Jul. 15, 2024

Professor Jun Ueda in the George W. Woodruff School of Mechanical Engineering and robotics Ph.D. student Heriberto Nieves.
Hepatic, or liver, disease affects more than 100 million people in the U.S. About 4.5 million adults (1.8%) have been diagnosed with liver disease, but it is estimated that between 80 and 100 million adults in the U.S. have undiagnosed fatty liver disease in varying stages. Over time, undiagnosed and untreated hepatic diseases can lead to cirrhosis, a severe scarring of the liver that cannot be reversed.
Most hepatic diseases are chronic conditions that will be present over the life of the patient, but early detection improves overall health and the ability to manage specific conditions over time. Additionally, assessing patients over time allows for effective treatments to be adjusted as necessary. The standard protocol for diagnosis, as well as follow-up tissue assessment, is a biopsy after the return of an abnormal blood test, but biopsies are time-consuming and pose risks for the patient. Several non-invasive imaging techniques have been developed to assess the stiffness of liver tissue, an indication of scarring, including magnetic resonance elastography (MRE).
MRE combines elements of ultrasound and MRI imaging to create a visual map showing gradients of stiffness throughout the liver and is increasingly used to diagnose hepatic issues. MRE exams, however, can fail for many reasons, including patient motion, patient physiology, imaging issues, and mechanical issues such as improper wave generation or propagation in the liver. Determining the success of MRE exams depends on visual inspection of technologists and radiologists. With increasing work demands and workforce shortages, providing an accurate, automated way to classify image quality will create a streamlined approach and reduce the need for repeat scans.
Professor Jun Ueda in the George W. Woodruff School of Mechanical Engineering and robotics Ph.D. student Heriberto Nieves, working with a team from the Icahn School of Medicine at Mount Sinai, have successfully applied deep learning techniques for accurate, automated quality control image assessment. The research, “Deep Learning-Enabled Automated Quality Control for Liver MR Elastography: Initial Results,” was published in the Journal of Magnetic Resonance Imaging.
Using five deep learning training models, an accuracy of 92% was achieved by the best-performing ensemble on retrospective MRE images of patients with varied liver stiffnesses. The team also achieved a return of the analyzed data within seconds. The rapidity of image quality return allows the technician to focus on adjusting hardware or patient orientation for re-scan in a single session, rather than requiring patients to return for costly and timely re-scans due to low-quality initial images.
This new research is a step toward streamlining the review pipeline for MRE using deep learning techniques, which have remained unexplored compared to other medical imaging modalities. The research also provides a helpful baseline for future avenues of inquiry, such as assessing the health of the spleen or kidneys. It may also be applied to automation for image quality control for monitoring non-hepatic conditions, such as breast cancer or muscular dystrophy, in which tissue stiffness is an indicator of initial health and disease progression. Ueda, Nieves, and their team hope to test these models on Siemens Healthineers magnetic resonance scanners within the next year.
Publication
Nieves-Vazquez, H.A., Ozkaya, E., Meinhold, W., Geahchan, A., Bane, O., Ueda, J. and Taouli, B. (2024), Deep Learning-Enabled Automated Quality Control for Liver MR Elastography: Initial Results. J Magn Reson Imaging. https://doi.org/10.1002/jmri.29490
Prior Work
Robotically Precise Diagnostics and Therapeutics for Degenerative Disc Disorder
Related Material
Editorial for “Deep Learning-Enabled Automated Quality Control for Liver MR Elastography: Initial Results”
News Contact
Christa M. Ernst |
Research Communications Program Manager |
Topic Expertise: Robotics, Data Sciences, Semiconductor Design & Fab |
Jul. 15, 2024

Time is winding down on Olympic organizers’ plans to stage open-water swimming events in Paris’ iconic Seine River later this month. The city spent $1.5 billion on new infrastructure to clean up the Seine, yet water samples continue to show high levels of potentially toxic E. coli.
The river has been closed to swimmers for the past 100 years because of pollution, but Olympic organizers hope to stage the triathlon and marathon swimming events in the water flowing in the shadow of the Eiffel Tower.
Katherine Graham has followed the saga in Paris. She’s an assistant professor in the Georgia Tech School of Civil and Environmental Engineering who studies the fate and transport of pathogens and their indicators in water, including E. coli. She said several factors are at play in the Seine.
“Paris, like most large cities, has a lot of concrete and not much dirt and grass for water to soak into."
Read the entire story on the College of Engineering website.
News Contact
Jason Maderer
College of Engineering
maderer@gatech.edu
Jul. 11, 2024


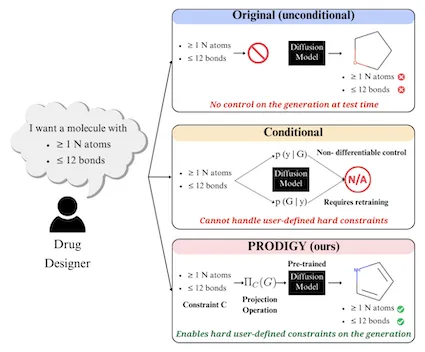
New research from Georgia Tech is giving scientists more control options over generative artificial intelligence (AI) models in their studies. Greater customization from this research can lead to discovery of new drugs, materials, and other applications tailor-made for consumers.
The Tech group dubbed its method PRODIGY (PROjected DIffusion for controlled Graph Generation). PRODIGY enables diffusion models to generate 3D images of complex structures, such as molecules from chemical formulas.
Scientists in pharmacology, materials science, social network analysis, and other fields can use PRODIGY to simulate large-scale networks. By generating 3D molecules from multiple graph datasets, the group proved that PRODIGY could handle complex structures.
In keeping with its name, PRODIGY is the first plug-and-play machine learning (ML) approach to controllable graph generation in diffusion models. This method overcomes a known limitation inhibiting diffusion models from broad use in science and engineering.
“We hope PRODIGY enables drug designers and scientists to generate structures that meet their precise needs,” said Kartik Sharma, lead researcher on the project. “It should also inspire future innovations to precisely control modern generative models across domains.”
PRODIGY works on diffusion models, a generative AI model for computer vision tasks. While suitable for image creation and denoising, diffusion methods are limited because they cannot accurately generate graph representations of custom parameters a user provides.
PRODIGY empowers any pre-trained diffusion model for graph generation to produce graphs that meet specific, user-given constraints. This capability means, as an example, that a drug designer could use any diffusion model to design a molecule with a specific number of atoms and bonds.
The group tested PRODIGY on two molecular and five generic datasets to generate custom 2D and 3D structures. This approach ensured the method could create such complex structures, accounting for the atoms, bonds, structures, and other properties at play in molecules.
Molecular generation experiments with PRODIGY directly impact chemistry, biology, pharmacology, materials science, and other fields. The researchers say PRODIGY has potential in other fields using large networks and datasets, such as social sciences and telecommunications.
These features led to PRODIGY’s acceptance for presentation at the upcoming International Conference on Machine Learning (ICML 2024). ICML 2024 is the leading international academic conference on ML. The conference is taking place July 21-27 in Vienna.
Assistant Professor Srijan Kumar is Sharma’s advisor and paper co-author. They worked with Tech alumnus Rakshit Trivedi (Ph.D. CS 2020), a Massachusetts Institute of Technology postdoctoral associate.
Twenty-four Georgia Tech faculty from the Colleges of Computing and Engineering will present 40 papers at ICML 2024. Kumar is one of six faculty representing the School of Computational Science and Engineering (CSE) at the conference.
Sharma is a fourth-year Ph.D. student studying computer science. He researches ML models for structured data that are reliable and easily controlled by users. While preparing for ICML, Sharma has been interning this summer at Microsoft Research in the Research for Industry lab.
“ICML is the pioneering conference for machine learning,” said Kumar. “A strong presence at ICML from Georgia Tech illustrates the ground-breaking research conducted by our students and faculty, including those in my research group.”
Visit https://sites.gatech.edu/research/icml-2024 for news and coverage of Georgia Tech research presented at ICML 2024.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Jul. 11, 2024

A new data visualization tool designed by a Georgia Tech Ph.D. student is helping a team of microbial ecologists, geobiologists, and oceanographers gain more insight into how deep-sea microorganisms interact within their environment.
What began as an internship at NASA turned into a unique opportunity for fourth-year Ph.D. student Adam Coscia. Coscia worked under the supervision of an interdisciplinary team of collaborative researchers from Caltech, the Jet Propulsion Laboratory (JPL) Caltech manages for NASA and the ArtCenter College of Design.
Coscia’s mentors recommended him to a Caltech research team led by Victoria Orphan, a renowned microbial ecologist who studies microbial communities in the ocean and how they function within habitats in deep seafloor sediments.
Orphan and her team, the Orphan Lab at Caltech, have conducted their research since 2004. They recently decided to take a data visualization approach to record their findings and plan future expeditions.
“Historically, our data sets have been discrete and have lived in separate Excel spreadsheets,” Orphan said. “Maybe at the end, we’ll do some statistical analysis to find correlations in that data. Then we compare those to our maps. We didn’t have a way of consolidating everything under one umbrella that allows us to learn more about these ecosystems.”
Orphan said her team typically takes one or two research expeditions off the California coast annually. They spend three weeks using remotely operated vehicles (ROVs) to collect sediment samples from the ocean floor. Because time is at a premium, identifying the locations of the best samples is crucial.
Orphan is also an adjunct scientist at the Monterey Bay Aquarium Research Institute (MBARI) and works with the Seafloor Mapping Lab. The lab uses an ROV-mounted low-altitude survey system to produce detailed maps of seafloor topography.
To help the Orphan Lab work effectively with topographic and photographic data, Coscia designed DeepSee, an interactive web browser that can annotate and chart data using 3D visualization models and environmental maps.
“The idea is once you have the samples, and you’re interested in a specific area with prior samples, you can go in and annotate on the map where to collect samples next with our drawing tool,” Coscia said.
“We focused on the exploration and notetaking process with maps and data and having new ways of visualizing it. Scientists can draw and map out all their samples in real time. They can reference specific data much easier and determine where the team should go to get the best samples.”
The Orphan Lab has taken DeepSee live onboard its ship for its two most recent expeditions. Orphan has noticed an increased efficiency in expedition planning.
“The infrastructure put in place by Adam will make this an enabling tool not only for my group but for other oceanographers and scientists in other fields — anywhere there is a spatial distribution of information you want to connect to other metadata,” she said.
Orphan brings new researchers into her lab at Caltech every year, and DeepSee has accelerated the process of getting newcomers up to speed.
“We can onboard them much easier and give them a sense of what data is available and where we’ve collected information in a way that’s much clearer than having them refer to an Excel spreadsheet,” she said.
DeepSee also creates 3D data models under the sea floor using data interpolation, which estimates new data points based on the range of a set of known data points. Using the known data points, DeepSee fills in the blanks of the estimated data quality the researchers may find in nearby locations or further underneath the surface where samples were collected.
“You would never see anything visually below the sea floor,” Coscia said. “You’d have to go dig. But our 3D models show you that you might have data suggesting a hotspot just a few feet below the floor. That tells you where to sample next.”
Coscia aims to incorporate machine learning (ML) models into a future version of DeepSee that will use collected data to predict future sites for sampling. However, ML model accuracy requires significantly more data.
Coscia hopes the current version of the tool catches on so researchers can more easily incorporate machine learning into their work.
For now, the current version has plenty of uses, he said.
“Being able to organize and see your data, especially with maps, is always valuable,” he said. “My passion is helping researchers and scientists see their data in new and valuable ways.”
Coscia authored a paper on developing DeepSee, which he presented in May at the Conference on Human Factors in Computing Systems (CHI) in Honolulu, Hawaii.
News Contact
Nathan Deen
Communications Officer
Georgia Tech School of Interactive Computing
nathan.deen@cc.gatech.edu
Jun. 04, 2024

Artificial intelligence and machine learning techniques are infused across the College of Engineering’s education and research.
From safer roads to new fuel cell technology, semiconductor designs to restoring bodily functions, Georgia Tech engineers are capitalizing on the power of AI to quickly make predictions or see danger ahead.
Explore some of the ways we are using AI to create a better future on the College's website.
This story was featured in the spring 2024 issue of Helluva Engineer magazine, produced biannually by the College of Engineering.
News Contact
Joshua Stewart
College of Engineering
Jun. 04, 2024

It’s tempting to think that the artificial intelligence revolution is coming — for good or ill — and that AI will soon be baked into every facet of our lives. With generative AI tools suddenly available to anyone and seemingly every company scrambling to leverage AI for their business, it can feel like the AI-dominated future is just over the horizon.
The truth is, that future is already here. Most of us just didn’t notice.
Every time you unlock your smartphone or computer with a face scan or fingerprint. Every time your car alerts you that you’re straying from your lane or automatically adjusts your cruise control speed. Every time you ask Siri for directions or Alexa to turn on some music. Every time you start typing in the Google search box and suggestions or the outright answer to your question appear. Every time Netflix recommends what you should watch next.
All driven by AI. And all a regular part of most people’s days.
But what is “artificial intelligence”? What about “machine learning” and “algorithms”? How are they different and how do they work?
We asked two of the many Georgia Tech engineers working in these areas to help us understand the basic concepts so we’re all better prepared for the AI future — er, present.
Read the full crash course on the College of Engineering website.
This story was featured in the spring 2024 issue of Helluva Engineer magazine, produced biannually by the College of Engineering.
News Contact
Joshua Stewart
College of Engineering
Jun. 27, 2024

A team’s success in any competitive environment often hinges on how well each member can anticipate the actions of their teammates.
Assistant Professor Christopher MacLellan thinks teachable artificial intelligence (AI) agents are uniquely suited for this role and make ideal teammates for video gamers.
With the help of funding from the U.S. Department of Defense, MacLellan hopes to prove his theory with a conversational, task-performing agent he co-engineered called the Verbal Apprentice Learner (VAL).
“You need the ability to adapt to what your teammates are doing to be an effective teammate,” MacLellan said. “We’re exploring this capability for AI agents in the context of video games.”
Unlike generative AI chatbots like ChatGPT, VAL uses an interactive task-learning approach.
“VAL learns how you do things in the way you want them done,” MacLellan said. “When you tell it to do something, it will do it the way you taught it instead of some generic random way from the internet.”
A key difference between VAL and a chatbot is that VAL can perceive and act within the gaming world. A chatbot, like ChatGPT, only perceives and acts within the chat dialog.
MacLellan immersed VAL into an open-sourced, simplified version of the popular Nintendo cooperative video game Overcooked to discover how well the agent can function as a teammate. In Overcooked, up to four players work together to prepare dishes in a kitchen while earning points for every completed order.
How Fast Can Val Learn?
In a study with 12 participants, MacLellan found that users could often correctly teach VAL new tasks with only a few examples.
First, the user must teach VAL how to play the game. Knowing that a single human error could compromise results, MacLellan designed three precautionary features:
- When VAL receives a command such as "cook an onion," it asks clarifying questions to understand and confirm its task. As VAL continues to learn, clarification prompts decrease.
- An “undo” button to ensure users can reverse an errant command.
- VAL contains GPT subcomponents to interpret user input, allowing it to adapt to ambiguous commands and typos. The GPT subcomponents drive changes in VAL’s task knowledge, which it uses to perform tasks without additional guidance.
The participants in MacLellan’s study used these features to ensure VAL learned the tasks correctly.
The high volume of prompts creates a more tedious experience. Still, MacLellan said it provides detailed data on system performance and user experience. That insight should make designing a more seamless experience in future versions of VAL possible.
The prompts also require the AI to be explainable.
“When VAL learns something, it uses the language model to label each node in the task knowledge graph that the system constructs,” MacLellan said. “You can see what it learned and how it breaks tasks down into actions.”
Beyond Gaming
MacLellan’s Teachable AI Lab is devoted to developing AI that inexperienced users can train.
“We are trying to come up with a more usable system where anyone, including people with limited expertise, could come in and interact with the agent and be able to teach it within just five minutes of interacting with it for the first time,” he said.
His work caught the attention of the Department of Defense, which awarded MacLellan multiple grants to fund several of his projects, including VAL. The possibilities of how the DoD could use VAL, on and off the battlefield, are innumerable.
“(The DoD) envisions a future in which people and AI agents jointly work together to solve problems,” MacLellan said. “You need the ability to adapt to what your teammates are doing to be an effective teammate.
“We look at the dynamics of different teaming circumstances and consider what are the right ways to team AI agents with people. The key hypothesis for our project is agents that can learn on the fly and adapt to their users will make better teammates than those that are pre-trained like GPT.”
Design Your Own Agent
MacLellan is co-organizing a gaming agent design competition sponsored by the Institute of Electrical and Electronic Engineers (IEEE) 2024 Conference on Games in Milan, Italy.
The Dice Adventure Competition invites participants to design their own AI agent to play a multi-player, turn-based dungeon crawling game or to play the game as a human teammate. The competition this month and in July offers $1,000 in prizes for players and agent developers in the top three teams.
News Contact
Nathan Deen
Communications Officer
School of Interactive Computing
Jun. 24, 2024

The Children's Healthcare of Atlanta Pediatric Technology Center at Georgia Tech (PTC) is excited to announce that Gian-Gabriel Garcia will serve as its Pillar 1 Co-Lead. Pillar 1 focuses on data science, machine learning, and artificial intelligence. In his new role, Garcia’s responsibilities will include setting the pillar’s strategy and vision, selecting and managing projects, overseeing various pillar activities, and working collaboratively across research groups and institutions. He will also identify cutting-edge technology and engineering solutions to implement priority projects while balancing the pragmatism and feasibility of these approaches.
The PTC brings clinical experts together with Georgia Tech scientists and engineers to develop technological solutions to problems in the health and care of children. The Center provides extraordinary opportunities for interdisciplinary collaboration in pediatrics, creating breakthrough discoveries that often can only be found at the intersection of multiple disciplines.
Garcia will work under the leadership of PTC Co-Directors Dr. Stanislav Emelianov (Georgia Tech) and Dr. Wilbur Lam (Children’s) of Georgia Tech’s Wallace H. Coulter Department of Biomedical Engineering at Georgia Tech and Emory University. Dr. Naveen Muthu of Children’s Physician Group will be Garcia’s counterpart in leading Pillar 1.
Since 2021, Garcia has served as an assistant professor in Georgia Tech’s H. Milton Stewart School of Industrial and Systems Engineering. His research group has published numerous journal and conference papers, and book chapters related to data-driven machine learning and optimization in healthcare, including various applications in diagnosis and disease management of concussion, opioids, cardiovascular disease, glaucoma, and maternal health. He has received federal funding as a primary investigator from both the National Institutes for Health and the Agency for Healthcare Research and Quality. He and his research group have received several national and international recognitions for their work.
Garcia also teaches graduate-level courses in machine learning and optimization for healthcare. He received his Ph.D. in industrial and operations engineering at the University of Michigan and was a postdoctoral fellow at the MGH Institute for Technology Assessment.
Jun. 21, 2024

Researchers at Georgia Tech are creating accessible museum exhibits that explain artificial intelligence (AI) to middle school students, including the LuminAI interactive AI-based dance partner developed by Regents' Professor Brian Magerko.
Ph.D. students Yasmine Belghith and Atefeh Mahdavi co-led a study in a museum setting that observed how middle schoolers interact with the popular AI chatbot ChatGPT.
“It’s important for museums, especially science museums, to start incorporating these kinds of exhibits about AI and about using AI so the general population can have that avenue to interact with it and transfer that knowledge to everyday tools,” Belghith said.
Belghith and Mahdavi conducted their study with nine focus groups of 24 students at Chicago’s Museum of Science and Industry. The team used the findings to inform their design of AI exhibits that the museum could display as early as 2025.
Belghith is a Ph.D. student in human-centered computing. Her advisor is Assistant Professor Jessica Roberts in the School of Interactive Computing. Magerko advises Mahdavi, a Ph.D. student in digital media in the School of Literature, Media, and Communication.
Belghith and Mahdavi presented a paper about their study in May at the Association for Computing Machinery (ACM) 2024 Conference on Human Factors in Computing Systems (CHI) in Honolulu, Hawaii.
Their work is part of a National Science Foundation (NSF) grant dedicated to fostering AI literacy among middle schoolers in informal environments.
Expanding Accessibility
While there are existing efforts to reach students in the classroom, the researchers believe AI education is most accessible in informal learning environments like museums.
“There’s a need today for everybody to have some sort of AI literacy,” Belghith said. “Many middle schoolers will not be taking computer science courses or pursuing computer science careers, so there needs to be interventions to teach them what they should know about AI.”
The researchers found that most of the middle schoolers interacted with ChatGPT to either test its knowledge by prompting it to answer questions or socialize with it by having human-like conversations.
Others fit the mold of “content explorers.” They did not engage with the AI aspect of ChatGPT and focused more on the content it produced.
Mahdavi said regardless of their approach, students would get “tunnel vision” in their interactions instead of exploring more of the AI’s capabilities.
“If they go in a certain direction, they will continue to explore that,” Mahdavi said. “One thing we can learn from this is to nudge kids and show them there are other things you can do with AI tools or get them to think about it another way.”
The researchers also paid attention to what was missing in the students’ responses, which Mahdavi said was just as important as what they did talk about.
“None of them mentioned anything about ethics or what could be problematic about AI,” she said. “That told us there’s something they aren’t thinking about but should be. We take that into account as we think about future exhibits.”
Making an Impact
The researchers visited the Museum of Science and Industry June 1-2 to conduct the first trial run of three AI-based exhibits they’ve created. One of them is LuminAI, which was developed in Magerko’s Expressive Machinery Lab.
LuminAI is an interactive art installation that allows people to engage in collaborative movement with an AI dance partner. Georgia Tech and Kennesaw State recently held the first performance of AI avatars dancing with human partners in front of a live audience.
Duri Long, a former Georgia Tech Ph.D. student who is now an assistant professor at Northwestern University, designed the second exhibit. KnowledgeNet is an interactive tabletop exhibit in which visitors build semantic networks by adding different characteristics to characters that interact together.
The third exhibit, Data Bites, prompts users to build datasets of pizzas and sandwiches. Their selections train a machine-learning classifier in real time.
Belghith said the exhibits fostered conversations about AI between parents and children.
“The exhibit prototypes successfully engaged children in creative activities,” she said. “Many parents had to pull their kids away to continue their museum tour because the kids wanted more time to try different creations or dance moves.”
News Contact
Nathan Deen
Communications Officer I
School of Interactive Computing
Jun. 12, 2024

Ankur Singh has developed a new way of programming T cells that retains their naïve state, making them better fighters. — Photo by Jerry Grillo

This is an image of a T cell on a nanowire array. The arrow indicates where a nanowire has penetrated the cell, delivering therapeutic miRNA.
Adoptive T-cell therapy has revolutionized medicine. A patient’s T-cells — a type of white blood cell that is part of the body’s immune system — are extracted and modified in a lab and then infused back into the body, to seek and destroy infection, or cancer cells.
Now Georgia Tech bioengineer Ankur Singh and his research team have developed a method to improve this pioneering immunotherapy.
Their solution involves using nanowires to deliver therapeutic miRNA to T-cells. This new modification process retains the cells’ naïve state, which means they’ll be even better disease fighters when they’re infused back into a patient.
“By delivering miRNA in naïve T cells, we have basically prepared an infantry, ready to deploy,” Singh said. “And when these naïve cells are stimulated and activated in the presence of disease, it’s like they’ve been converted into samurais.”
Lean and Mean
Currently in adoptive T-cell therapy, the cells become stimulated and preactivated in the lab when they are modified, losing their naïve state. Singh’s new technique overcomes this limitation. The approach is described in a new study published in the journal Nature Nanotechnology.
“Naïve T-cells are more useful for immunotherapy because they have not yet been preactivated, which means they can be more easily manipulated to adopt desired therapeutic functions,” said Singh, the Carl Ring Family Professor in the Woodruff School of Mechanical Engineering and the Wallace H. Coulter Department of Biomedical Engineering.
The raw recruits of the immune system, naïve T-cells are white blood cells that haven’t been tested in battle yet. But these cellular recruits are robust, impressionable, and adaptable — ready and eager for programming.
“This process creates a well-programmed naïve T-cell ideal for enhancing immune responses against specific targets, such as tumors or pathogens,” said Singh.
The precise programming naïve T-cells receive sets the foundational stage for a more successful disease fighting future, as compared to preactivated cells.
Giving Fighter Cells a Boost
Within the body, naïve T-cells become activated when they receive a danger signal from antigens, which are part of disease-causing pathogens, but they send a signal to T-cells that activate the immune system.
Adoptive T-cell therapy is used against aggressive diseases that overwhelm the body’s defense system. Scientists give the patient’s T-cells a therapeutic boost in the lab, loading them up with additional medicine and chemically preactivating them.
That’s when the cells lose their naïve state. When infused back into the patient, these modified T-cells are an effective infantry against disease — but they are prone to becoming exhausted. They aren’t samurai. Naïve T-cells, though, being the young, programmable recruits that they are, could be.
The question for Singh and his team was: How do we give cells that therapeutic boost without preactivating them, thereby losing that pristine, highly suggestable naïve state? Their answer: Nanowires.
NanoPrecision: The Pointed Solution
Singh wanted to enhance naïve T-cells with a dose of miRNA. miRNA is a molecule that, when used as a therapeutic, works as a kind of volume knob for genes, turning their activity up or down to keep infection and cancer in check. The miRNA for this study was developed in part by the study’s co-author, Andrew Grimson of Cornell University.
“If we could find a way to forcibly enter the cells without damaging them, we could achieve our goal to deliver the miRNA into naïve T cells without preactivating them,” Singh explained.
Traditional modification in the lab involves binding immune receptors to T-cells, enabling the uptake of miRNA or any genetic material (which results in loss of the naïve state). “But nanowires do not engage receptors and thus do not activate cells, so they retain their naïve state,” Singh said.
The nanowires, silicon wafers made with specialized tools at Georgia Tech’s Institute for Electronics and Nanotechnology, form a fine needle bed. Cells are placed on the nanowires, which easily penetrate the cells and deliver their miRNA over several hours. Then the cells with miRNA are flushed out from the tops of the nanowires, activated, eventually infused back into the patient. These programmed cells can kill enemies efficiently over an extended time period.
“We believe this approach will be a real gamechanger for adoptive immunotherapies, because we now have the ability to produce T-cells with predictable fates,” says Brian Rudd, a professor of immunology at Cornell University, and co-senior author of the study with Singh.
The researchers tested their work in two separate infectious disease animal models at Cornell for this study, and Singh described the results as “a robust performance in infection control.”
In the next phase of study, the researchers will up the ante, moving from infectious disease to test their cellular super soldiers against cancer and move toward translation to the clinical setting. New funding from the Georgia Clinical & Translational Science Alliance is supporting Singh’s research.
CITATION: Kristel J. Yee Mon, Sungwoong Kim, Zhonghao Dai, Jessica D. West, Hongya Zhu5, Ritika Jain, Andrew Grimson, Brian D. Rudd, Ankur Singh. “Functionalized nanowires for miRNA-mediated therapeutic programming of naïve T cells,” Nature Nanotechnology.
FUNDING: Curci Foundation, NSF (EEC-1648035, ECCS-2025462, ECCS-1542081), NIH (5R01AI132738-06, 1R01CA266052-01, 1R01CA238745-01A1, U01CA280984-01, R01AI110613 and U01AI131348).
News Contact
Jerry Grillo