Dec. 11, 2025

Ph.D. student Ziqi Zhang has built a career blending machine learning with single-cell biology. His work helps scientists study cellular mechanisms that advance disease research and drug development.
Though decorated with awards and appearances in leading journals, Zhang will achieve his greatest accomplishment tonight at McCamish Pavilion. He will join the Class of 2025 in walking across the stage, receiving diplomas, and graduating from Georgia Tech.
Before he “gets out” of Georgia Tech, we interviewed Zhang to learn more about his Ph.D. journey and where his degree will take him next.
Graduate: Ziqi Zhang
Research Interests: Machine learning, foundational models, cellular mechanisms, single-cell gene sequencing, gene regulatory networks
Education: Ph.D. in Computational Science and Engineering
Faculty Advisor: School of CSE J.Z. Liang Early-Career Associate Professor Xiuwei Zhang
What persuaded you to study at Georgia Tech?
I chose Georgia Tech because it is one of the top engineering institutions in the United States, known for its strength in machine learning and data science. The university offers exceptional research resources and the opportunity to work with leading scholars in my field. Georgia Tech also has very good research infrastructure. The Coda Building is one of the most well-designed and productive research environments I have experienced. Having access to such a space has been a genuine privilege.
How has working on your CSE degree helped you so far in your career?
Working toward my CSE degree has been instrumental in my career development. As an interdisciplinary program, CSE has equipped me with strong computational skills while also deepening my understanding of key application domains. This breadth of training has opened more opportunities during my job and internship searches. In addition, CSE community events, such as HotCSE, the weekly coffee hour, and faculty recruiting activities, have helped me strengthen my scientific communication skills, which are essential for my long-term career growth.
What research project from Georgia Tech are you most proud of?
My favorite research project was scMoMaT, a matrix tri-factorization algorithm for single-cell data integration. I invested a significant amount of time and effort into this work, iterating on the model many times. I’m very proud that it ultimately evolved into a clean, robust, and elegant algorithm.
What advice would you give someone interested in graduate school?
It is important to find an advisor who is supportive and genuinely invested in your career development. A Ph.D. is not an easy journey, and you will inevitably encounter challenges along the way. Having an advisor who can provide thoughtful guidance and dedicated mentorship is one of the most crucial factors in helping you navigate those difficulties.
What is your most favorite memory from Georgia Tech?
CSE’s new student campus visit day every year was one of my favorite times of the year. It was always fun to meet new people, have good food, and enjoy the beautiful view from the Coda rooftop.
What are your plans after graduation?
I plan to keep working in academia after graduation. I’m on the job hunt, currently applying for positions and preparing for interviews.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Dec. 10, 2025


Proteins, including antibodies, hemoglobin, and insulin, power nearly every vital aspect of life. Breakthroughs in protein research are producing vaccines, resilient crops, bioenergy sources, and other innovative technologies.
Despite their importance, most of what scientists know about proteins only comes from a small sample size. This stands in the way of fully understanding how most proteins work and unlocking their full potential.
Georgia Tech’s Yunan Luo believes artificial intelligence (AI) could fill this knowledge gap. The National Science Foundation agrees. Luo is the recipient of an NSF Faculty Early Career Development (CAREER) award.
“So much of biology depends on knowing what proteins do, but decades of research have concentrated on a relatively small set of well-studied proteins. This imbalance in scientific attention leads to a distorted view of the biological landscape that quietly shapes our data and our algorithms,” Luo said.
“My group’s goal is to build machine learning (ML) models that actively close this gap by generating trustworthy function predictions for the many proteins that remain understudied.”
[Related: Yunan Luo to use AI for Protein Design and Discovery with Support of $1.8 Million NIH Grant]
In his proposal to NSF, Luo coined this rich-get-richer effect “annotation inequality.”
One problem of annotation inequality is that it slows progress in disease prognosis, drug discovery, and other critical biomedical areas. It is challenging to innovate the few proteins that scientists already know so much about.
A cascading effect of annotation inequality is that it diminishes the effectiveness of studying proteins with AI.
AI methods learn from existing experimental data. Datasets skewed toward well-known proteins propagate and become entrenched in models. Over time, this makes it harder for computers to research understudied proteins.
“Protein annotation inequality creates an effect analogous to a vast library where 95% of patrons only read the top 5% popular books, leaving the rest of the collection to gather dust,” Luo said.
“This has resulted in knowledge disparities across proteins in current literature and databases, biasing our understanding of protein functions.”
The NSF CAREER award will fund Luo with over $770,000 for the next five years to tackle head-on the problem of protein annotation inequality.
Luo will use the grant to build an accurate, unbiased protein function prediction framework at scale. His project aims to:
- Reveal how annotation inequality affects protein function prediction systems
- Create ML techniques suited for biological data, which is often noisy, incomplete, and imbalanced
- Integrate data and ML models into a scalable framework to accelerate discoveries involving understudied proteins
More enduring than the ML framework, Luo will leverage the NSF award to support educational and outreach programs. His goal is to groom the next generation of researchers to study other challenges in computational biology, not just the annotation inequality problem.
