Mar. 06, 2025

Many communities rely on insights from computer-based models and simulations. This week, a nest of Georgia Tech experts are swarming an international conference to present their latest advancements in these tools, which offer solutions to pressing challenges in science and engineering.
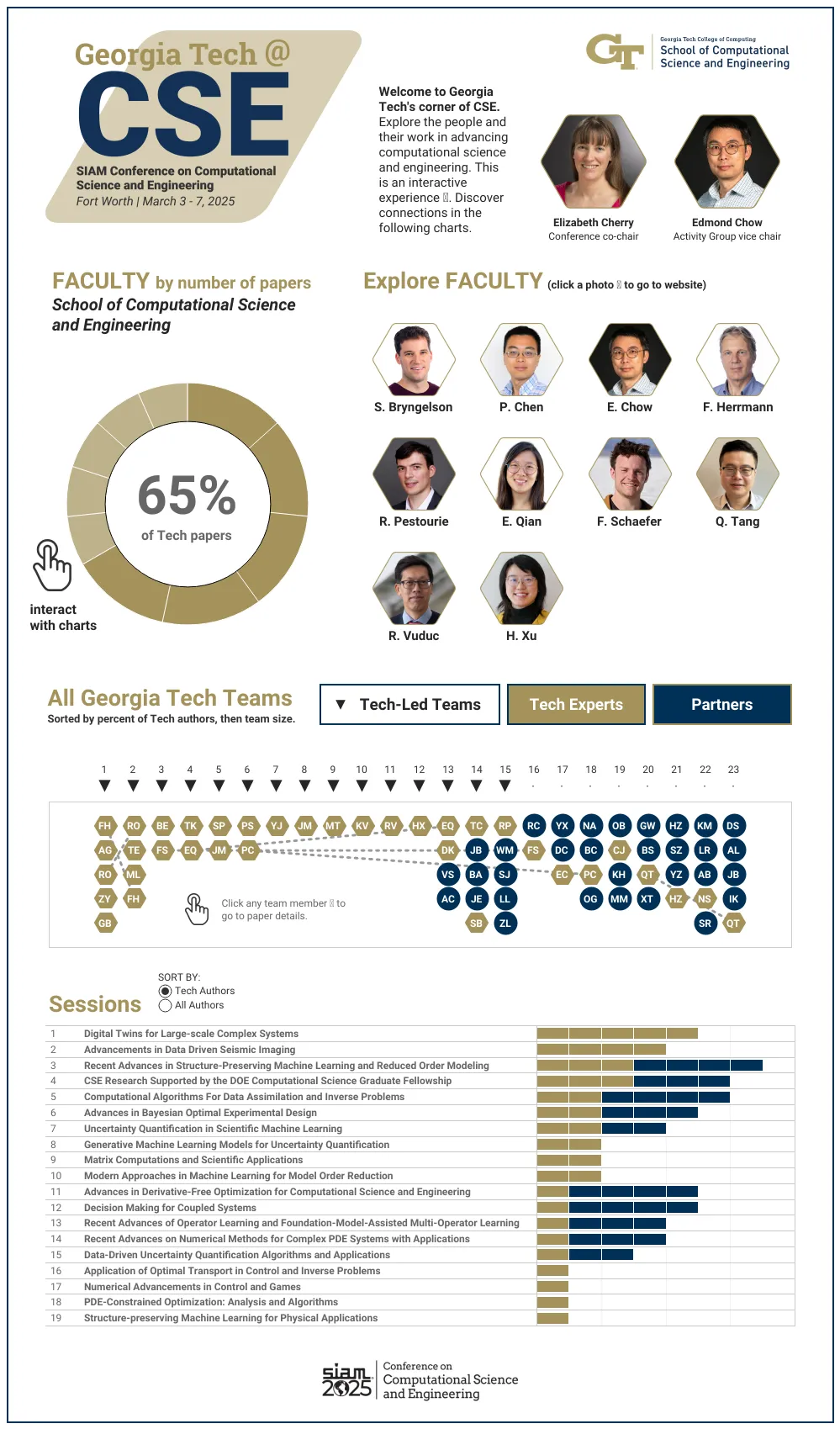
Students and faculty from the School of Computational Science and Engineering (CSE) are leading the Georgia Tech contingent at the SIAM Conference on Computational Science and Engineering (CSE25). The Society of Industrial and Applied Mathematics (SIAM) organizes CSE25, occurring March 3-7 in Fort Worth, Texas.
At CSE25, the School of CSE researchers are presenting papers that apply computing approaches to varying fields, including:
- Experiment designs to accelerate the discovery of material properties
- Machine learning approaches to model and predict weather forecasting and coastal flooding
- Virtual models that replicate subsurface geological formations used to store captured carbon dioxide
- Optimizing systems for imaging and optical chemistry
- Plasma physics during nuclear fusion reactions
[Related: GT CSE at SIAM CSE25 Interactive Graphic]
“In CSE, researchers from different disciplines work together to develop new computational methods that we could not have developed alone,” said School of CSE Professor Edmond Chow.
“These methods enable new science and engineering to be performed using computation.”
CSE is a discipline dedicated to advancing computational techniques to study and analyze scientific and engineering systems. CSE complements theory and experimentation as modes of scientific discovery.
Held every other year, CSE25 is the primary conference for the SIAM Activity Group on Computational Science and Engineering (SIAG CSE). School of CSE faculty serve in key roles in leading the group and preparing for the conference.
In December, SIAG CSE members elected Chow to a two-year term as the group’s vice chair. This election comes after Chow completed a term as the SIAG CSE program director.
School of CSE Associate Professor Elizabeth Cherry has co-chaired the CSE25 organizing committee since the last conference in 2023. Later that year, SIAM members reelected Cherry to a second, three-year term as a council member at large.
At Georgia Tech, Chow serves as the associate chair of the School of CSE. Cherry, who recently became the associate dean for graduate education of the College of Computing, continues as the director of CSE programs.
“With our strong emphasis on developing and applying computational tools and techniques to solve real-world problems, researchers in the School of CSE are well positioned to serve as leaders in computational science and engineering both within Georgia Tech and in the broader professional community,” Cherry said.
Georgia Tech’s School of CSE was first organized as a division in 2005, becoming one of the world’s first academic departments devoted to the discipline. The division reorganized as a school in 2010 after establishing the flagship CSE Ph.D. and M.S. programs, hiring nine faculty members, and attaining substantial research funding.
Ten School of CSE faculty members are presenting research at CSE25, representing one-third of the School’s faculty body. Of the 23 accepted papers written by Georgia Tech researchers, 15 originate from School of CSE authors.
The list of School of CSE researchers, paper titles, and abstracts includes:
Bayesian Optimal Design Accelerates Discovery of Material Properties from Bubble Dynamics
Postdoctoral Fellow Tianyi Chu, Joseph Beckett, Bachir Abeid, and Jonathan Estrada (University of Michigan), Assistant Professor Spencer Bryngelson
[Abstract]
Latent-EnSF: A Latent Ensemble Score Filter for High-Dimensional Data Assimilation with Sparse Observation Data
Ph.D. student Phillip Si, Assistant Professor Peng Chen
[Abstract]
A Goal-Oriented Quadratic Latent Dynamic Network Surrogate Model for Parameterized Systems
Yuhang Li, Stefan Henneking, Omar Ghattas (University of Texas at Austin), Assistant Professor Peng Chen
[Abstract]
Posterior Covariance Structures in Gaussian Processes
Yuanzhe Xi (Emory University), Difeng Cai (Southern Methodist University), Professor Edmond Chow
[Abstract]
Robust Digital Twin for Geological Carbon Storage
Professor Felix Herrmann, Ph.D. student Abhinav Gahlot, alumnus Rafael Orozco (Ph.D. CSE-CSE 2024), alumnus Ziyi (Francis) Yin (Ph.D. CSE-CSE 2024), and Ph.D. candidate Grant Bruer
[Abstract]
Industry-Scale Uncertainty-Aware Full Waveform Inference with Generative Models
Rafael Orozco, Ph.D. student Tuna Erdinc, alumnus Mathias Louboutin (Ph.D. CS-CSE 2020), and Professor Felix Herrmann
[Abstract]
Optimizing Coupled Systems: Insights from Co-Design Imaging and Optical Chemistry
Assistant Professor Raphaël Pestourie, Wenchao Ma and Steven Johnson (MIT), Lu Lu (Yale University), Zin Lin (Virginia Tech)
[Abstract]
Multifidelity Linear Regression for Scientific Machine Learning from Scarce Data
Assistant Professor Elizabeth Qian, Ph.D. student Dayoung Kang, Vignesh Sella, Anirban Chaudhuri and Anirban Chaudhuri (University of Texas at Austin)
[Abstract]
LyapInf: Data-Driven Estimation of Stability Guarantees for Nonlinear Dynamical Systems
Ph.D. candidate Tomoki Koike and Assistant Professor Elizabeth Qian
[Abstract]
The Information Geometric Regularization of the Euler Equation
Alumnus Ruijia Cao (B.S. CS 2024), Assistant Professor Florian Schäfer
[Abstract]
Maximum Likelihood Discretization of the Transport Equation
Ph.D. student Brook Eyob, Assistant Professor Florian Schäfer
[Abstract]
Intelligent Attractors for Singularly Perturbed Dynamical Systems
Daniel A. Serino (Los Alamos National Laboratory), Allen Alvarez Loya (University of Colorado Boulder), Joshua W. Burby, Ioannis G. Kevrekidis (Johns Hopkins University), Assistant Professor Qi Tang (Session Co-Organizer)
[Abstract]
Accurate Discretizations and Efficient AMG Solvers for Extremely Anisotropic Diffusion Via Hyperbolic Operators
Golo Wimmer, Ben Southworth, Xianzhu Tang (LANL), Assistant Professor Qi Tang
[Abstract]
Randomized Linear Algebra for Problems in Graph Analytics
Professor Rich Vuduc
[Abstract]
Improving Spgemm Performance Through Reordering and Cluster-Wise Computation
Assistant Professor Helen Xu
[Abstract]
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Feb. 24, 2025
 and Kevin Ge (top), both 2023 graduates from the George W. Woodruff School of Mechanical Engineering, and founders of CADMUS Health Analytics. Left, Greer loading a stretcher after dropping a patient off.</p>")
Bradford “Brad” Greer (bottom) and Kevin Ge (top), both 2023 graduates from the George W. Woodruff School of Mechanical Engineering, and founders of CADMUS Health Analytics. Left, Greer loading a stretcher after dropping a patient off.
Bradford “Brad” Greer (bottom) and Kevin Ge (top), both 2023 graduates from the George W. Woodruff School of Mechanical Engineering, have taken their startup, CADMUS Health Analytics, from a classroom project to a promising health tech company. In 2023, CADMUS was accepted into the CREATE-X Startup Launch program. Over the 12-week accelerator, CADMUS made significant strides, and program mentors provided expert guidance, helping the team focus their direction based on real-world needs. Their partnership with Northeast Georgia Health System (NGHS) was a direct result of connections made at Startup Launch’s Demo Day.
How did you first hear about CREATE-X?
We did the CREATE-X Capstone with an initial team of seven people, later transitioning to Startup Launch in the summer. Capstone required a hardware product, but for several reasons, we pivoted to software. By that point, we already had a grasp on the problem that we were working on but didn't have the resources to start working on a large hardware product.
Why did you decide to pursue your startup?
One of our close buddies was an emergency medical technician (EMT), and we also had family connections to EMTs. When we were doing our customer interviews, we found out that Emergency Medical Services (EMS) had multiple problems that we thought we'd like to work on and that were more accessible than the broader medical technology industry.
What was Startup Launch like for you?
Startup Launch seemed to transition pretty seamlessly from the Capstone course. We came to understand our customer base and technical development better, and the program also led us through the process of starting and running a company. I found it very interesting and learned a whole lot.
What was the most difficult challenge in Startup Launch?
Definitely customer interviews. We spent a lot of time on that in the Startup Launch classes. It's a difficult thing to have a good takeaway from a customer interview without getting the conversation confused and being misled. We didn't mention the product, or we tried to wait as long as possible before mentioning the product, so as to not bias or elicit general, positive messaging from interviewees.
We're working in EMS, and the products we are building affect healthcare. EMS is a little informal and a little rough around the edges. Many times, people don't want to admit how bad their practices are, which can easily lead to us collecting bad data.
What affected you the most from Startup Launch?
The resources at our fingertips. When we were running around, it was nice to be able to consult with our mentor. It's great having someone around with the know-how and who's been through it themselves. I revisit concepts a lot.
How did the partnership with NGHS come about?
During Demo Day, we met a Georgia state representative. He put us in touch with NGHS. They were looking for companies to work with through their venture arm, Northeast Georgia Health Ventures(NGHV), so we pitched our product to them. They liked it, and then we spent a long time banging out the details. We worked with John Lanza, who's a friend of CREATE-X. He helped us find a corporate lawyer to read over the stuff we were signing. It took a little back and forth to get everything in place, but in September of last year, we finally kicked it off.
What’s the partnership like?
We provide them a license to our product, have weekly meetings where experts give feedback on the performance of the system, and then we make incremental changes to align the product with customer needs.
While we're in this developmental phase, we're kind of keeping it under wraps until we make sure it’s fully ready. Our focus is primarily on emergent capabilities that NGHS and other EMS agencies are really looking for. Right now, the pilot is set to be a year long, so we're aiming to be ready for a full rollout by the end of the year.
How did you pivot into this other avenue for your product?
EMS does not have many resources. That makes it not a popular space as far as applying emerging technologies. There's only competition in this very one specific vein, which is this central type of software that we plug into, so we're not competing directly with anyone.
EMS agencies, EMTs, and paramedics - the care that they give has to be enabled by a medical doctor. There has to be a doctor linked to the practices that they engage in and the procedures that they do. With the product that we're making now, we want to provide a low-cost, plug-and-play product that'll do everything they need it to do to enable the improvement of patient care.
How are you supporting yourself during this period?
I was paying myself last year, but we're out of money for that, so we're not currently paying for any labor. It's all equity now, but our burn rate outside of that is very low. The revenue we have now easily covers the cost of operating our system. I'm also working part-time as an EMT now. This helps cover my own costs while also deepening my understanding of the problems we are working on.
How are you balancing your work?
It's hard to balance. There's always stuff to do. I just do what I can, and the pace of development is good enough for the pilot. Every week, and then every month, Kevin and I sit down and analyze the rate at which we're working and developing. Then we project out. We're confident that we're developing at a rate that'll have us in a good spot by September when the pilot ends.
What’s a short-term goal for your startup?
Kevin and I are trying to reach back out and see if there's anyone interested in joining and playing a major role. The timing would be such that they start working a little bit after the spring semester ends. I think most Georgia Tech students would meet the role requirements, but generally, JavaScript and Node experience as well as a diverse background would be good.
Where do you want your startup to be in the next five years?
I want to have a very well-designed system. Despite all the vectors I’m talking about for our products, everything should be part of the same system in place at EMS agencies anywhere. I just want it to be a resource that EMS can use broadly.
Another issue in EMS is standards. Even the standards that are in place now aren’t broadly accessible. I think that these new AI tools can do a lot to bridge the lack of understanding of documentation, measures, and standards and make all of that more accessible for the layperson.
What advice would you give students interested in entrepreneurship?
Make sure the idea that you're working on, and the business model, is something you enjoy outside of its immediate viability. I think that's really what's helped me persevere. It's my enjoyment of the project that's allowed me to continue and be motivated. So, start there and then work your way forward.
Are there any books, podcasts, or resources you would recommend to budding entrepreneurs?
I’d recommend Influence to prepare for marketing. I have no background in marketing at all. Influence is a nice science-based primer for marketing.
I reread How to Win Friends and Influence People. I am not sure how well I'm implementing the concepts day-to-day, but I think most of the main points of that book are solid.
I also read The Mom Test. It's a good reference, a short text on customer interviews.
Want to build your own startup?
Georgia Tech students, faculty, researchers, and alumni interested in developing their own startups are encouraged to apply to CREATE-X's Startup Launch, which provides $5,000 in optional seed funding and $150,000 in in-kind services, mentorship, entrepreneurial workshops, networking events, and resources to help build and scale startups. The program culminates in Demo Day, where teams present their startups to potential investors. The deadline to apply for Startup Launch is Monday, March 17. Spots are limited. Apply now.
News Contact
Breanna Durham
Marketing Strategist
Feb. 26, 2025


In today's data-driven world, supply chain professionals and business leaders are increasingly required to leverage analytics to drive decision-making. As companies invest in building data capabilities, one critical question emerges: Which programming language is best for supply chain analytics—Python or R?
Both Python and R have strong footholds in the analytics space, each with unique advantages. However, industry trends suggest a growing shift toward Python as the dominant tool for data science, machine learning, and enterprise applications. While R remains valuable in specific statistical and academic contexts, businesses must carefully assess which language aligns best with their analytics goals and workforce development strategies.
This article explores the strengths of each language and provides guidance for industry professionals looking to make informed decisions about which to prioritize for their teams.
Why Python Is Gaining Industry-Wide Adoption
1. Versatility and Scalability for Business Applications
Python has evolved into a comprehensive tool that extends beyond traditional analytics into automation, optimization, artificial intelligence, and supply chain modeling. Its key advantages include:
- Scalability: Python handles large-scale data processing and integrates seamlessly with cloud computing environments.
- Machine Learning and AI: Python’s ecosystem includes powerful machine learning libraries like scikit-learn, TensorFlow, and PyTorch.
- Integration Capabilities: Python works well with databases, APIs, and ERP systems, embedding analytics into operational workflows.
2. Workforce Readiness and Talent Development
From a talent perspective, Python is becoming the preferred programming language for data science and analytics roles. Surveys indicate that Python is used in 67% to 90% of analytics-related jobs, making it a crucial skill for professionals. Employers benefit from:
- A larger talent pool of Python-proficient professionals.
- A lower barrier to entry for new employees learning data analytics.
- The ability to streamline analytics processes across different functions.
3. Industry Adoption in Supply Chain Analytics
Python is widely adopted in logistics, manufacturing, and supply chain optimization due to its ability to handle:
- Demand forecasting and inventory optimization.
- Network modeling and simulation.
- Automation of data pipelines and reporting.
- Predictive maintenance and anomaly detection.
Why R Still Has a Place in Analytics
Despite Python’s widespread adoption, R remains a valuable tool in certain business contexts, particularly in statistical modeling and research applications. R’s strengths include:
- Advanced Statistical Analysis: R was designed for statisticians and remains a leader in econometrics and experimental design.
- Robust Visualization Capabilities: Packages like ggplot2 and Shiny make R a preferred choice for creating high-quality visualizations.
- Adoption in Public Sector and Academic Research: Many government agencies and research institutions continue to rely on R.
Strategic Considerations: Choosing Between Python and R
1. Business Needs and Analytics Maturity
- For companies focused on predictive analytics, automation, and AI, Python is the best choice.
- For organizations conducting deep statistical research or working with legacy R code, maintaining some R capabilities may be necessary.
2. Workforce Training and Skill Development
- Companies investing in analytics training should prioritize Python to align with industry trends.
- If statistical expertise is a core requirement, R may still play a supporting role in niche applications.
3. Tool and System Integration
- Python integrates more seamlessly with enterprise software, making it easier to operationalize analytics.
- R is often more specialized and may require additional effort to connect with business intelligence platforms.
4. Future Trends and Technology Evolution
- Python’s rapid growth suggests it will continue to dominate in analytics and AI.
- While R remains relevant, its role is becoming more specialized.
Final Thoughts: A Pragmatic Approach to Analytics Development
For most organizations, Python represents the future of analytics, offering the broadest capabilities, strongest industry adoption, and easiest integration into enterprise systems. However, R remains useful in specialized statistical applications and legacy environments.
A balanced approach might involve training teams in Python as the primary analytics language while maintaining an awareness of R for niche use cases. The key takeaway for business leaders is not just about choosing a programming language but ensuring their teams develop strong analytical problem-solving skills that transcend specific tools.
By strategically aligning analytics capabilities with business goals, organizations can build a more data-driven, adaptable, and future-ready workforce.
Nov. 11, 2024



A first-of-its-kind algorithm developed at Georgia Tech is helping scientists study interactions between electrons. This innovation in modeling technology can lead to discoveries in physics, chemistry, materials science, and other fields.
The new algorithm is faster than existing methods while remaining highly accurate. The solver surpasses the limits of current models by demonstrating scalability across chemical system sizes ranging from large to small.
Computer scientists and engineers benefit from the algorithm’s ability to balance processor loads. This work allows researchers to tackle larger, more complex problems without the prohibitive costs associated with previous methods.
Its ability to solve block linear systems drives the algorithm’s ingenuity. According to the researchers, their approach is the first known use of a block linear system solver to calculate electronic correlation energy.
The Georgia Tech team won’t need to travel far to share their findings with the broader high-performance computing community. They will present their work in Atlanta at the 2024 International Conference for High Performance Computing, Networking, Storage and Analysis (SC24).
[MICROSITE: Georgia Tech at SC24]
“The combination of solving large problems with high accuracy can enable density functional theory simulation to tackle new problems in science and engineering,” said Edmond Chow, professor and associate chair of Georgia Tech’s School of Computational Science and Engineering (CSE).
Density functional theory (DFT) is a modeling method for studying electronic structure in many-body systems, such as atoms and molecules.
An important concept DFT models is electronic correlation, the interaction between electrons in a quantum system. Electron correlation energy is the measure of how much the movement of one electron is influenced by presence of all other electrons.
Random phase approximation (RPA) is used to calculate electron correlation energy. While RPA is very accurate, it becomes computationally more expensive as the size of the system being calculated increases.
Georgia Tech’s algorithm enhances electronic correlation energy computations within the RPA framework. The approach circumvents inefficiencies and achieves faster solution times, even for small-scale chemical systems.
The group integrated the algorithm into existing work on SPARC, a real-space electronic structure software package for accurate, efficient, and scalable solutions of DFT equations. School of Civil and Environmental Engineering Professor Phanish Suryanarayana is SPARC’s lead researcher.
The group tested the algorithm on small chemical systems of silicon crystals numbering as few as eight atoms. The method achieved faster calculation times and scaled to larger system sizes than direct approaches.
“This algorithm will enable SPARC to perform electronic structure calculations for realistic systems with a level of accuracy that is the gold standard in chemical and materials science research,” said Suryanarayana.
RPA is expensive because it relies on quartic scaling. When the size of a chemical system is doubled, the computational cost increases by a factor of 16.
Instead, Georgia Tech’s algorithm scales cubically by solving block linear systems. This capability makes it feasible to solve larger problems at less expense.
Solving block linear systems presents a challenging trade-off in solving different block sizes. While larger blocks help reduce the number of steps of the solver, using them demands higher computational cost per step on computer processors.
Tech’s solution is a dynamic block size selection solver. The solver allows each processor to independently select block sizes to calculate. This solution further assists in scaling, and improves processor load balancing and parallel efficiency.
“The new algorithm has many forms of parallelism, making it suitable for immense numbers of processors,” Chow said. “The algorithm works in a real-space, finite-difference DFT code. Such a code can scale efficiently on the largest supercomputers.”
Georgia Tech alumni Shikhar Shah (Ph.D. CSE 2024), Hua Huang (Ph.D. CSE 2024), and Ph.D. student Boqin Zhang led the algorithm’s development. The project was the culmination of work for Shah and Huang, who completed their degrees this summer. John E. Pask, a physicist at Lawrence Livermore National Laboratory, joined the Tech researchers on the work.
Shah, Huang, Zhang, Suryanarayana, and Chow are among more than 50 students, faculty, research scientists, and alumni affiliated with Georgia Tech who are scheduled to give more than 30 presentations at SC24. The experts will present their research through papers, posters, panels, and workshops.
SC24 takes place Nov. 17-22 at the Georgia World Congress Center in Atlanta.
“The project’s success came from combining expertise from people with diverse backgrounds ranging from numerical methods to chemistry and materials science to high-performance computing,” Chow said.
“We could not have achieved this as individual teams working alone.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Oct. 21, 2024
</p>")
A pair of Smarticle robots from the lab of Prof. Dan Goldman. Earlier research from his group observed the arise of order in active matter from the physics of low rattling. (Photo Credit: Christa M. Ernst)
If you’ve ever watched a large flock of birds on the wing, moving across the sky like a cloud with various shapes and directional changes appearing from seeming chaos, or the maneuvers of an ant colony forming bridges and rafts to escape floods, you’ve been observing what scientists call self-organization. What may not be as obvious is that self-organization occurs throughout the natural world, including bacterial colonies, protein complexes, and hybrid materials. Understanding and predicting self-organization, especially in systems that are out of equilibrium, like living things, is an enduring goal of statistical physics.
This goal is the motivation behind a recently introduced principle of physics called rattling, which posits that systems with sufficiently “messy” dynamics organize into what researchers refer to as low rattling states. Although the principle has proved accurate for systems of robot swarms, it has been too vague to be more broadly tested, and it has been unclear exactly why it works and to what other systems it should apply.
Dana Randall, a professor in the School of Computer Science, and Jacob Calvert, a postdoctoral fellow at the Institute for Data Engineering and Science, have formulated a theory of rattling that answers these fundamental questions. Their paper, “A Local-Global Principle for Nonequilibrium Steady States,” published last week in Proceedings of the National Academy of Sciences, characterizes how rattling is related to the amount of time that a system spends in a state. Their theory further identifies the classes of systems for which rattling explains self-organization.
When we first heard about rattling from physicists, it was very hard to believe it could be true. Our work grew out of a desire to understand it ourselves. We found that the idea at its core is surprisingly simple and holds even more broadly than the physicists guessed.
Dana Randall Professor, School of Computer Science & Adjunct Professor, School of Mathematics
Georgia Institute of Technology
Beyond its basic scientific importance, the work can be put to immediate use to analyze models of phenomena across scientific domains. Additionally, experimentalists seeking organization within a nonequilibrium system may be able to induce low rattling states to achieve their desired goal. The duo thinks the work will be valuable in designing microparticles, robotic swarms, and new materials. It may also provide new ways to analyze and predict collective behaviors in biological systems at the micro and nanoscale.
The preceding material is based on work supported by the Army Research Office under award ARO MURI Award W911NF-19-1-0233 and by the National Science Foundation under grant CCF-2106687. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the sponsoring agencies.
Jacob Calvert and Dana Randall. A local-global principle for nonequilibrium steady states. Proceedings of the National Academy of Sciences, 121(42):e2411731121, 2024.
Sep. 19, 2024



A new algorithm tested on NASA’s Perseverance Rover on Mars may lead to better forecasting of hurricanes, wildfires, and other extreme weather events that impact millions globally.
Georgia Tech Ph.D. student Austin P. Wright is first author of a paper that introduces Nested Fusion. The new algorithm improves scientists’ ability to search for past signs of life on the Martian surface.
In addition to supporting NASA’s Mars 2020 mission, scientists from other fields working with large, overlapping datasets can use Nested Fusion’s methods toward their studies.
Wright presented Nested Fusion at the 2024 International Conference on Knowledge Discovery and Data Mining (KDD 2024) where it was a runner-up for the best paper award. KDD is widely considered the world's most prestigious conference for knowledge discovery and data mining research.
“Nested Fusion is really useful for researchers in many different domains, not just NASA scientists,” said Wright. “The method visualizes complex datasets that can be difficult to get an overall view of during the initial exploratory stages of analysis.”
Nested Fusion combines datasets with different resolutions to produce a single, high-resolution visual distribution. Using this method, NASA scientists can more easily analyze multiple datasets from various sources at the same time. This can lead to faster studies of Mars’ surface composition to find clues of previous life.
The algorithm demonstrates how data science impacts traditional scientific fields like chemistry, biology, and geology.
Even further, Wright is developing Nested Fusion applications to model shifting climate patterns, plant and animal life, and other concepts in the earth sciences. The same method can combine overlapping datasets from satellite imagery, biomarkers, and climate data.
“Users have extended Nested Fusion and similar algorithms toward earth science contexts, which we have received very positive feedback,” said Wright, who studies machine learning (ML) at Georgia Tech.
“Cross-correlational analysis takes a long time to do and is not done in the initial stages of research when patterns appear and form new hypotheses. Nested Fusion enables people to discover these patterns much earlier.”
Wright is the data science and ML lead for PIXLISE, the software that NASA JPL scientists use to study data from the Mars Perseverance Rover.
Perseverance uses its Planetary Instrument for X-ray Lithochemistry (PIXL) to collect data on mineral composition of Mars’ surface. PIXL’s two main tools that accomplish this are its X-ray Fluorescence (XRF) Spectrometer and Multi-Context Camera (MCC).
When PIXL scans a target area, it creates two co-aligned datasets from the components. XRF collects a sample's fine-scale elemental composition. MCC produces images of a sample to gather visual and physical details like size and shape.
A single XRF spectrum corresponds to approximately 100 MCC imaging pixels for every scan point. Each tool’s unique resolution makes mapping between overlapping data layers challenging. However, Wright and his collaborators designed Nested Fusion to overcome this hurdle.
In addition to progressing data science, Nested Fusion improves NASA scientists' workflow. Using the method, a single scientist can form an initial estimate of a sample’s mineral composition in a matter of hours. Before Nested Fusion, the same task required days of collaboration between teams of experts on each different instrument.
“I think one of the biggest lessons I have taken from this work is that it is valuable to always ground my ML and data science problems in actual, concrete use cases of our collaborators,” Wright said.
“I learn from collaborators what parts of data analysis are important to them and the challenges they face. By understanding these issues, we can discover new ways of formalizing and framing problems in data science.”
Wright presented Nested Fusion at KDD 2024, held Aug. 25-29 in Barcelona, Spain. KDD is an official special interest group of the Association for Computing Machinery. The conference is one of the world’s leading forums for knowledge discovery and data mining research.
Nested Fusion won runner-up for the best paper in the applied data science track, which comprised of over 150 papers. Hundreds of other papers were presented at the conference’s research track, workshops, and tutorials.
Wright’s mentors, Scott Davidoff and Polo Chau, co-authored the Nested Fusion paper. Davidoff is a principal research scientist at the NASA Jet Propulsion Laboratory. Chau is a professor at the Georgia Tech School of Computational Science and Engineering (CSE).
“I was extremely happy that this work was recognized with the best paper runner-up award,” Wright said. “This kind of applied work can sometimes be hard to find the right academic home, so finding communities that appreciate this work is very encouraging.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Aug. 30, 2024

The Cloud Hub, a key initiative of the Institute for Data Engineering and Science (IDEaS) at Georgia Tech, recently concluded a successful Call for Proposals focused on advancing the field of Generative Artificial Intelligence (GenAI). This initiative, made possible by a generous gift funding from Microsoft, aims to push the boundaries of GenAI research by supporting projects that explore both foundational aspects and innovative applications of this cutting-edge technology.
Call for Proposals: A Gateway to Innovation
Launched in early 2024, the Call for Proposals invited researchers from across Georgia Tech to submit their innovative ideas on GenAI. The scope was broad, encouraging proposals that spanned foundational research, system advancements, and novel applications in various disciplines, including arts, sciences, business, and engineering. A special emphasis was placed on projects that addressed responsible and ethical AI use.
The response from the Georgia Tech research community was overwhelming, with 76 proposals submitted by teams eager to explore this transformative technology. After a rigorous selection process, eight projects were selected for support. Each awarded team will also benefit from access to Microsoft’s Azure cloud resources..
Recognizing Microsoft’s Generous Contribution
This successful initiative was made possible through the generous support of Microsoft, whose contribution of research resources has empowered Georgia Tech researchers to explore new frontiers in GenAI. By providing access to Azure’s advanced tools and services, Microsoft has played a pivotal role in accelerating GenAI research at Georgia Tech, enabling researchers to tackle some of the most pressing challenges and opportunities in this rapidly evolving field.
Looking Ahead: Pioneering the Future of GenAI
The awarded projects, set to commence in Fall 2024, represent a diverse array of research directions, from improving the capabilities of large language models to innovative applications in data management and interdisciplinary collaborations. These projects are expected to make significant contributions to the body of knowledge in GenAI and are poised to have a lasting impact on the industry and beyond.
IDEaS and the Cloud Hub are committed to supporting these teams as they embark on their research journeys. The outcomes of these projects will be shared through publications and highlighted on the Cloud Hub web portal, ensuring visibility for the groundbreaking work enabled by this initiative.
Congratulations to the Fall 2024 Winners
- Annalisa Bracco | EAS "Modeling the Dispersal and Connectivity of Marine Larvae with GenAI Agents" [proposal co-funded with support from the Brook Byers Institute for Sustainable Systems]
- Yunan Luo | CSE “Designing New and Diverse Proteins with Generative AI”
- Kartik Goyal | IC “Generative AI for Greco-Roman Architectural Reconstruction: From Partial Unstructured Archaeological Descriptions to Structured Architectural Plans”
- Victor Fung | CSE “Intelligent LLM Agents for Materials Design and Automated Experimentation”
- Noura Howell | LMC “Applying Generative AI for STEM Education: Supporting AI literacy and community engagement with marginalized youth”
- Neha Kumar | IC “Towards Responsible Integration of Generative AI in Creative Game Development”
- Maureen Linden | Design “Best Practices in Generative AI Used in the Creation of Accessible Alternative Formats for People with Disabilities”
- Surya Kalidindi | ME & MSE “Accelerating Materials Development Through Generative AI Based Dimensionality Expansion Techniques”
- Tuo Zhao | ISyE “Adaptive and Robust Alignment of LLMs with Complex Rewards”
News Contact
Christa M. Ernst - Research Communications Program Manager
christa.ernst@research.gatech.edu
Jul. 23, 2024
.</p>")
An early rendering of the main expanded research area at the Advanced Manufacturing Pilot Facility (Credit: Lord Aeck Sargent).
.</p>")
An early rendering of the main expanded research area at the Advanced Manufacturing Pilot Facility (Credit: Lord Aeck Sargent).
When it comes to manufacturing innovation, the “valley of death” — the gap between the lab and the industry floor where even the best discoveries often get lost — looms large.
“An individual faculty’s lab focuses on showing the innovation or the new science that they discovered,” said Aaron Stebner, professor and Eugene C. Gwaltney Jr. Chair in Manufacturing in the George W. Woodruff School of Mechanical Engineering. “At that point, the business case hasn't been made for the technology yet — there's no testing on an industrial system to know if it breaks or if it scales up. A lot of innovation and scientific discovery dies there.”
The Georgia Tech Manufacturing Institute (GTMI) launched the Advanced Manufacturing Pilot Facility (AMPF) in 2017 to help bridge that gap.
Now, GTMI is breaking ground on an extensive expansion to bring new capabilities in automation, artificial intelligence, and data management to the facility.
“This will be the first facility of this size that's being intentionally designed to enable AI to perform research and development in materials and manufacturing at the same time,” said Stebner, “setting up GTMI as not just a leader in Georgia, but a leader in automation and AI in manufacturing across the country.”
AMPF: A Catalyst for Collaboration
Located just north of Georgia Tech’s main campus, APMF is a 20,000-square-foot facility serving as a teaching laboratory, technology test bed, and workforce development space for manufacturing innovations.
“The pilot facility,” says Stebner, “is meant to be a place where stakeholders in academic research, government, industry, and workforce development can come together and develop both the workforce that is needed for future technologies, as well as mature, de-risk, and develop business cases for new technologies — proving them out to the point where it makes sense for industry to pick them up.”
In addition to serving as the flagship facility for GTMI research and the state’s Georgia AIM (Artificial Intelligence in Manufacturing) project, the AMPF is a user facility accessible to Georgia Tech’s industry partners as well as the Institute’s faculty, staff, and students.
“We have all kinds of great capabilities and technologies, plus staff that can train students, postdocs, and faculty on how to use them,” said Stebner, who also serves as co-director of the GTMI-affiliated Georgia AIM project. “It creates a unique asset for Georgia Tech faculty, staff, and students.”
Bringing AI and Automation to the Forefront
The renovation of APMF is a key component of the $65 million grant, awarded to Georgia Tech by the U.S. Department of Commerce’s Economic Development Administration in 2022, which gave rise to the Georgia AIM project. With over $23 million in support from Georgia AIM, the improved facility will feature new workforce training programs, personnel, and equipment.
Set to complete in Spring 2026, the Institute’s investment of $16 million supports construction that will roughly triple the size of the facility — and work to address a major roadblock for incorporating AI and automation into manufacturing practices: data.
“There’s a lot of work going on across the world in using machine learning in engineering problems, including manufacturing, but it's limited in scale-up and commercial adoption,” explained Stebner.
Machine learning algorithms have the potential to make manufacturing more efficient, but they need a lot of reliable, repeatable data about the processes and materials involved to be effective. Collecting that data manually is monotonous, costly, and time-consuming.
“The idea is to automate those functions that we need to enable AI and machine learning” in manufacturing, says Stebner. “Let it be a facility where you can imagine new things and push new boundaries and not just be stuck in demonstrating concepts over and over again.”
To make that possible, the expanded facility will couple AI and data management with robotic automation.
“We're going to be able to demonstrate automation from the very beginning of our process all the way through the entire ecosystem of manufacturing,” said Steven Sheffield, GTMI’s senior assistant director of research operations.
“This expansion — no one else has done anything like it,” added Steven Ferguson, principal research scientist with GTMI and managing director of Georgia AIM. “We will have the leading facility for demonstrating what a hyperconnected and AI-driven manufacturing enterprise looks like. We’re setting the stage for Georgia Tech to continue to lead in the manufacturing space for the next decade and beyond.”
News Contact
Audra Davidson
Research Communications Program Manager
Georgia Tech Manufacturing Institute
Apr. 22, 2024

Omar Asensio is Associate Professor at Georgia Institute of Technology and Climate Fellow, Harvard Business School
With new vehicle models being developed by major brands and a growing supply chain, the electric vehicle (EV) revolution seems well underway. But, as consumer purchases of EVs have slowed, car makers have backtracked on planned EV manufacturing investments. A major roadblock to wider EV adoption remains the lack of a fully realized charging infrastructure. At just under 51,000 public charging stations nationwide, and sizeable gaps between urban and rural areas, this inconsistency is a major driver of buyer hesitance.
How do we understand, at a large scale, ways to make it easier for consumers to have confidence in public infrastructure? That is a major issue holding back electrification for many consumer segments.
- Omar Asensio, Associate Professor at Georgia Institute of Technology and Climate Fellow, Harvard Business School | Director, Data Science & Policy Lab
Omar Asensio, associate professor in the School of Public Policy and director of the Data Science and Policy Lab at the Georgia Institute of Technology, and his team have been working to solve this trust issue using the Microsoft CloudHub partnership resources. Asensio is also currently a visiting fellow with the Institute for the Study of Business in Global Society at the Harvard Business School.
The CloudHub partnership gave the Asensio team access to Microsoft’s Azure OpenAI to sift through vast amounts of data collected from different sources to identify relevant connections. Asensio’s team needed to know if AI could understand purchaser sentiment as negative within a population with an internal lingo outside of the general consumer population. Early results yielded little. The team then used specific example data collected from EV enthusiasts to train the AI for a sentiment classification accuracy that now exceeds that of human experts and data parsed from government-funded surveys.
The use of trained AI promises to expedite industry response to consumer sentiment at a much lower cost than previously possible. “What we’re doing with Azure is a lot more scalable,” Asensio said. “We hit a button, and within five to 10 minutes, we had classified all the U.S. data. Then I had my students look at performance in Europe, with urban and non-urban areas. Most recently, we aggregated evidence of stations across East and Southeast Asia, and we used machine learning to translate the data in 72 detected languages.”
We are excited to see how access to compute and AI models is accelerating research and having an impact on important societal issues. Omar's research sheds new light on the gaps in electric vehicle infrastructure and AI enables them to effectively scale their analysis not only in the U.S. but globally.
- Elizabeth Bruce, Director, Technology for Fundamental Rights, Microsoft
Asensio's pioneering work illustrates the interdisciplinary nature of today’s research environment, from machine learning models predicting problems to assisting in improving EV infrastructure. The team is planning on applying the technique to datasets next, to address access concerns and reduce the number of “charging deserts.” The findings could lead to the creation of policies that help in the adoption of EVs in infrastructure-lacking regions for a true automotive electrification revolution and long-term environmental sustainability in the U.S.
- Christa M. Ernst
Source Paper: Reliability of electric vehicle charging infrastructure: A cross-lingual deep learning approach - ScienceDirect
News Contact
Christa M. Ernst
Research Communications Program Manager
Topic Expertise: Robotics | Data Sciences| Semiconductor Design & Fab
Research @ the Georgia Institute of Technology
christa.ernst@research.gatech.edu
Dec. 20, 2023

A new machine learning method could help engineers detect leaks in underground reservoirs earlier, mitigating risks associated with geological carbon storage (GCS). Further study could advance machine learning capabilities while improving safety and efficiency of GCS.
The feasibility study by Georgia Tech researchers explores using conditional normalizing flows (CNFs) to convert seismic data points into usable information and observable images. This potential ability could make monitoring underground storage sites more practical and studying the behavior of carbon dioxide plumes easier.
The 2023 Conference on Neural Information Processing Systems (NeurIPS 2023) accepted the group’s paper for presentation. They presented their study on Dec. 16 at the conference’s workshop on Tackling Climate Change with Machine Learning.
“One area where our group excels is that we care about realism in our simulations,” said Professor Felix Herrmann. “We worked on a real-sized setting with the complexities one would experience when working in real-life scenarios to understand the dynamics of carbon dioxide plumes.”
CNFs are generative models that use data to produce images. They can also fill in the blanks by making predictions to complete an image despite missing or noisy data. This functionality is ideal for this application because data streaming from GCS reservoirs are often noisy, meaning it’s incomplete, outdated, or unstructured data.
The group found in 36 test samples that CNFs could infer scenarios with and without leakage using seismic data. In simulations with leakage, the models generated images that were 96% similar to ground truths. CNFs further supported this by producing images 97% comparable to ground truths in cases with no leakage.
This CNF-based method also improves current techniques that struggle to provide accurate information on the spatial extent of leakage. Conditioning CNFs to samples that change over time allows it to describe and predict the behavior of carbon dioxide plumes.
This study is part of the group’s broader effort to produce digital twins for seismic monitoring of underground storage. A digital twin is a virtual model of a physical object. Digital twins are commonplace in manufacturing, healthcare, environmental monitoring, and other industries.
“There are very few digital twins in earth sciences, especially based on machine learning,” Herrmann explained. “This paper is just a prelude to building an uncertainty aware digital twin for geological carbon storage.”
Herrmann holds joint appointments in the Schools of Earth and Atmospheric Sciences (EAS), Electrical and Computer Engineering, and Computational Science and Engineering (CSE).
School of EAS Ph.D. student Abhinov Prakash Gahlot is the paper’s first author. Ting-Ying (Rosen) Yu (B.S. ECE 2023) started the research as an undergraduate group member. School of CSE Ph.D. students Huseyin Tuna Erdinc, Rafael Orozco, and Ziyi (Francis) Yin co-authored with Gahlot and Herrmann.
NeurIPS 2023 took place Dec. 10-16 in New Orleans. Occurring annually, it is one of the largest conferences in the world dedicated to machine learning.
Over 130 Georgia Tech researchers presented more than 60 papers and posters at NeurIPS 2023. One-third of CSE’s faculty represented the School at the conference. Along with Herrmann, these faculty included Ümit Çatalyürek, Polo Chau, Bo Dai, Srijan Kumar, Yunan Luo, Anqi Wu, and Chao Zhang.
“In the field of geophysics, inverse problems and statistical solutions of these problems are known, but no one has been able to characterize these statistics in a realistic way,” Herrmann said.
“That’s where these machine learning techniques come into play, and we can do things now that you could never do before.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu