Jun. 27, 2025

An Adobe Stock image of a woman using a wheelchair and wearing a grey business suit meets with work colleagues.
A team of Georgia Tech graduate students is using artificial intelligence (AI) to help people with disabilities find their dream jobs.
Searching for the right job is stressful for most, but it can be overwhelming for people with disabilities. However, using an innovative approach, the student entrepreneurs created a customizable AI-powered "job coach" that connects people with accessible employment opportunities.
OMSCS students George Gomez, Ariel Magyar, Zachary Patrignani, and Maheer Sayeed created Interstellar Jobs as their entry for the March 2025 Microsoft Azure Innovation Challenge. The team beat over 70 international entries to secure first place and $10,000.
Interstellar Jobs uses information about job seekers' disabilities, job preferences, and other personal details to provide detailed coaching tips for specific jobs. The tips let job seekers know if they're a good fit for the position, what challenges they can expect, and what they can do to manage these challenges successfully.
The challenge, co-sponsored by TechBridge, required teams to create a functional proof of concept within a tight timeframe using AI, analytics, networking, and other Microsoft Azure Web Services.
Selecting which services to use was the starting point for most teams. In fact, Sayeed says most of the competition tried to use as many Azure services as possible for their projects.
"We didn't do that. We kept it simple," said Sayeed.
"Our mindset going into the challenge was that we'd find the problem first, and then we would look at the services we would use."
Their entrepreneurial approach led the team to develop Interstellar Jobs using just three Azure services. As an example of their approach, the team faced the challenge of addressing specific disabilities in relation to thousands of job listings.
Developers usually depend on drop-down menus when presenting an extensive list of options. However, this method might not cover all disabilities or could use outdated or overly broad language. It also wouldn't account for people with multiple or nuanced disabilities that don't fit neatly into a single category.
The Interstellar Jobs team opted for a blank field for users to list their disabilities.
"We kept it very open-ended for our users," said Sayeed.
The team used OpenAI Service to 'clean' entries on the backend, regardless of what users wrote in the blank field. This method ensures that users can always get a structured and actionable response from Interstellar Jobs.
"As a user, not having to pick from a drop-down menu just feels good," said Matt Calder, senior product marketing manager at Microsoft.
Calder hosts Microsoft DevRadio and recently interviewed the Interstellar Jobs team. "I like how your approach changes how people interact with the whole system. If you make something really usable, it's going to be accessible as well," said Calder.
Despite its success, the team has no immediate plans to expand Interstellar Jobs. Each member balances a full-time job and their studies in Georgia Tech's Online Master of Science in Computer Science (OMSCS) program.
"We gained so much about cloud development and Azure Web Services from the experience," said Sayeed. "We also learned the value of AI in these applications."
News Contact
Ben Snedeker, Communications Manager II
Georgia Tech College of Computing
Jun. 25, 2025

School of Interactive Computing Assistant Professor Sehoon Ha, Neuromeka researchers Joonho Lee and Yunho Kim, School of IC Assistant Professor Jennifer Kim, and Electronics and Telecommunications Research Institute researcher Dongyeop Kang, are collaborating to develop a medical assistant robot to support doctors and nurses in Korea. Photo by Nathan Deen/College of Computing.
Overwhelmed doctors and nurses struggling to provide adequate patient care in South Korea are getting support from Georgia Tech and Korean-based researchers through an AI-powered robotic medical assistant.
Top South Korean research institutes have enlisted Georgia Tech researchers Sehoon Ha and Jennifer G. Kim to develop artificial intelligence (AI) to help the humanoid assistant navigate hospitals and interact with doctors, nurses, and patients.
Ha and Kim will partner with Neuromeka, a South Korean robotics company, on a five-year, 10 billion won (about $7.2 million US) grant from the South Korean government. Georgia Tech will receive about $1.8 million of the grant.
Ha and Kim, assistant professors in the School of Interactive Computing, will lead Tech’s efforts and also work with researchers from the Korea Advanced Institute of Science and Technology and the Electronics and Telecommunications Research Institute.
Neuromeka has built industrial robots since its founding in 2013 and recently decided to expand into humanoid service robots.
Lee, the group leader of the humanoid medical assistant project, said he fielded partnership requests from many academic researchers. Ha and Kim stood out as an ideal match because of their robotics, AI, and human-computer interaction expertise.
For Ha, the project is an opportunity to test navigation and control algorithms he’s developed through research that earned him the National Science Foundation CAREER Award. Ha combines computer simulation and real-world training data to make robots more deployable in high-stress, chaotic environments.
“Dr. Ha has everything we want to put into our system, including his navigation policies,” Lee said. “He works with robots and AI, and there weren’t many candidates in that space. We needed a collaborator who can create the software and has experience running it on robots.”
Ha said he is already considering how his algorithms could scale beyond hospitals and become a universal means of robot navigation in unstructured real-world environments.
“For now, we’re focusing on a customized navigation model for Korean environments, but there are ways to transfer the data set to different environments, such as the U.S. or European healthcare systems,” Ha said.
“The final product can be deployed to other systems and industries. It can help industrial workers at factories, retail stores, any place where workers can get overwhelmed by a high volume of tasks.”
Kim will focus on making the robot’s design and interaction features more human. She’ll develop a large-language model (LLM) AI system to communicate with patients, nurses, and doctors. She’ll also develop an app that will allow users to input their commands and queries.
“This project is not just about controlling robots, which is why Dr. Kim’s expertise in human-computer interaction design through natural language was essential.,” Lee said.
Kim is interviewing stakeholders from three South Korean hospitals to identify service and care pain points. The issues she’s identified so far relate to doctor-patient communication, a lack of emotional support for patients, and an excessive number of small tasks that consume nurses’ time.
“Our goal is to develop this robot in a very human-centered way,” she said. “One way is to give patients a way to communicate about the quality of their care and how the robot can support their emotional well-being.
“We found that patients often hesitate to ask busy nurses for small things like getting a cup of water. We believe this is an area a robot can support.”
The robot’s hardware will be built in Korea, while Ha and Kim will develop the software in the U.S.
Jong-hoon Park, CEO of Neuromeka, said in a press release the goal is to have a commercialized product as soon as possible.
“Through this project, we will solve problems that existing collaborative robots could not,” Park said. “We expect the medical AI humanoid robot technology being developed will contribute to reducing the daily work burden of medical and healthcare workers in the field.”
Jun. 11, 2025

An algorithmic breakthrough from School of Interactive Computing researchers that earned a Meta partnershipdrew more attention at the IEEE International Conference on Robotics and Automation (ICRA).
Meta announced in February its partnership with the labs of professors Danfei Xu and Judy Hoffman on a novel computer vision-based algorithm called EgoMimic. It enables robots to learn new skills by imitating human tasks from first-person video footage captured by Meta’s Aria smart glasses.
Xu’s Robot Learning and Reasoning Lab (RL2) displayed EgoMimic in action at ICRA May 19-23 at the World Congress Center in Atlanta.
Lawrence Zhu, Pranav Kuppili, and Patcharapong “Elmo” Aphiwetsa — students from Xu’s lab — used Egomimic to compete in a robot teleoperation contest at ICRA. The team finished second in the event titled What Bimanual Teleoperation and Learning from Demonstration Can Do Today, earning a $10,000 cash prize.
Teams were challenged to perform tasks by remotely controlling a robot gripper. The robot had to fold a tablecloth, open a vacuum-sealed container, place an object into the container, and then reseal it in succession without any errors.
Teams completed the tasks as many times as possible in 30 minutes, earning points for each successful attempt.
The competition also offered different challenge levels that increased the points awarded. Teams could directly operate the robot with a full workstation view and receive one point for each task completion. Or, as the RL2 team chose, teams could opt for the second challenge level.
The second level required an operator to control the task with no view of the workstation except for what was provided to through a video feed. The RL2 team completed the task seven times and received double points for the challenge level.
The third challenge level required teams to operate remotely from another location. At this level, teams could earn four times the number of points for each successful task completed. The fourth level challenged teams to deploy an algorithm for task performance and awarded eight points for each completion.
Using two of Meta’s Quest wireless controllers, Zhu controlled the robot under the direction of Aphiwetsa, while Kuppili monitored the coding from his laptop.
“It’s physically difficult to teleoperate for half an hour,” Zhu said. “My hands were shaking from holding the controllers in the air for that long.”
Being in constant communication with Aphiwetsa helped him stay focused throughout the contest.
“I helped him strategize the teleoperation and noticed he could skip some of the steps in the folding,” Aphiwetsa said. “There were many ways to do it, so I just told him what he could fix and how to do it faster.”
Zhu said he and his team had intended to tackle the fourth challenge level with the EgoMimic algorithm. However, due to unexpected time constraints, they decided to switch to the second level the day before the competition due to unexpected time constraints.
“I think we realized the day before the competition training the robot on our model would take a huge amount of time,” Zhu said. “We decided to go for the teleoperation and started practicing.”
He said the team wants to tackle the highest challenge level and use a training model for next year’s ICRA competition in Vienna, Austria.
ICRA is the world’s largest robotics conference, and Atlanta hosted the event for the third time in its history, drawing a record-breaking attendance of over 7,000.
May. 14, 2025

The School of Cybersecurity and Privacy at Georgia Tech is proud to recognize the accomplishments of five doctoral students who finished their doctoral programs in Spring 2025. These scholars have advanced critical research in software security, cryptography, and privacy, collectively publishing 34 papers, most of which appear in top-tier venues.
Ammar Askar developed new tools for software security in multi-language systems, including a concolic execution engine powered by large language models. He highlighted DEFCON 2021, which he attended with the Systems Software and Security Lab (SSLab), as a favorite memory.
Zhengxian He persevered through the pandemic to lead a major project with an industry partner, achieving strong research outcomes. He will be joining Amazon and fondly remembers watching sunsets from the CODA building.
Stanislav Peceny focused on secure multiparty computation (MPC), designing high-performance cryptographic protocols that improve efficiency by up to 1000x. He’s known for his creativity in both research and life, naming avocado trees after famous mathematicians and enjoying research discussions on the CODA rooftop.
Qinge Xie impressed faculty with her adaptability across multiple domains. Her advisor praised her independence and technical range, noting her ability to pivot seamlessly between complex research challenges.
Yibin Yang contributed to the advancement of zero-knowledge proofs and MPC, building toolchains that are faster and more usable than existing systems. His work earned a Distinguished Paper Award at ACM CCS 2023, and he also served as an RSAC Security Scholar. Yang enjoyed teaching and engaging with younger students, especially through events like Math Kangaroo.
Faculty mentors included Regents’ Entrepreneur Mustaque Ahamad, Professors Taesoo Kim and Vladimir Kolesnikov, and Assistant Professor Frank Li, who played vital roles in guiding the graduates’ research journeys.
Learn more about the graduates and their mentors on the 2025 Ph.D. graduate microsite.
News Contact
JP Popham, Communications Officer II
College of Computing | School of Cybersecurity and Privacy
Mar. 21, 2025

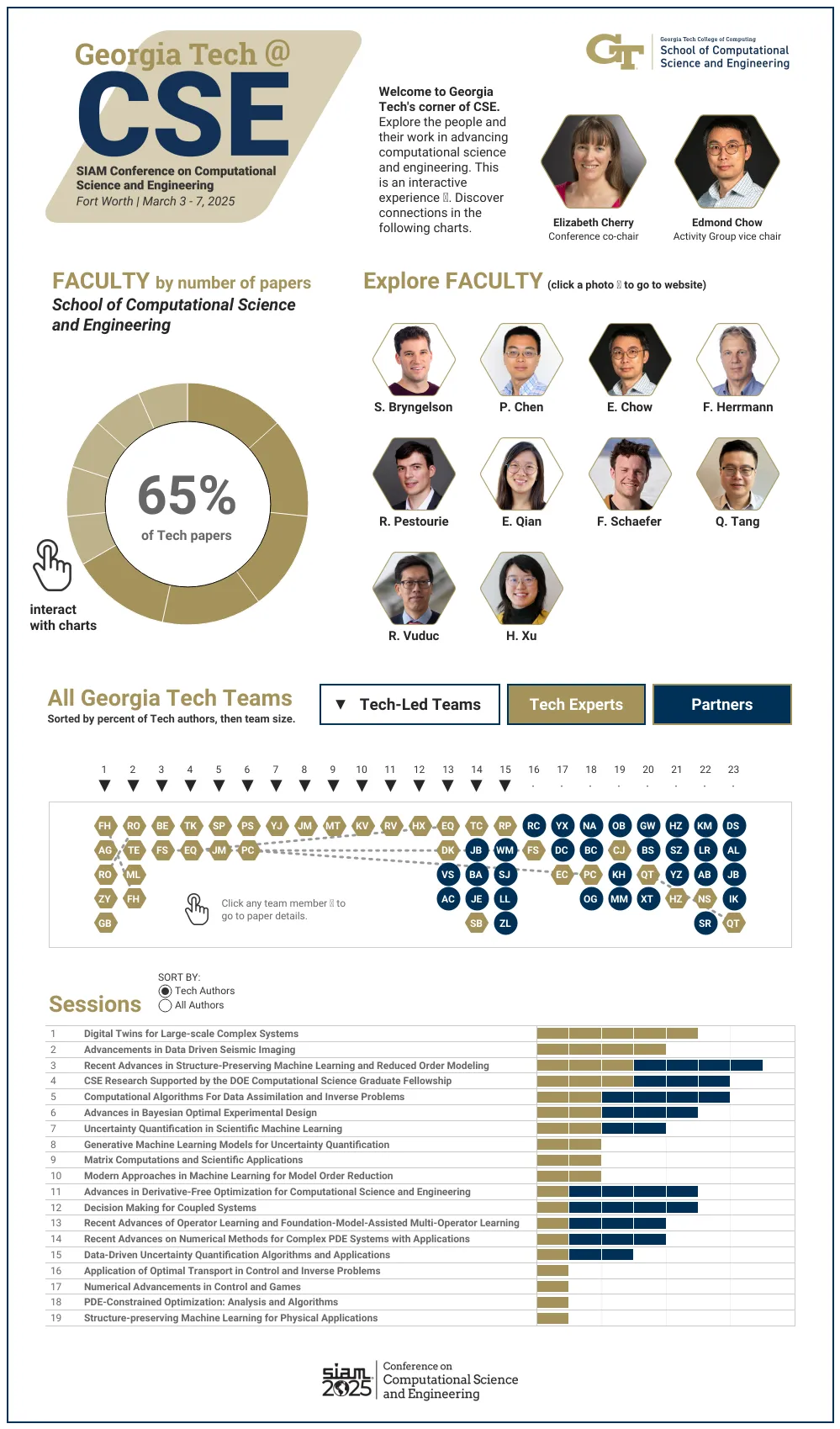
Many communities rely on insights from computer-based models and simulations. This week, a nest of Georgia Tech experts are swarming an international conference to present their latest advancements in these tools, which offer solutions to pressing challenges in science and engineering.
Students and faculty from the School of Computational Science and Engineering (CSE) are leading the Georgia Tech contingent at the SIAM Conference on Computational Science and Engineering (CSE25). The Society of Industrial and Applied Mathematics (SIAM) organizes CSE25, occurring March 3-7 in Fort Worth, Texas.
At CSE25, the School of CSE researchers are presenting papers that apply computing approaches to varying fields, including:
- Experiment designs to accelerate the discovery of material properties
- Machine learning approaches to model and predict weather forecasting and coastal flooding
- Virtual models that replicate subsurface geological formations used to store captured carbon dioxide
- Optimizing systems for imaging and optical chemistry
- Plasma physics during nuclear fusion reactions
[Related: GT CSE at SIAM CSE25 Interactive Graphic]
“In CSE, researchers from different disciplines work together to develop new computational methods that we could not have developed alone,” said School of CSE Professor Edmond Chow.
“These methods enable new science and engineering to be performed using computation.”
CSE is a discipline dedicated to advancing computational techniques to study and analyze scientific and engineering systems. CSE complements theory and experimentation as modes of scientific discovery.
Held every other year, CSE25 is the primary conference for the SIAM Activity Group on Computational Science and Engineering (SIAG CSE). School of CSE faculty serve in key roles in leading the group and preparing for the conference.
In December, SIAG CSE members elected Chow to a two-year term as the group’s vice chair. This election comes after Chow completed a term as the SIAG CSE program director.
School of CSE Associate Professor Elizabeth Cherry has co-chaired the CSE25 organizing committee since the last conference in 2023. Later that year, SIAM members reelected Cherry to a second, three-year term as a council member at large.
At Georgia Tech, Chow serves as the associate chair of the School of CSE. Cherry, who recently became the associate dean for graduate education of the College of Computing, continues as the director of CSE programs.
“With our strong emphasis on developing and applying computational tools and techniques to solve real-world problems, researchers in the School of CSE are well positioned to serve as leaders in computational science and engineering both within Georgia Tech and in the broader professional community,” Cherry said.
Georgia Tech’s School of CSE was first organized as a division in 2005, becoming one of the world’s first academic departments devoted to the discipline. The division reorganized as a school in 2010 after establishing the flagship CSE Ph.D. and M.S. programs, hiring nine faculty members, and attaining substantial research funding.
Ten School of CSE faculty members are presenting research at CSE25, representing one-third of the School’s faculty body. Of the 23 accepted papers written by Georgia Tech researchers, 15 originate from School of CSE authors.
The list of School of CSE researchers, paper titles, and abstracts includes:
Bayesian Optimal Design Accelerates Discovery of Material Properties from Bubble Dynamics
Postdoctoral Fellow Tianyi Chu, Joseph Beckett, Bachir Abeid, and Jonathan Estrada (University of Michigan), Assistant Professor Spencer Bryngelson
[Abstract]
Latent-EnSF: A Latent Ensemble Score Filter for High-Dimensional Data Assimilation with Sparse Observation Data
Ph.D. student Phillip Si, Assistant Professor Peng Chen
[Abstract]
A Goal-Oriented Quadratic Latent Dynamic Network Surrogate Model for Parameterized Systems
Yuhang Li, Stefan Henneking, Omar Ghattas (University of Texas at Austin), Assistant Professor Peng Chen
[Abstract]
Posterior Covariance Structures in Gaussian Processes
Yuanzhe Xi (Emory University), Difeng Cai (Southern Methodist University), Professor Edmond Chow
[Abstract]
Robust Digital Twin for Geological Carbon Storage
Professor Felix Herrmann, Ph.D. student Abhinav Gahlot, alumnus Rafael Orozco (Ph.D. CSE-CSE 2024), alumnus Ziyi (Francis) Yin (Ph.D. CSE-CSE 2024), and Ph.D. candidate Grant Bruer
[Abstract]
Industry-Scale Uncertainty-Aware Full Waveform Inference with Generative Models
Rafael Orozco, Ph.D. student Tuna Erdinc, alumnus Mathias Louboutin (Ph.D. CS-CSE 2020), and Professor Felix Herrmann
[Abstract]
Optimizing Coupled Systems: Insights from Co-Design Imaging and Optical Chemistry
Assistant Professor Raphaël Pestourie, Wenchao Ma and Steven Johnson (MIT), Lu Lu (Yale University), Zin Lin (Virginia Tech)
[Abstract]
Multifidelity Linear Regression for Scientific Machine Learning from Scarce Data
Assistant Professor Elizabeth Qian, Ph.D. student Dayoung Kang, Vignesh Sella, Anirban Chaudhuri and Anirban Chaudhuri (University of Texas at Austin)
[Abstract]
LyapInf: Data-Driven Estimation of Stability Guarantees for Nonlinear Dynamical Systems
Ph.D. candidate Tomoki Koike and Assistant Professor Elizabeth Qian
[Abstract]
The Information Geometric Regularization of the Euler Equation
Alumnus Ruijia Cao (B.S. CS 2024), Assistant Professor Florian Schäfer
[Abstract]
Maximum Likelihood Discretization of the Transport Equation
Ph.D. student Brook Eyob, Assistant Professor Florian Schäfer
[Abstract]
Intelligent Attractors for Singularly Perturbed Dynamical Systems
Daniel A. Serino (Los Alamos National Laboratory), Allen Alvarez Loya (University of Colorado Boulder), Joshua W. Burby, Ioannis G. Kevrekidis (Johns Hopkins University), Assistant Professor Qi Tang (Session Co-Organizer)
[Abstract]
Accurate Discretizations and Efficient AMG Solvers for Extremely Anisotropic Diffusion Via Hyperbolic Operators
Golo Wimmer, Ben Southworth, Xianzhu Tang (LANL), Assistant Professor Qi Tang
[Abstract]
Randomized Linear Algebra for Problems in Graph Analytics
Professor Rich Vuduc
[Abstract]
Improving Spgemm Performance Through Reordering and Cluster-Wise Computation
Assistant Professor Helen Xu
[Abstract]
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Mar. 14, 2025


Successful test results of a new machine learning (ML) technique developed at Georgia Tech could help communities prepare for extreme weather and coastal flooding. The approach could also be applied to other models that predict how natural systems impact society.
Ph.D. student Phillip Si and Assistant Professor Peng Chen developed Latent-EnSF, a technique that improves how ML models assimilate data to make predictions.
In experiments predicting medium-range weather forecasting and shallow water wave propagation, Latent-EnSF demonstrated higher accuracy, faster convergence, and greater efficiency than existing methods for sparse data assimilation.
“We are currently involved in an NSF-funded project aimed at providing real-time information on extreme flooding events in Pinellas County, Florida,” said Si, who studies computational science and engineering (CSE).
“We're actively working on integrating Latent-EnSF into the system, which will facilitate accurate and synchronized modeling of natural disasters. This initiative aims to enhance community preparedness and safety measures in response to flooding risks.”
Latent-EnSF outperformed three comparable models in assimilation speed, accuracy, and efficiency in shallow water wave propagation experiments. These tests show models can make better and faster predictions of coastal flood waves, tides, and tsunamis.
In experiments on medium-range weather forecasting, Latent-EnSF surpassed the same three control models in accuracy, convergence, and time. Additionally, this test demonstrated Latent-EnSF's scalability compared to other methods.
These promising results support using ML models to simulate climate, weather, and other complex systems.
Traditionally, such studies require employment of large, energy-intensive supercomputers. However, advances like Latent-EnSF are making smaller, more efficient ML models feasible for these purposes.
The Georgia Tech team mentioned this comparison in its paper. It takes hours for the European Center for Medium-Range Weather Forecasts computer to run its simulations. Conversely, the ML model FourCastNet calculated the same forecast in seconds.
“Resolution, complexity, and data-diversity will continue to increase into the future,” said Chen, an assistant professor in the School of CSE.
“To keep pace with this trend, we believe that ML models and ML-based data assimilation methods will become indispensable for studying large-scale complex systems.”
Data assimilation is the process by which models continuously ingest new, real-world data to update predictions. This data is often sparse, meaning it is limited, incomplete, or unevenly distributed over time.
Latent-EnSF builds on the Ensemble Filter Scores (EnSF) model developed by Florida State University and Oak Ridge National Laboratory researchers.
EnSF’s strength is that it assimilates data with many features and unpredictable relationships between data points. However, integrating sparse data leads to lost information and knowledge gaps in the model. Also, such large models may stop learning entirely from small amounts of sparse data.
The Georgia Tech researchers employ two variational autoencoders (VAEs) in Latent-EnSF to help ML models integrate and use real-world data. The VAEs encode sparse data and predictive models together in the same space to assimilate data more accurately and efficiently.
Integrating models with new methods, like Latent-EnSF, accelerates data assimilation. Producing accurate predictions more quickly during real-world crises could save lives and property for communities.
To share Latent-EnSF to the broader research community, Chen and Si presented their paper at the SIAM Conference on Computational Science and Engineering (CSE25). The Society of Industrial and Applied Mathematics (SIAM) organized CSE25, held March 3-7 in Fort Worth, Texas.
Chen was one of ten School of CSE faculty members who presented research at CSE25, representing one-third of the School’s faculty body. Latent-EnSF was one of 15 papers by School of CSE authors and one of 23 Georgia Tech papers presented at the conference.
The pair will also present Latent-EnSF at the upcoming International Conference on Learning Representations (ICLR 2025). Occurring April 24-28 in Singapore, ICLR is one of the world’s most prestigious conferences dedicated to artificial intelligence research.
“We hope to bring attention to experts and domain scientists the exciting area of ML-based data assimilation by presenting our paper,” Chen said. “Our work offers a new solution to address some of the key shortcomings in the area for broader applications.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Mar. 06, 2025
Many communities rely on insights from computer-based models and simulations. This week, a nest of Georgia Tech experts are swarming an international conference to present their latest advancements in these tools, which offer solutions to pressing challenges in science and engineering.
Students and faculty from the School of Computational Science and Engineering (CSE) are leading the Georgia Tech contingent at the SIAM Conference on Computational Science and Engineering (CSE25). The Society of Industrial and Applied Mathematics (SIAM) organizes CSE25, occurring March 3-7 in Fort Worth, Texas.
At CSE25, the School of CSE researchers are presenting papers that apply computing approaches to varying fields, including:
- Experiment designs to accelerate the discovery of material properties
- Machine learning approaches to model and predict weather forecasting and coastal flooding
- Virtual models that replicate subsurface geological formations used to store captured carbon dioxide
- Optimizing systems for imaging and optical chemistry
- Plasma physics during nuclear fusion reactions
[Related: GT CSE at SIAM CSE25 Interactive Graphic]
“In CSE, researchers from different disciplines work together to develop new computational methods that we could not have developed alone,” said School of CSE Professor Edmond Chow.
“These methods enable new science and engineering to be performed using computation.”
CSE is a discipline dedicated to advancing computational techniques to study and analyze scientific and engineering systems. CSE complements theory and experimentation as modes of scientific discovery.
Held every other year, CSE25 is the primary conference for the SIAM Activity Group on Computational Science and Engineering (SIAG CSE). School of CSE faculty serve in key roles in leading the group and preparing for the conference.
In December, SIAG CSE members elected Chow to a two-year term as the group’s vice chair. This election comes after Chow completed a term as the SIAG CSE program director.
School of CSE Associate Professor Elizabeth Cherry has co-chaired the CSE25 organizing committee since the last conference in 2023. Later that year, SIAM members reelected Cherry to a second, three-year term as a council member at large.
At Georgia Tech, Chow serves as the associate chair of the School of CSE. Cherry, who recently became the associate dean for graduate education of the College of Computing, continues as the director of CSE programs.
“With our strong emphasis on developing and applying computational tools and techniques to solve real-world problems, researchers in the School of CSE are well positioned to serve as leaders in computational science and engineering both within Georgia Tech and in the broader professional community,” Cherry said.
Georgia Tech’s School of CSE was first organized as a division in 2005, becoming one of the world’s first academic departments devoted to the discipline. The division reorganized as a school in 2010 after establishing the flagship CSE Ph.D. and M.S. programs, hiring nine faculty members, and attaining substantial research funding.
Ten School of CSE faculty members are presenting research at CSE25, representing one-third of the School’s faculty body. Of the 23 accepted papers written by Georgia Tech researchers, 15 originate from School of CSE authors.
The list of School of CSE researchers, paper titles, and abstracts includes:
Bayesian Optimal Design Accelerates Discovery of Material Properties from Bubble Dynamics
Postdoctoral Fellow Tianyi Chu, Joseph Beckett, Bachir Abeid, and Jonathan Estrada (University of Michigan), Assistant Professor Spencer Bryngelson
[Abstract]
Latent-EnSF: A Latent Ensemble Score Filter for High-Dimensional Data Assimilation with Sparse Observation Data
Ph.D. student Phillip Si, Assistant Professor Peng Chen
[Abstract]
A Goal-Oriented Quadratic Latent Dynamic Network Surrogate Model for Parameterized Systems
Yuhang Li, Stefan Henneking, Omar Ghattas (University of Texas at Austin), Assistant Professor Peng Chen
[Abstract]
Posterior Covariance Structures in Gaussian Processes
Yuanzhe Xi (Emory University), Difeng Cai (Southern Methodist University), Professor Edmond Chow
[Abstract]
Robust Digital Twin for Geological Carbon Storage
Professor Felix Herrmann, Ph.D. student Abhinav Gahlot, alumnus Rafael Orozco (Ph.D. CSE-CSE 2024), alumnus Ziyi (Francis) Yin (Ph.D. CSE-CSE 2024), and Ph.D. candidate Grant Bruer
[Abstract]
Industry-Scale Uncertainty-Aware Full Waveform Inference with Generative Models
Rafael Orozco, Ph.D. student Tuna Erdinc, alumnus Mathias Louboutin (Ph.D. CS-CSE 2020), and Professor Felix Herrmann
[Abstract]
Optimizing Coupled Systems: Insights from Co-Design Imaging and Optical Chemistry
Assistant Professor Raphaël Pestourie, Wenchao Ma and Steven Johnson (MIT), Lu Lu (Yale University), Zin Lin (Virginia Tech)
[Abstract]
Multifidelity Linear Regression for Scientific Machine Learning from Scarce Data
Assistant Professor Elizabeth Qian, Ph.D. student Dayoung Kang, Vignesh Sella, Anirban Chaudhuri and Anirban Chaudhuri (University of Texas at Austin)
[Abstract]
LyapInf: Data-Driven Estimation of Stability Guarantees for Nonlinear Dynamical Systems
Ph.D. candidate Tomoki Koike and Assistant Professor Elizabeth Qian
[Abstract]
The Information Geometric Regularization of the Euler Equation
Alumnus Ruijia Cao (B.S. CS 2024), Assistant Professor Florian Schäfer
[Abstract]
Maximum Likelihood Discretization of the Transport Equation
Ph.D. student Brook Eyob, Assistant Professor Florian Schäfer
[Abstract]
Intelligent Attractors for Singularly Perturbed Dynamical Systems
Daniel A. Serino (Los Alamos National Laboratory), Allen Alvarez Loya (University of Colorado Boulder), Joshua W. Burby, Ioannis G. Kevrekidis (Johns Hopkins University), Assistant Professor Qi Tang (Session Co-Organizer)
[Abstract]
Accurate Discretizations and Efficient AMG Solvers for Extremely Anisotropic Diffusion Via Hyperbolic Operators
Golo Wimmer, Ben Southworth, Xianzhu Tang (LANL), Assistant Professor Qi Tang
[Abstract]
Randomized Linear Algebra for Problems in Graph Analytics
Professor Rich Vuduc
[Abstract]
Improving Spgemm Performance Through Reordering and Cluster-Wise Computation
Assistant Professor Helen Xu
[Abstract]
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Feb. 17, 2025

Men and women in California put their lives on the line when battling wildfires every year, but there is a future where machines powered by artificial intelligence are on the front lines, not firefighters.
However, this new generation of self-thinking robots would need security protocols to ensure they aren’t susceptible to hackers. To integrate such robots into society, they must come with assurances that they will behave safely around humans.
It begs the question: can you guarantee the safety of something that doesn’t exist yet? It’s something Assistant Professor Glen Chou hopes to accomplish by developing algorithms that will enable autonomous systems to learn and adapt while acting with safety and security assurances.
He plans to launch research initiatives, in collaboration with the School of Cybersecurity and Privacy and the Daniel Guggenheim School of Aerospace Engineering, to secure this new technological frontier as it develops.
“To operate in uncertain real-world environments, robots and other autonomous systems need to leverage and adapt a complex network of perception and control algorithms to turn sensor data into actions,” he said. “To obtain realistic assurances, we must do a joint safety and security analysis on these sensors and algorithms simultaneously, rather than one at a time.”
This end-to-end method would proactively look for flaws in the robot’s systems rather than wait for them to be exploited. This would lead to intrinsically robust robotic systems that can recover from failures.
Chou said this research will be useful in other domains, including advanced space exploration. If a space rover is sent to one of Saturn’s moons, for example, it needs to be able to act and think independently of scientists on Earth.
Aside from fighting fires and exploring space, this technology could perform maintenance in nuclear reactors, automatically maintain the power grid, and make autonomous surgery safer. It could also bring assistive robots into the home, enabling higher standards of care.
This is a challenging domain where safety, security, and privacy concerns are paramount due to frequent, close contact with humans.
This will start in the newly established Trustworthy Robotics Lab at Georgia Tech, which Chou directs. He and his Ph.D. students will design principled algorithms that enable general-purpose robots and autonomous systems to operate capably, safely, and securely with humans while remaining resilient to real-world failures and uncertainty.
Chou earned dual bachelor’s degrees in electrical engineering and computer sciences as well as mechanical engineering from University of California Berkeley in 2017, a master’s and Ph.D. in electrical and computer engineering from the University of Michigan in 2019 and 2022, respectively. He was a postdoc at MIT Computer Science & Artificial Intelligence Laboratory prior to joining Georgia Tech in November 2024. He is a recipient of the National Defense Science and Engineering Graduate fellowship program, NSF Graduate Research fellowships, and was named a Robotics: Science and Systems Pioneer in 2022.
News Contact
John (JP) Popham
Communications Officer II
College of Computing | School of Cybersecurity and Privacy
Feb. 06, 2025
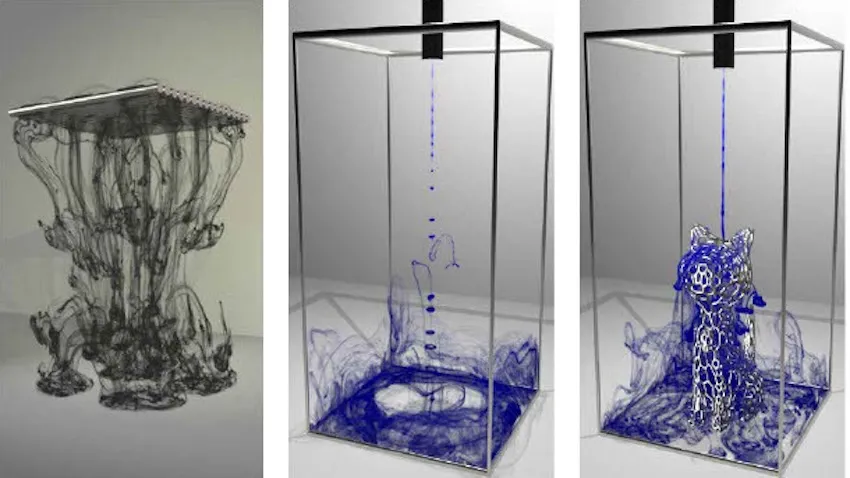
Calculating and visualizing a realistic trajectory of ink spreading through water has been a longstanding and enormous challenge for computer graphics and physics researchers.
When a drop of ink hits the water, it typically sinks forward, creating a tail before various ink streams branch off in different directions. The motion of the ink’s molecules upon mixing with water is seemingly random. This is because the motion is determined by the interaction of the water’s viscosity (thickness) and vorticity (how much it rotates at a given point).
“If the water is more viscous, there will be fewer branches. If the water is less viscous, it will have more branches,” said Zhiqi Li, a graduate computer science student.
Li is the lead author of Particle-Laden Fluid on Flow Maps, a best paper winner at the December 2024 ACM SIGGRAPH Asia conference. Assistant Professor Bo Zhu advises Li and is the co-author of six papers accepted to the conference.
Zhu said they must correctly calculate and simulate the interaction between viscosity and vorticity before they can accurately predict the ink trajectory.
“The ink branches generate based on the intricate interaction between the vorticities and the viscosity over time, which we simulated,” Zhu said. “Using a standard method to simulate the physics will cause most of the structures to fade quickly without being able to see any detailed hierarchies.”
Zhu added that researchers had yet to develop a method for this until he and his co-authors proposed a new way to solve the equation. Their breakthrough has unlocked the most accurate simulations of ink diffusion to date.
“Ink diffusion is one of the most visually striking examples of particle-laden flow,” Zhu said.
“We introduce a new viscosity model that solves for the interaction between vorticity and viscosity from a particle flow map perspective. This new simulation lets you map physical quantities from a certain time frame, allowing us to see particle trajectory.”
In computer simulations, flow is the digital visualization of a gas or liquid through a system. Users can simulate these liquids and gases through different scenarios and study pressure, velocity, and temperature.
A particle-laden flow depicts solid particles mixing within a continuous fluid phase, such as dust or water sediment. A flow map traces particle motion from the start point to the endpoint.
Duowen Chen, a computer science Ph.D. student also advised by Zhu and co-author of the paper, said previous efforts by researchers to simulate ink diffusion depended on guesswork. They either used limited traditional methods of calculations or artificial designs.
“They add in a noise model or an artificial model to create vortical motions, but our method does not require adding any artificial vortical components,” Chen said. “We have a better viscosity force calculation and vortical preservation, and the two give a better ink simulation.”
Zhu also won a best paper award at the 2023 SIGGRAPH Asia conference for his work explaining how neural network maps created through artificial intelligence (AI) could close the gaps of difficult-to-solve equations. In his new paper, he said it was essential to find a way to simulate ink diffusion accurately independent of AI.
“If we don’t have to train a large-scale neural network, then the computation time will be much faster, and we can reduce the computation and memory costs,” Zhu said. “The particle flow map representation can preserve those particle structures better than the neural network version, and they are a widely used data structure in traditional physics-based simulation.”
News Contact
Ben Snedeker, Communications Manager
Georgia Tech College of Computing
albert.snedeker@cc.gtaech.edu
Jan. 16, 2025

A researcher in Georgia Tech’s School of Interactive Computing has received the nation’s highest honor given to early career scientists and engineers.
Associate Professor Josiah Hester was one of 400 people awarded the Presidential Early Career Award for Scientists and Engineers (PECASE), the Biden Administration announced in a press release on Tuesday.
The PECASE winners’ research projects are funded by government organizations, including the National Science Foundation (NSF), the National Institutes of Health (NIH), the Centers for Disease Control and Prevention (CDC), and NASA. They will be invited to visit the White House later this year.
Hester joins Associate Professor Juan-Pablo Correa-Baena from the School of Materials Science and Engineering as the two Tech faculty who received the honor.
Hester said his nomination was based on the NSF Faculty Early Career Development Program (CAREER) award he received in 2022 as an assistant professor at Northwestern University. He said the NSF submits its nominations to the White House for the PECASE awards, but researchers are not informed until the list of winners is announced.
“For me, I always thought this was an unachievable, unassailable type of thing because of the reputation of the folks in computing who’ve won previously,” Hester said. “It was always a far-reaching goal. I was shocked. It’s something you would never in a million years think you would win.”
Hester is known for pioneering research in a new subfield of sustainable computing dedicated to creating battery-free devices powered by solar energy, kinetic energy, and radio waves. He co-led a team that developed the first battery-free handheld gaming device.
Last year, Hester co-authored an article published in the Association of Computing Machinery’s in-house journal, the Communications of the ACM, in which he coined the term “Internet of Battery-less Things.”
The Internet of Things is the network of physical computing devices capable of connecting to the internet and exchanging data. However, these devices eventually die. Landfills are overflowing with billions of them and their toxic power cells, harming our ecosystem.
In his CAREER award, Hester outlined projects that would work toward replacing the most used computing devices with sustainable, battery-free alternatives.
“I want everything to be an Internet of Batteryless Things — computational devices that could last forever,” Hester said. “I outlined a bunch of different ways that you could do that from the computer engineering side and a little bit from the human-computer interaction side. They all had a unifying theme of making computing more sustainable and climate-friendly.”
Hester is also a Sloan Research Fellow, an honor he received in 2022. In 2021, Popular Sciene named him to its Brilliant 10 list. He also received the Most Promising Engineer or Scientist Award from the American Indian Science Engineering Society, which recognizes significant contributions from the indigenous peoples of North America and the Pacific Islands in STEM disciplines.
President Bill Clinton established PECASE in 1996. The White House press release recognizes exceptional scientists and engineers who demonstrate leadership early in their careers and present innovative and far-reaching developments in science and technology.
News Contact
NATHAN DEEN
COMMUNICATIONS OFFICER
SCHOOL OF INTERACTIVE COMPUTING