Luo teaches graduate and undergraduate courses focused on computational biology and ML. Problems and methods developed through the CAREER project can be used as course material in his classes.
Luo also championed collaboration with Georgia Tech’s Center for Education Integrating Science, Mathematics, and Computing (CEISMC) in his proposal.
Through this partnership, local high school teachers and students would gain access to his data and models. This promotes deeper learning of biology and data science through hands-on experience with real-world tools.
Luo sees reaching students and the community as a way of paying forward the support he received from Georgia Tech colleagues.
“I am incredibly grateful for this recognition from the NSF,” said Luo, an assistant professor in the School of Computational Science and Engineering (CSE).
“This would not have been possible without my students and collaborators, whose hard work laid the groundwork for this proposal.”
Luo praised CSE faculty members B. Aditya Prakash, Xiuwei Zhang, and Chao Zhang for their guidance. All three study machine learning and computational bioscience, two of CSE’s five core research areas.
Luo also thanked Haesun Park for her support and recommendation for the CAREER award. Park is a Regents’ Professor and the chair of the School of CSE.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Dec. 01, 2025



Spaceflight is becoming safer, more frequent, and more sustainable thanks to the largest computational fluid flow simulation ever ran on Earth.
Inspired by SpaceX’s Super Heavy booster, a team led by Georgia Tech’s Spencer Bryngelson and New York University’s Florian Schäfer modeled the turbulent interactions of a 33-engine rocket. Their experiment set new records, running the largest ever fluid dynamics simulation by a factor of 20 and the fastest by over a factor of four.
The team ran its custom software on the world’s two fastest supercomputers, as well as the eighth fastest, to construct such a massive model.
Applications from the simulation reach beyond rocket science. The same computing methods can model fluid mechanics in aerospace, medicine, energy, and other fields. At the same time, the work advances understanding of the current limits and future potential of computing.
The team finished as runners-up for the 2025 Gordon Bell Prize for its impactful, multi-domain research. Referred to as the Nobel Prize of supercomputing, the award was presented at the world’s top conference for high-performance computing (HPC) research.
“Fluid dynamics problems of this style, with shocks, turbulence, different interacting fluids, and so on, are a scientific mainstay that marshals our largest supercomputers,” said Bryngelson, an assistant professor with the School of Computational Science and Engineering (CSE).
“Larger and faster simulations that enable solutions to long-standing scientific problems, like the rocket propulsion problem, are always needed. With our work, perhaps we took a big dent out of that issue.”
The Super Heavy booster reflects the space industry’s move toward reusable multi-engine first-stage rockets that are easier to transport and more economical overall.
However, this shift creates research and testing challenges for new designs.
Each of Super Heavy’s 33 thrusters expels propellant at ten times the speed of sound. As individual engines reach extreme temperatures, pressures, and densities, their combined interactions with the airframe make such violent physics even more unpredictable.
Frequent physical experiments would be expensive and risky, so scientists rely on computer models to supplement the engineering process.
Bryngelson’s flagship Multicomponent Flow Code (MFC) software anchored the experiment. MFC is an open-source computer program that simulates fluid dynamic models. Bryngelson’s lab has been modifying MFC since 2022 to run on more powerful computers and solve larger problems.
In computing terms, this MFC-enhanced model simulated fluid flow resolution at 200 trillion grid points and one quadrillion degrees of freedom. These metrics exceeded previous record-setting benchmarks that tallied 10 trillion and 30 trillion grid points.
This means MFC simulations provide greater detail and capture smaller-scale features than previous approaches. The rocket simulation also ran four times faster and achieved 5.7 times the energy efficiency of comparable methods.
Integrating information geometric regularization (IGR) into MFC played a key role in attaining these results. This new approach improved the simulation’s computational efficiency and overcame the challenge of shock dynamics.
In fluid mechanics, shock waves occur when objects move faster than the speed of sound. Along with hampering the performance of airframes and propulsion systems, shocks have historically been difficult to simulate.
Computational scientists have used empirical models based on artificial viscosity to account for shocks. Although these approaches mimic the physical effects of shock waves at the microscopic scale, they struggle to effectively capture the large-scale features of the flow.
Information geometry uses curved spaces to study concepts of statistics and information. IGR uses these tools to modify the underlying geometry in fluid dynamics equations. When traveling in the modified geometry, fluid in the model preserves the shocks in a more natural way.
“When regularizing shocks to much larger scales relevant in these numerical simulations, conventional methods smear out important fine-scale details,” said Schäfer, an assistant professor at NYU’s Courant Institute of Mathematical Sciences.
“IGR introduces ideas from abstract math to CFD that allow creating modified paths that approach the singularity without ever reaching it. In the resulting fluid flow, shocks never become too spiky in simulations, but the fine-scale details do not smear out either.”
Simulating a model this large required the Georgia Tech researchers to run MFC on El Capitan and Frontier, the world's two fastest supercomputers.
The systems are two of four exascale machines in existence. This means they can solve at least one quintillion (“1” followed by 18 zeros) calculations per second. If a person completed a simple math calculation every second, it would take that person about 30 billion years to reach one quintillion operations.
Frontier is housed at Oak Ridge National Laboratory and debuted as the world’s first exascale supercomputer in 2022. El Capitan surpassed Frontier when Lawrence Livermore National Laboratory launched it in 2024.
To prepare MFC for performance on these machines, Bryngelson’s lab followed a methodical approach spanning years of hardware acquisition and software engineering.
In 2022, Bryngelson attained an AMD MI210 GPU accelerator. Optimizing MFC on the component played a critical step toward preparing the software for exascale machines.
AMD hardware underpins both El Capitan and Frontier. The MI300A GPU powers El Capitan while Frontier uses the MI250X GPU.
After configuring MFC on the MI210 GPU, Bryngelson’s lab ran the software on Frontier for the first time during a 2023 hackathon. This confirmed the code was ready for full-scale deployment on exascale supercomputers based on AMD hardware.
In addition to El Capitan and Frontier, the simulation ran on Alps, the world’s eight-fastest supercomputer based at the Swiss National Supercomputing Centre. It is the largest available system that features the NVIDIA GH200 Grace Hopper Superchip.
Like with AMD GPUs, Bryngelson acquired four GH200s in 2024 and began configuring MFC to the latest hardware innovation powering New Age supercomputers. Later that year, the Jülich Research Centre accepted Bryngelson’s group into an early access program to test JUPITER, a developing supercomputer based on the NVIDIA superchip.
The group earned a certificate for scaling efficiency and node performance on the way toward validating that their code worked on the GH200. The early access project proved successful for JUPITER, which launched in 2025 as Europe’s fastest supercomputer and fourth fastest in the world.
“Getting the level of hands-on experience with world-leading supercomputers and computing resources at Georgia Tech through this project has been a fantastic opportunity for a grad student,” said CSE Ph.D. student Ben Wilfong.
“To leverage these machines, I learned more advanced programming techniques that I’m glad to have in my tool belt for future projects. I also enjoyed the opportunity to work closely with and learn from industry experts from NVIDIA, AMD, and HPE/Cray.”
El Capitan, Frontier, JUPITER, and Alps maintained their rankings at the 2025 International Conference for High Performance Computing Networking, Storage and Analysis (SC25). Of note, the TOP500 announced at SC25 that JUPITER surpassed the exaflop threshold.
The SC Conference Series is one of two venues where the TOP500 announces updated supercomputer rankings every June and November. The TOP500 ranks and details the 500 most powerful supercomputers in the world.
The SC Conference Series serves as the venue where the Association for Computing Machinery (ACM) presents the Gordon Bell Prize. The annual award recognizes achievement in HPC research and application. The Tech-led team was among eight finalists for this year’s award.
Along with Bryngelson, Georgia Tech members included Ph.D. students Anand Radhakrishnan and Wilfong, postdoctoral researcher Daniel Vickers, alumnus Henry Le Berre (CS 2025), and undergraduate student Tanush Prathi.
Schäfer’s partnership with the group stems from his previous role as an assistant professor at Georgia Tech from 2021 to 2025.
Collaborators on the project included Nikolaos Tselepidis and Benedikt Dorschner from NVIDIA, Reuben Budiardja from ORNL, Brian Cornille from AMD, and Stephen Abbot from HPE. All were co-authors of the paper and named finalists for the Gordon Bell Prize.
“I’m elated that we have been nominated for such a prestigious award. It wouldn't have been possible without the combined and diligent efforts of our team,” Radhakrishnan said.
“I’m looking forward to presenting our work at SC25 and connecting with other researchers and fellow finalists while showcasing seminal work in the field of computing.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Nov. 20, 2025

Georgia Institute of Technology has been ranked 7th in the world in the 2026 Times Higher Education Interdisciplinary Science Rankings, in association with Schmidt Science Fellows. This designation underscores Georgia Tech’s leadership in research that solves global challenges.
“Interdisciplinary research is at the heart of Georgia Tech’s mission,” said Tim Lieuwen, executive vice president for Research. “Our faculty, students, and research teams work across disciplines to create transformative solutions in areas such as healthcare, energy, advanced manufacturing, and artificial intelligence. This ranking reflects the strength of our collaborative culture and the impact of our research on society.”
As a top R1 research university, Georgia Tech is shaping the future of basic and applied research by pursuing inventive solutions to the world’s most pressing problems. Whether discovering cancer treatments or developing new methods to power our communities, work at the Institute focuses on improving the human condition.
Teams from all seven Georgia Tech colleges, 11 interdisciplinary research institutes, the Georgia Tech Research Institute, Enterprise Innovation Institute, and hundreds of research labs and centers work together to transform ideas into real results.
News Contact
Angela Ayers
Oct. 06, 2025


Students in machine learning and linear algebra courses this semester are learning from one of Georgia Tech’s most celebrated instructors.
Raphaël Pestourie has earned back-to-back selections to the Institute’s Course Instructor Opinion Survey (CIOS) honor roll, placing him among the top-ranked teachers for Fall 2024 and Spring 2025.
By returning to the classroom this semester to teach two more courses, Pestourie continues to leverage proven experience to mentor the next generation of researchers in his field.
“Students played a very important part in the survey process, and I thank them for making the classes great,” said Pestourie, an assistant professor in the School of Computational Science and Engineering (CSE).
“I'm incredibly grateful that students shared their feedback so that I could go the extra mile to not only apply my expertise to teach in ways that I think work, but transform my instruction to reach students in the most impactful way I can.”
CIOS honor rolls recognize instructors for outstanding teaching and educational impact, based on student feedback provided through end-of-course surveys.
Student praise of Pestourie’s CSE 8803: Scientific Machine Learning class placed him on the Fall 2024 CIOS honor roll. He earned selection to the Spring 2025 honor roll for his instruction of CX 4230: Computer Simulation.
CSE 8803 is a graduate-level, special topics class that Pestourie created around his field of expertise. Scientific machine learning involves merging two traditionally distinct fields: scientific computing and machine learning.
In scientific computing, researchers build and use models based on established physical laws. Machine learning differs in that it employs data-driven models to find patterns without prior assumptions. Combining the two fields opens new ways to analyze data and solve challenging problems in science and engineering.
Pestourie organized student-focused scientific machine learning symposiums in Fall 2023 and 2024. CSE 8803 students work on projects throughout the course and present their work at these symposiums. Pestourie will use the same approach this semester.
Compared to CSE 8803, CX 4230 is an undergraduate course that teaches students how to create computer models of complex systems. A complex system has many interacting entities that influence each other’s behaviors and patterns. Disease spread in a human network is one example of a complex system.
CX 4230 is a required course for computer science students studying the Modeling & Simulation thread. It is also an elective course in the Scientific and Engineering Computing minor.
“I see 8803 as my educational baby. Being acknowledged for it with a CIOS honor roll felt great,” Pestourie said.
“In a way, I'm prouder of CX 4230 because it was a large, undergraduate regular offering that I was teaching for the first time. The honor roll selection came almost as a surprise.”
To be eligible for the honor roll recognition, instructors must have a minimum CIOS response rate of 70%. Composite scores for three CIOS items are then used to rank instructors. Those items are:
- Instructor’s respect and concern for students
- Instructor’s level of enthusiasm about the course
- Instructor’s ability to stimulate interest in the subject matter
Georgia Tech’s Center for Teaching and Learning (CTL) and the Office of Academic Effectiveness present the CIOS Honor Rolls. CTL recognizes honor roll recipients at its Celebrating Teaching Day events, held annually in March.
CTL offers the Class of 1969 Teaching Fellowship, in which Pestourie participated in the 2024-2025 cohort. The program aims to broaden perspectives with insight into evidence-based best practices and exposure to new and innovative teaching methods.
The fellowship offers one-on-one consultations with a teaching and learning specialist. Cohorts meet weekly in the fall semester and monthly in the spring semester for instruction seminars.
The fellowship facilitates peer observations where instructors visit other classrooms, exchange feedback, and learn effective techniques to try in their own classes.
“I'm very grateful for the Class of 1969 fellowship program and to Karen Franklin, who coordinates it,” Pestourie said. “The honor roll is not just a one-person award. Support from the Institute and other people in the program made it happen.”
Like in Fall 2023 and 2024, Pestourie is teaching CSE 8803: Scientific Machine Learning again this semester. Additionally, he teaches CSE 8801: Linear Algebra, Probability, and Statistics.
Linear algebra and applied probability are among the fundamental subjects in modern data science. Like his scientific machine learning class, Pestourie created CSE 8801. This semester marks the second time Pestourie is teaching the course since Fall 2024.
Pestourie designed CSE 8801 as a refresher course for newer graduate students. This addresses a point of need to help students get off to a good start at Georgia Tech. By offering guidance early in their graduate careers, Pestourie’s work in the classroom also aims to cultivate future collaborators and serve his academic community.
“I see teaching as our one shot at making a good first impression as a research field and a community,” he said.
“I see my work as a teacher as training my future colleagues, and I see it as my duty to our community to do my best in attracting the best talent toward our research field.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Sep. 11, 2025

A recently awarded $20 million NSF Nexus Supercomputer grant to Georgia Tech and partner institutes promises to bring incredible computing power to the CODA building. But what makes this supercomputer different and how will it impact research in labs on campus, across disciplinary units, and across institutions?
Purpose Built for AI Discovery
Nexus is Georgia Tech’s next-generation supercomputer, replacing the HIVE. Most operational high-performance computing systems utilized for research were designed before the explosion in Machine Learning and AI. This revolution has already shown successes for scientific research and data analysis in many domains, but the compute power, complex connectivity, and data storage needs for these systems have limited their access to the academic research community. The Nexus supercomputer design process retained a robust HPC system as a base while integrating artificial intelligence, machine learning and large-scale data science analysis from the ground up.
Expert Support for Faculty and Researchers
The Institute for Data Engineering and Science (IDEaS) and the College of Computing house the Center for Artificial Intelligence in Science and Engineering (ARTISAN) group. This team has collective experience in working with national computational, cloud, commercial and institutional resources for computational activities, and decades of experience in scientific tools that aid in assisting both teaching and research faculty. Nexus is the next logical step, bringing together everything they’ve learned to build a national resource optimized for the future of AI-driven science.
Principal Research Scientist for the ARTISAN team, Suresh Marru, highlighted the need for this new resource, “AI is a core part of the Nexus vision. Today, researchers often spend more time setting up experiments, managing data, or figuring out how to run jobs on remote clusters than doing science. With Nexus, we’re flipping that script. By embedding AI into the platform, we help automate routine tasks, suggest optimal ways to run simulations, and even assist in generating input or analyzing results. This means researchers can move faster from question to insight. Instead of wrestling with infrastructure, they can focus on discovery.”
An Accessible AI Resource for GT & US Scientific Research
90% of Nexus capacity will be made available to the national research community through the NSF Advanced Computing Systems & Services (ACSS) program. Researchers from across the country, at universities, labs, and institutions of all sizes, will have access to this next-generation AI-ready supercomputer. For Georgia Tech research faculty and staff, the new system has multiple benefits:
- 10% of the time on the machine will be available for use by Georgia Tech researchers
- Nexus will allow GT researchers a chance to try out the latest hardware for AI computing
- Thanks to cyberinfrastructure tools from the ARTISAN group, Nexus will be easier to access than previous NSF supercomputers
Interim Executive Director of IDEaS and Regents' Professor David Sherrill notes, "Nexus brings Georgia Tech's leadership in research computing to a whole new level. It will be the first NSF Category I Supercomputer hosted on Georgia Tech's campus. The Nexus hardware and software will boost research in the foundations of AI, and applications of AI in science and engineering."
Jul. 25, 2025

As Georgia positions itself as a hub for digital infrastructure, communities across the state are facing a growing challenge: how to welcome the economic benefits of data centers while managing their significant environmental and infrastructure impacts. These facilities, essential for powering artificial intelligence, cloud computing, and everyday internet use, are also among the most resource-intensive buildings in the modern economy.
While companies like Microsoft and Google have pledged to reach net-zero emissions, experts say more transparency and smarter policy are needed to ensure that data center development aligns with community and environmental priorities. That means ensuring adequate energy infrastructure, investing in renewables, training local workers, and mitigating water and carbon impacts through innovation.
A New Kind of Energy Crunch
The rapid rise of AI is fueling explosive demand for computing power — and in turn, energy.
“The proliferation of AI workloads has significantly increased data center energy requirements,” says Divya Mahajan, assistant professor in the School of Electrical and Computer Engineering. “Large-scale AI training, especially for language models, leads to elevated and sustained power draw, often nearing the thermal and power envelopes of graphics processing units systems.”
This sustained demand is particularly challenging in hot, humid regions like Georgia, where cooling systems must work harder. “Training these models can cause thermal instability that directly affects cooling efficiency and power provisioning,” Mahajan explains. “This amplifies reliance on external cooling infrastructure, increasing water consumption and grid strain.”
Environmental and Economic Pressure
“Each new data center could lead to greenhouse gas emissions equivalent to a small town,” says Marilyn Brown, Regents’ and Brook Byers Professor of Sustainable Systems in the School of Public Policy. “In Georgia, the growth of data centers has already led to plans for new gas plants and the extension of aging coal plants.”
There’s an environmental cost to this growth: electricity and water. A single large data center can consume up to 5 million gallons of water per day.
Rising demand has a price. “It’s simple supply and demand,” says Ahmed Saeed, assistant professor at the School of Computer Science. “As overall power demand increases, if supply doesn’t keep up, costs will rise and the most affected will be lower-income consumers.”
Still, experts are optimistic that policy and technology can help mitigate these impacts.
Innovation May Hold the Key
Despite the challenges, experts see opportunities for innovation. “Technologies like direct-to-chip cooling and liquid cooling are promising,” says Mahajan. “But they’re not yet widespread.”
Saeed notes that some companies are experimenting with radical ideas, like Microsoft’s underwater Project Natick or locating data centers in Nordic countries where ambient air can be used for cooling. These approaches challenge conventional infrastructure norms by placing servers underwater or in remote, cold regions. “These are exciting, but we need scalable solutions that work in places like Georgia,” he emphasizes.
What Communities Should Ask For
As communities compete to attract data centers, experts say they should push for commitments that go beyond job creation.
“Communities should ensure that their power infrastructure can handle the added load without compromising resilience or increasing costs,” Saeed advises. “They should also require that data centers use renewable energy or invest in local clean energy projects.”
Training and hiring local workers is another key benefit communities can demand. “Deployment and maintenance of data centers require skilled workers,” Saeed adds. “Operators should invest in technical training and hire locally.”
Policy Can Make the Difference
Stronger policy frameworks can ensure growth doesn’t come at the expense of Georgia’s most vulnerable communities. “We need more transparency from companies about their energy and water use,” says Brown. “And we need policies that prevent the costs of supporting large consumers from being passed on to residential ratepayers.”
Some states are already taking action. Texas passed a bill to give regulators more control over large power consumers. In Georgia, a bill that would have paused tax breaks for data centers until their community impact was assessed was vetoed — but experts say the conversation is far from over.
“Data centers are here to stay,” says Saeed. “The question is whether we can make them sustainable — before their footprint becomes too large to manage.”
May. 02, 2025

Georgia Tech researchers played a key role in the development of a groundbreaking AI framework designed to autonomously generate and evaluate scientific hypotheses in the field of astrobiology. Amirali Aghazadeh, assistant professor in the school of electrical and computer engineering, co-authored the research and contributed to the architecture that divides tasks among multiple specialized AI agents.
This framework, known as the AstroAgents system, is a modular approach which allows the system to simulate a collaborative team of scientists, each with distinct roles such as data analysis, planning, and critique, thereby enhancing the depth and originality of the hypotheses generated
News Contact
Amelia Neumeister | Research Communications Program Manager
The Institute for Matter and Systems
Mar. 06, 2025

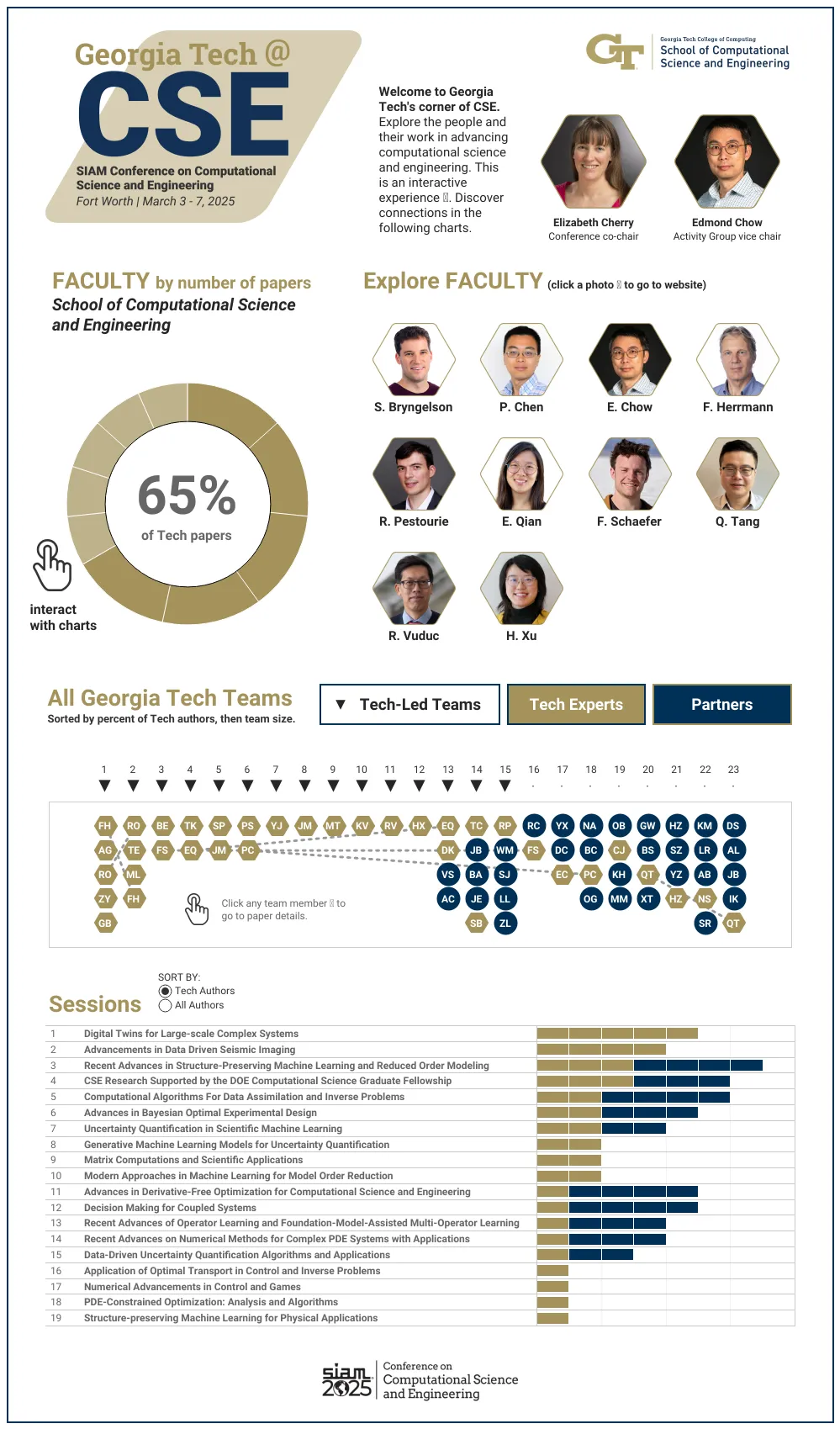
Many communities rely on insights from computer-based models and simulations. This week, a nest of Georgia Tech experts are swarming an international conference to present their latest advancements in these tools, which offer solutions to pressing challenges in science and engineering.
Students and faculty from the School of Computational Science and Engineering (CSE) are leading the Georgia Tech contingent at the SIAM Conference on Computational Science and Engineering (CSE25). The Society of Industrial and Applied Mathematics (SIAM) organizes CSE25, occurring March 3-7 in Fort Worth, Texas.
At CSE25, the School of CSE researchers are presenting papers that apply computing approaches to varying fields, including:
- Experiment designs to accelerate the discovery of material properties
- Machine learning approaches to model and predict weather forecasting and coastal flooding
- Virtual models that replicate subsurface geological formations used to store captured carbon dioxide
- Optimizing systems for imaging and optical chemistry
- Plasma physics during nuclear fusion reactions
[Related: GT CSE at SIAM CSE25 Interactive Graphic]
“In CSE, researchers from different disciplines work together to develop new computational methods that we could not have developed alone,” said School of CSE Professor Edmond Chow.
“These methods enable new science and engineering to be performed using computation.”
CSE is a discipline dedicated to advancing computational techniques to study and analyze scientific and engineering systems. CSE complements theory and experimentation as modes of scientific discovery.
Held every other year, CSE25 is the primary conference for the SIAM Activity Group on Computational Science and Engineering (SIAG CSE). School of CSE faculty serve in key roles in leading the group and preparing for the conference.
In December, SIAG CSE members elected Chow to a two-year term as the group’s vice chair. This election comes after Chow completed a term as the SIAG CSE program director.
School of CSE Associate Professor Elizabeth Cherry has co-chaired the CSE25 organizing committee since the last conference in 2023. Later that year, SIAM members reelected Cherry to a second, three-year term as a council member at large.
At Georgia Tech, Chow serves as the associate chair of the School of CSE. Cherry, who recently became the associate dean for graduate education of the College of Computing, continues as the director of CSE programs.
“With our strong emphasis on developing and applying computational tools and techniques to solve real-world problems, researchers in the School of CSE are well positioned to serve as leaders in computational science and engineering both within Georgia Tech and in the broader professional community,” Cherry said.
Georgia Tech’s School of CSE was first organized as a division in 2005, becoming one of the world’s first academic departments devoted to the discipline. The division reorganized as a school in 2010 after establishing the flagship CSE Ph.D. and M.S. programs, hiring nine faculty members, and attaining substantial research funding.
Ten School of CSE faculty members are presenting research at CSE25, representing one-third of the School’s faculty body. Of the 23 accepted papers written by Georgia Tech researchers, 15 originate from School of CSE authors.
The list of School of CSE researchers, paper titles, and abstracts includes:
Bayesian Optimal Design Accelerates Discovery of Material Properties from Bubble Dynamics
Postdoctoral Fellow Tianyi Chu, Joseph Beckett, Bachir Abeid, and Jonathan Estrada (University of Michigan), Assistant Professor Spencer Bryngelson
[Abstract]
Latent-EnSF: A Latent Ensemble Score Filter for High-Dimensional Data Assimilation with Sparse Observation Data
Ph.D. student Phillip Si, Assistant Professor Peng Chen
[Abstract]
A Goal-Oriented Quadratic Latent Dynamic Network Surrogate Model for Parameterized Systems
Yuhang Li, Stefan Henneking, Omar Ghattas (University of Texas at Austin), Assistant Professor Peng Chen
[Abstract]
Posterior Covariance Structures in Gaussian Processes
Yuanzhe Xi (Emory University), Difeng Cai (Southern Methodist University), Professor Edmond Chow
[Abstract]
Robust Digital Twin for Geological Carbon Storage
Professor Felix Herrmann, Ph.D. student Abhinav Gahlot, alumnus Rafael Orozco (Ph.D. CSE-CSE 2024), alumnus Ziyi (Francis) Yin (Ph.D. CSE-CSE 2024), and Ph.D. candidate Grant Bruer
[Abstract]
Industry-Scale Uncertainty-Aware Full Waveform Inference with Generative Models
Rafael Orozco, Ph.D. student Tuna Erdinc, alumnus Mathias Louboutin (Ph.D. CS-CSE 2020), and Professor Felix Herrmann
[Abstract]
Optimizing Coupled Systems: Insights from Co-Design Imaging and Optical Chemistry
Assistant Professor Raphaël Pestourie, Wenchao Ma and Steven Johnson (MIT), Lu Lu (Yale University), Zin Lin (Virginia Tech)
[Abstract]
Multifidelity Linear Regression for Scientific Machine Learning from Scarce Data
Assistant Professor Elizabeth Qian, Ph.D. student Dayoung Kang, Vignesh Sella, Anirban Chaudhuri and Anirban Chaudhuri (University of Texas at Austin)
[Abstract]
LyapInf: Data-Driven Estimation of Stability Guarantees for Nonlinear Dynamical Systems
Ph.D. candidate Tomoki Koike and Assistant Professor Elizabeth Qian
[Abstract]
The Information Geometric Regularization of the Euler Equation
Alumnus Ruijia Cao (B.S. CS 2024), Assistant Professor Florian Schäfer
[Abstract]
Maximum Likelihood Discretization of the Transport Equation
Ph.D. student Brook Eyob, Assistant Professor Florian Schäfer
[Abstract]
Intelligent Attractors for Singularly Perturbed Dynamical Systems
Daniel A. Serino (Los Alamos National Laboratory), Allen Alvarez Loya (University of Colorado Boulder), Joshua W. Burby, Ioannis G. Kevrekidis (Johns Hopkins University), Assistant Professor Qi Tang (Session Co-Organizer)
[Abstract]
Accurate Discretizations and Efficient AMG Solvers for Extremely Anisotropic Diffusion Via Hyperbolic Operators
Golo Wimmer, Ben Southworth, Xianzhu Tang (LANL), Assistant Professor Qi Tang
[Abstract]
Randomized Linear Algebra for Problems in Graph Analytics
Professor Rich Vuduc
[Abstract]
Improving Spgemm Performance Through Reordering and Cluster-Wise Computation
Assistant Professor Helen Xu
[Abstract]
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Mar. 14, 2025


Successful test results of a new machine learning (ML) technique developed at Georgia Tech could help communities prepare for extreme weather and coastal flooding. The approach could also be applied to other models that predict how natural systems impact society.
Ph.D. student Phillip Si and Assistant Professor Peng Chen developed Latent-EnSF, a technique that improves how ML models assimilate data to make predictions.
In experiments predicting medium-range weather forecasting and shallow water wave propagation, Latent-EnSF demonstrated higher accuracy, faster convergence, and greater efficiency than existing methods for sparse data assimilation.
“We are currently involved in an NSF-funded project aimed at providing real-time information on extreme flooding events in Pinellas County, Florida,” said Si, who studies computational science and engineering (CSE).
“We're actively working on integrating Latent-EnSF into the system, which will facilitate accurate and synchronized modeling of natural disasters. This initiative aims to enhance community preparedness and safety measures in response to flooding risks.”
Latent-EnSF outperformed three comparable models in assimilation speed, accuracy, and efficiency in shallow water wave propagation experiments. These tests show models can make better and faster predictions of coastal flood waves, tides, and tsunamis.
In experiments on medium-range weather forecasting, Latent-EnSF surpassed the same three control models in accuracy, convergence, and time. Additionally, this test demonstrated Latent-EnSF's scalability compared to other methods.
These promising results support using ML models to simulate climate, weather, and other complex systems.
Traditionally, such studies require employment of large, energy-intensive supercomputers. However, advances like Latent-EnSF are making smaller, more efficient ML models feasible for these purposes.
The Georgia Tech team mentioned this comparison in its paper. It takes hours for the European Center for Medium-Range Weather Forecasts computer to run its simulations. Conversely, the ML model FourCastNet calculated the same forecast in seconds.
“Resolution, complexity, and data-diversity will continue to increase into the future,” said Chen, an assistant professor in the School of CSE.
“To keep pace with this trend, we believe that ML models and ML-based data assimilation methods will become indispensable for studying large-scale complex systems.”
Data assimilation is the process by which models continuously ingest new, real-world data to update predictions. This data is often sparse, meaning it is limited, incomplete, or unevenly distributed over time.
Latent-EnSF builds on the Ensemble Filter Scores (EnSF) model developed by Florida State University and Oak Ridge National Laboratory researchers.
EnSF’s strength is that it assimilates data with many features and unpredictable relationships between data points. However, integrating sparse data leads to lost information and knowledge gaps in the model. Also, such large models may stop learning entirely from small amounts of sparse data.
The Georgia Tech researchers employ two variational autoencoders (VAEs) in Latent-EnSF to help ML models integrate and use real-world data. The VAEs encode sparse data and predictive models together in the same space to assimilate data more accurately and efficiently.
Integrating models with new methods, like Latent-EnSF, accelerates data assimilation. Producing accurate predictions more quickly during real-world crises could save lives and property for communities.
To share Latent-EnSF to the broader research community, Chen and Si presented their paper at the SIAM Conference on Computational Science and Engineering (CSE25). The Society of Industrial and Applied Mathematics (SIAM) organized CSE25, held March 3-7 in Fort Worth, Texas.
Chen was one of ten School of CSE faculty members who presented research at CSE25, representing one-third of the School’s faculty body. Latent-EnSF was one of 15 papers by School of CSE authors and one of 23 Georgia Tech papers presented at the conference.
The pair will also present Latent-EnSF at the upcoming International Conference on Learning Representations (ICLR 2025). Occurring April 24-28 in Singapore, ICLR is one of the world’s most prestigious conferences dedicated to artificial intelligence research.
“We hope to bring attention to experts and domain scientists the exciting area of ML-based data assimilation by presenting our paper,” Chen said. “Our work offers a new solution to address some of the key shortcomings in the area for broader applications.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu