits of the research you and your team conduct?
Currently, my research is primarily mathematical. Our end goal is to provide data handling principles, guidelines, and best practices that researchers and students can apply.
4. What are your plans on engaging a wider GT faculty pool with IDEaS research?
I am the executive director of the Transdisciplinary Research Institute for Advancing Data Science (TRIAD) (triad.gatech.edu). In 2017, we won an NSF TRIPODS Phase 1 award to establish this Center. TRIAD is housed under the Institute of Data Engineering and Sciences (IDEaS). I am currently serving as the Associate Director for Research (ADR) of IDEaS. As an ADR, I organize campus-wide activities related to data science research at Georgia Tech, aiming to catalyze collaborative activities. My current project is to organize a Georgia Tech workshop on the foundations of data science. We hope to provide a brainstorming event for relevant researchers in early 2023.
Learn More About the Team’s Work Here: https://sites.gatech.edu/xiaoming-huo/
Sep. 15, 2022

When Alexandria Sweeny, better known as Alex, considered what she wanted to accomplish before graduating from Drew Charter School, the then high school junior set two goals: complete her engineering internship and make a positive impact.
She did both while strengthening her coding knowledge during her time as a camper and mentor at the Seth Bonder Camp in Computational and Data Science for Engineering (SBC).
“I did it when it was fully virtual, and it was definitely an experience,” said Sweeny who spent a week being introduced to computing and data science where she performed virtual activities, last June.
The camp, which is offered either as an online course or on-campus summer camp at Georgia Tech, is designed to build students’ problem-solving and analytical skills while furthering their interest in computer science as a potential career. It is also part of AI4OPT’s mission to inspire young Georgians to pursue STEM (science, technology, engineering and mathematics).
AI4OPT hosted its first in-person summer camp at Georgia Tech in June. The camp brought together 60 students from schools across Georgia including Drew Charter, Banneker High School, and Westlake High School.
Sweeny was asked to return to this particular camp—but this time, as a mentor.
“Of course, I said yes, because it was something fun that I could do over the summer preparing for college without it being too hefty,” said Sweeny. “It was something that I felt prepared for from attending the camp.”
Responses like Sweeny’s motivates SBC Site Managers like Reem Khir to introduce more bright minds to the camp centered around computer programming logic, programming language for AI, and teamwork.
“We expose them [high school students] to certain types of education areas like Twitter analysis, how to solve a sudoku, and even computational biology, if they wanted to consider a career in biology,” said Khir, who joined the camp last year to help students with assignments. This year, she took on even bigger leadership role by maintaining and observing two camps and facilitating 50 students and seven teaching assistants (TAs). She worked under a ‘student to student and student to TA’ interactive structure so that each participant took away a useful skill in data science.
“It’s the time where high school students start forming opinions and decisions about the career path they want to pursue,” said Khir. “The steppingstone is their college education, and we can help students in that period.”
AI4OPT Will Acquire and Advance Seth Bonder Camp
AI4OPT is working to adopt a short-term system used to track students after the camp. The institute wants to build up the system to see majors, colleges, and career paths each student has vowed to pursue before they head off to college or the workforce.
“This is a critical period for students,” said Khir. “It’s a time where students start thinking about a major for college and later impacting the next 20 or 30 years of their life. Being a part of that is very unique in terms of creating a positive influence in the next generation.”
AI4OPT is taking the lead over the SBC to offer the initiative more organizational support as the program has seen tremendous growth and has become a much broader initiative. The Seth Bonder Foundation, which first introduced the camp to those ages 10-18, will continue to fund the camp now more targeted towards high school students interested in engineering, but do not have access to computer science and/or data science in their middle and high schools.
“A lot of the different communities are not exposed to this and may never see this opportunity. The Seth Bonder Camp exposes high school students to AI opportunities and gives them skills to successfully enter the field of STEM with confidence,” said Professor Pascal Van Hentenryck, who’s brought his data sciences skills and knowledge to Georgia Tech and leads both AI4OPT and the SBC.
AI4OPT is in transition to lead the SBC to offer more organizational support as the program sees tremendous growth. The research Institute will expand the longitudinal camps to engage middle and high school students in these topics, while also bringing AI education and research programs to HBCU’s and Hispanic-serving colleges throughout the nation, addressing the widening gap in job opportunities.
Though Sweeny has transitioned away from coding and transcended into research, she never stopped setting goals even now as a first-year biomedical engineering major at Georgia Tech.
“Do anything you can to take it [the SBC] even if you don't want to go into coding,” said Sweeny. “It is a good way to meet new people learn new skills, it is something that you don't necessarily have to have a love for coding to have to do it.”
To learn more about the Seth Bonder Camp in Computational and Data Science for Engineering and to partner with the camp, visit sethbondercamp.isye.gatech.edu.
(Writer’s note: This article is part of a series highlighting AI4OPT members, students, education programs and professional development testimonies.)
Apr. 13, 2022



By Frida Carrera
On Wednesday, April 13th 2022, the Undergraduate Research Opportunities Program (UROP) hosted the 16th annual Spring Undergraduate Research Symposium. UROP’s annual symposium is Georgia Tech’s largest undergraduate research colloquium and allows students to present their research and gain valuable skills and presentation experience. Each year the symposium also presents awards to the top poster and oral presentation from each college and honors the Outstanding Undergraduate Researcher (OUR) from each college. And with over 40 oral presentations and nearly 90 poster presentations, this year’s symposium proved to be another success for UROP and Georgia Tech.
This year the symposium was held in Exhibition Hall and opened with an introduction and keynote address to students, faculty, and other non-presenters. Shortly after, the event moved into the poster presentations segment where undergraduate students displayed their research to judges, faculty, and other attendees. The oral presentations followed soon after and gave student researchers the opportunity to go more in-depth with their research and findings and answer any questions the judges and attendees had. To end the event, sponsoring colleges and departments recognized Outstanding Undergraduate Researchers from their respective colleges. Additionally, the symposium judges were tasked with selecting the top student researchers having exceptional poster and oral presentations.
Any Georgia Tech undergraduate student interested in presenting their research is encouraged to apply for future symposiums and to build on research presentation skills, connect with other undergraduate researchers and faculty, and the chance to be recognized with awards by members of the Georgia Tech research community. UROP also hosts other research-related events and workshops throughout the school year to assist undergraduate students interested in research and build on their passions!
To view the list of awardees and pictures from the event visit: https://symposium.urop.gatech.edu/awards/
To learn more about undergraduate research at Georgia Tech visit: https://urop.gatech.edu/
Mar. 17, 2022



By Frida Carrera
During the summer of 2021, computer science student Neil Sanghavi and computer science recent grad Ahan Shah, both from Fairfax, VA, reconnected to catch up with one another and discuss the projects they were working on. In doing so they discovered a mutual resolve to create something using innovative technology and solve a problem relating to intellectual property, specifically patents. Both Neil and Ahan had just started to get into crypto trading and realized that NFT technology had more to offer than its collectible aspect. Here the idea of PatentX was created: to use NFT technology to provide utility in an antiquated space that lacked efficiency.
“It is estimated that we have $1 trillion in unused IP in the United States currently. Additionally, it is reported that there is $25.6 billion worth of patent monetization available today. This is why we created PatentX, a blockchain-backed marketplace to facilitate intellectual property transactions. We built this to make sure the little man innovators and entrepreneurs have an outlet to monetize and connect their patents with the world. Not only that, we are creating tools for large businesses, law firms, venture capitals to manage all of their IP on the blockchain that can handle transactions in seconds.”
Neil and Ahan describe their product launch process as a great learning experience and are firm believers that there can never be too much help. They are currently supported by DXPartners and have received help from various mentors and blockchain professionals. They have been able to traverse obstacles and learn about the marketing, finance, and business aspects behind building a startup despite coming from a technical background.
Their vision for PatentX is to disrupt the traditional way intellectual property is being transacted and to become the World’s Next Web3 Patent Office. PatentX will be releasing an NFT collection of the most historic patent innovations this early March and encourage interested individuals to stay tuned for their launch.
To learn more about PatentX visit their social media:
Twitter: @PatentXNFT
Instagram: @PatentX.io
To learn more about student innovation at Georgia Tech visit: https://innovation.cae.gatech.edu/