Dec. 03, 2025

For decades, manufacturing has been synonymous with job creation, a pillar of economic growth and stability. Today, the industry is evolving into something far more dynamic: a hub for innovation, sustainability, and purpose-driven careers. Experts say this transformation is reshaping not only what manufacturing looks like but why it matters.
Beyond the Assembly Line: A High-Tech Reality
“People still picture manufacturing as the assembly lines of the early 20th century,” says Thomas Kurfess, executive director of the Georgia Tech Manufacturing Institute. “The reality is very different. Modern plants are among the most advanced environments you’ll find, packed with robotics, automation, and data-driven systems. In fact, if you want to see the largest number of robots in one location, it will be at an automotive assembly plant.”
That disconnect between perception and reality is one reason manufacturers struggle to fill roles despite record demand. Kurfess notes that students often overlook manufacturing careers because they assume the work is low tech. “We need to expose educators, parents, and students to what manufacturing truly looks like,” he says. Facility tours and partnerships with technical colleges can help shift the narrative.
Pinar Keskinocak, H. Milton and Carolyn J. Stewart School Chair in the School of Industrial and Systems Engineering, agrees: “Showcasing innovations like AI-driven automation, 3D printing, and smart factories is key to changing perceptions.”
Green Tech and Digital Transformation
The rise of electric vehicles, batteries, and renewable energy is accelerating this shift. “Green technology presents a transformative opportunity for U.S. manufacturing,” Kurfess explains. “It is not just about sustainability; it is about national security and global competitiveness.”
These sectors are inherently digital, says Nagi Gebraeel, Georgia Power Term Professor in the College of Engineering. “Green tech manufacturing is being built in an era when advanced digital technologies are mature and widely accessible. Factories are designed from the ground up with automation and sensing embedded, creating highly interconnected systems.”
This evolution demands new skills. The labor force must navigate environments where operational technology and information technology converge. Gebraeel predicts that by 2035, manufacturing leaders will increasingly come from operations and data-driven backgrounds rather than traditional IT.
The Workforce Challenge
Despite the promise of high-tech careers, talent pipelines remain thin. Manpreet Hora, senior associate dean in the Scheller College of Business, points to a “demand-supply mismatch” driven by rapidly changing skill requirements. “Manufacturing now needs workers who combine technical, digital, and soft skills,” he says. “Meanwhile, younger workers often gravitate toward service industries for perceived growth and tech exposure. The manufacturing sector will collectively need to reposition themselves as employers of choice by making their digital tools visible, highlighting career progression, and offering flexible learning pathways.”
Experts agree that education must adapt. Kurfess advocates for a systemwide approach starting in elementary school, while Gebraeel emphasizes integrating AI into curricula and offering modular micro-credentials for upskilling. Hora adds that hands-on training should reflect realities like AI-enabled operations and sustainability-focused processes.
Purpose and Innovation
For younger professionals seeking meaningful work, manufacturing offers more than a paycheck. “These are high-tech, high-impact roles where workers build products that move the world, from aircraft and medical devices to renewable energy systems,” Kurfess says.
To position the industry as an innovation hub, leaders must embrace technologies that enhance efficiency and quality while fostering collaboration across schools, businesses, and government. “Modernizing the image of manufacturing demands aligned messaging and shared investment,” he adds.
Looking Ahead
By 2035, experts envision a workforce fluent in AI, committed to lifelong learning, and working in environments where cyber and physical systems are seamlessly integrated. Manufacturing will remain a cornerstone of economic strength, but its true value will lie in its ability to innovate, adapt, and deliver purpose-driven careers.
Nov. 05, 2025
</p>")
Diatoms, the beautiful baubles of the sea, boast form and function in ocean ecosystems. (Credit: Adobe Stock)

Yuanzhi Tang
If you know what diatoms are, it’s probably for their beauty. These single-celled algae found on the ocean floor have ornate glassy shells that shine like jewels under the microscope.
Their pristine geometry has inspired art, but diatoms also play a key role in ocean chemistry and ecology. While they are alive, these algae contribute to the climate by drawing down carbon dioxide from the atmosphere and releasing oxygen through photosynthesis, while fueling marine food webs.
Now, a team led by Georgia Tech scientists has revealed that diatoms leave a chemical fingerprint long after they die, playing an even more dynamic role in regulating Earth’s climate than once thought.
In a study published in Science Advances, the researchers found that diatoms’ intricate, silica-based skeletons transform into clay minerals in as little as 40 days. Until the 1990s, scientists believed that this enigmatic process took hundreds to thousands of years. Recent studies whittled it down to single-digit years.
“We’ve known that reverse weathering shapes ocean chemistry, but no one expected that it happens this fast,” said Yuanzhi Tang, professor in the School of Earth and Atmospheric Sciences and senior author of the study. “This shows that the molecular-scale reactions can reverberate all the way up to influence ocean carbon cycling and, ultimately, climate.”
From Glass to Clay
When a diatom dies, most of its silica skeleton dissolves on the seafloor, returning silica to the seawater. The rest can undergo reverse weathering — a process that transforms the silica into new clay minerals containing trace metals, while turning naturally sequestered carbon back to the atmosphere as sediments react with seawater. This recycling links silicon, carbon, and trace-metal cycles, influencing ocean chemistry and stabilizing the planet’s climate over time.
Tang and her team set out to uncover how, and how quickly, reverse weathering happens. Using a custom-built, two-chamber reactor, they recreated seafloor conditions in the lab. One chamber held diatom silica, while the other contained iron and aluminum minerals. A thin membrane allowed dissolved elements to mix while keeping the solids separate.
Using advanced microscopy, spectroscopy, and chemical analyses, the researchers tracked the full transformation from the dissolution of diatom shells to the formation of new clays.
The results were striking. Within just 40 days, the diatom silica became iron-rich clay minerals — the same minerals naturally found in marine sediments.
Tang noted that this rapid transformation means that reverse weathering isn’t a slow background process, but rather an active part of the modern ocean’s chemistry. It can control how much silica stays available for diatoms to grow, how much carbon dioxide is released or stored, and how trace metals and nutrients are recycled in marine ecosystems.
“It was remarkable to see how quickly diatom skeletons could turn into completely new minerals and to decipher the mechanisms behind this process,” said Simin Zhao, the paper’s first author and a former Ph.D. student in Tang’s lab.
“These transformations are small in size but are enormous in their implications for global elemental cycles and climate,” she added.
The results suggest that the influence of reverse weathering on the coupled silicon-carbon cycles may also respond on far shorter timescales, making the ocean’s chemistry more dynamic — and potentially more sensitive to modern environmental changes.
“Diatoms are central to marine ecosystems and the global carbon pump,” said Jeffrey Krause, co-author and oceanographer at the Dauphin Island Sea Lab and the University of South Alabama. “We already knew their importance to ocean processes while living. Now we know that even after they die, diatoms’ remains continue to shape ocean chemistry in ways that affect carbon and nutrient cycling. That’s a game-changer for how we think about these processes.”
The discovery also helps solve a long-standing mystery about what happens to silica in the ocean, Tang says.
Scientists have long known that more silica enters the ocean than gets buried on the seafloor. The findings suggest that rapid reverse weathering transforms much of it into new minerals instead, keeping ocean chemistry in balance.
From Atoms to Earth Systems and Beyond
The findings offer new data for climate modelers studying how the ocean regulates atmospheric carbon. The research also lays the groundwork for improving models of ocean alkalinity and coastal acidification — key tools for predicting how the planet will respond to climate change. “This study changes how scientists think about the seafloor, not as a passive burial ground, but as a dynamic chemical engine,” Tang said.
Tang sees the study as a powerful reminder of why basic research matters. “This is where chemistry meets Earth systems,” she said. “By understanding how minerals form and exchange elements at the atomic level, we can see how the ocean shapes global cycles of carbon, silicon, and metals. Even molecular-scale reactions within hair-sized organisms can ripple outward to shape planet-level dynamics.”
The team’s next steps are to explore how environmental factors such as water chemistry influence these transformations. They also plan to use samples from coastal and deep-sea sites to see how these lab discoveries translate to natural environments.
“It’s easy to overlook what’s happening quietly in marine sediments,” Tang said. “But these subtle mineral reactions are part of the machinery that regulates Earth’s climate, and they’re faster and more beautiful than we ever imagined.”
Citation: Simin Zhao et al., Rapid transformation of biogenic silica to authigenic clay: Mechanisms and geochemical constraints. Sci. Adv. 11, eadt3374 (2025).
DOI: https://doi.org/10.1126/sciadv.adt3374
Funding: National Science Foundation (OCE-1559087; OCE-1558957)
Nov. 04, 2025

Today, Velocity Startups joins Georgia Tech’s comprehensive commercialization ecosystem, solidifying the Institute’s role as a national leader and premier hub for research commercialization and startup growth. Velocity Startups serves as a bridge between early-stage startup founders who are focused on scaling their businesses and readying themselves for late-stage accelerators such as the Advanced Technology Development Center (ATDC), Engage, Fusen, and Atlanta Tech Village within the City of Atlanta.
To support emergent startups, the early-stage accelerator will establish a collaborative facility at The Biltmore in Atlanta’s Tech Square, the national innovation district and dedicated area in the city that fosters community growth and meaningful innovation at the heart of the city’s tech scene.
“Atlanta is where innovation becomes opportunity, and Velocity Startups will make that journey even faster,” said Donnie Beamer, senior technology advisor in the Atlanta Mayor’s Office of Technology and Innovation. “By connecting entrepreneurs to the critical resources they need to scale, we are fueling more startups, creating more jobs, and driving economic growth. Ultimately, this will secure Atlanta’s place as a top global destination for innovation, investment, and entrepreneurial success.”
As an early-stage accelerator, Velocity Startups provides resources — including mentorship support, space, tools, networks, and infrastructure — to Georgia Tech students, faculty, researchers, and the greater Atlanta community, bridging the gap from spinoff to viable startup. At Georgia Tech, many startups that complete the CREATE-X Startup Launch program and present at the Demo Day event will gain access to Velocity Startups. The accelerator will also offer strategic programming, funding, and access to Georgia Tech’s research resources and serve as a coordinating entity for Metro Atlanta’s entrepreneurial ecosystem, engaging more than 50 colleges and advocating for policies that support startup success.
“Velocity Startups represents a pivotal step in bringing together the resources, expertise, and entrepreneurial spirit within our ecosystems as we look to further establish Atlanta as a top national tech hub. By uniting these elements, Velocity Startups will help startups scale from their first customer to long-term growth,” said Raghupathy “Siva” Sivakumar, vice president of commercialization and chief commercialization officer at Georgia Tech and president of Georgia Advanced Technology Ventures. “This accelerator enables the communities at Georgia Tech and beyond to translate groundbreaking research into high-impact ventures.”
Velocity Startups is a subsidiary of Georgia Advanced Technology Ventures and will operate in partnership with the City of Atlanta. A national search is currently underway for a director to lead the accelerator.
For additional information about Velocity Startups, visit commercialization.gatech.edu/velocity.
News Contact
Georgia Parmelee
Director of Communications
Office of Commercialization
Oct. 23, 2025

Raheem Beyah has been selected as Georgia Tech's next provost and executive vice president for Academic Affairs, beginning Nov. 1.
Beyah has served as the dean of the College of Engineering and Southern Company Chair at Georgia Tech since 2021. Under his leadership, the College has strengthened its national and global reputation for innovation, research excellence, and student success, earning top-10 national rankings across every engineering discipline.
Known for his mentorship and collaborative leadership, Beyah will assume the role of the Institute's chief academic officer — leading and supporting all academic and related units, including the Colleges, the Library, and professional education. He will also oversee academic and budgetary policy and priorities for the Institute.
"Raheem Beyah's commitment to students, faculty, and staff has always been at the heart of his leadership," said Georgia Tech President Ángel Cabrera. "He understands firsthand what they experience — their challenges, aspirations, and the drive that defines a Georgia Tech education. That perspective will make him an outstanding provost and a tremendous partner in advancing Georgia Tech's mission."
An Atlanta native who earned his master's and Ph.D. in electrical and computer engineering from Georgia Tech after completing a bachelor's degree at North Carolina A&T State University, Beyah is recognized as a leading expert in network security and privacy.
"What excites me most about Georgia Tech is how we bring different disciplines together to solve real problems," he said. "Innovation happens when engineers work alongside artists, humanists, and social scientists, connecting technology with purpose and people. As provost, I'm eager to continue building those bridges and supporting the incredible creativity that defines this community."
In 2024, Beyah was named a fellow by the Institute of Electrical and Electronics Engineers (IEEE). It is the highest echelon of membership in IEEE, the world's largest technical professional organization dedicated to "advancing technology for the benefit of humanity." He is a member of the American Association for the Advancement of Science, the American Society for Engineering Education, a lifetime member of the National Society of Black Engineers, and an Association for Computing Machinery distinguished scientist.
Before joining the faculty at Georgia Tech, where he has served in various leadership roles, Beyah was a faculty member in the Department of Computer Science at Georgia State University, a research faculty member with the Georgia Tech Communications Systems Center, and a consultant in Andersen Consulting's (now Accenture) Network Solutions Group.
Oct. 22, 2025

Image of Sandra Neuse, vice chancellor of Real Estate and Facilities, University System of Georgia

image of participants from the USG Energy Summit held Oct. 1
On Oct. 1, the Office of Sustainability (a department within Infrastructure and Sustainability) led the second meeting of the University System of Georgia (USG) Campus Energy and Resiliency Group (CERG) summit to further the conversation around energy management for campuses statewide. Six Georgia schools participated: Georgia Tech, the University of Georgia, Emory University, Georgia State University, Kennesaw State University, and the University of West Georgia. Staff from the sustainability, utilities, and engineering departments of each of these schools gathered to discuss setting USG energy targets and best practices for reducing energy use, increasing energy efficiency, and establishing shared resources.
USG Vice Chancellor of Real Estate and Facilities Sandra Neuse was the keynote speaker. “I’m thrilled that the Campus Energy and Resiliency Group has come together organically to share their collective expertise in energy efficiency and sustainability,” she said. “Their focus on establishing energy efficiency targets and collaborating with other institutions across the USG will not only avoid costs — it is an investment in the future and a model for our students, who will be the next generation of leaders.”
The call for the development of the summit was inspired by the potential of collaboration throughout the USG, and the acknowledgment that each university has unique expertise, experience, and insight that can aid in energy management strategies for campuses across Georgia.
The key ideas discussed during the summit included:
- Setting statewide USG energy targets.
- Assessing Energy Use intensity, a metric that measures energy use per square foot per year at a building level.
- Developing a framework for best practices within the USG to share strategies for increasing energy efficiency and conservation.
- Developing standards for how utility data is tracked.
Increasing energy management efforts is critical right now as utility rates continue to rise. Jennifer Chirico, associate vice president of Sustainability, presented Georgia Tech’s energy data at the event. “One of the most important aspects of campus sustainability is increasing energy efficiency and setting energy targets to advance progress. We are excited to partner with our peers across USG to share best practices and move this effort forward,” she said.
The Georgia Tech Office of Sustainability plans on continued engagement with other USG campuses across the state, and the next summit is scheduled for Spring 2026 at Kennesaw State University.
News Contact
Tim Sterling
Sustainability Coordinator
Office of Sustainability
Infrastructure and Sustainability
Oct. 20, 2025

The Royal Society of NSW and the Learned Academies are hosting their 2025 Forum, “AI: The Hope and the Hype,” on November 6 at Government House, Sydney. The event will explore how artificial intelligence can deliver real-world benefits while managing its risks.
We’re proud to share that Tech AI’s own Pascal Van Hentenryck, A. Russell Chandler III Chair and Director of Georgia Tech’s AI Hub, will be among the featured speakers—bringing Georgia Tech’s global perspective on building trustworthy, impactful AI systems.
Learn more about the forum: royalsoc.org.au/events/rsnsw-and-learned-academies-forum-2025
Oct. 06, 2025

Electric vehicles (EVs) can be environmentally friendly and more cost-effective — until drivers plan a road trip. Charging stations aren’t as prevalent as traditional gas stations, and even if they can be found along the route, they may not be functioning or may already be occupied by other cars.
While EV charging locator apps can show drivers where the nearest charger is, they aren’t always accurate enough to show real-time status, such as whether a charger is working and available. How are drivers supposed to hit the road when they aren’t sure where their next charge is coming from? This uncertainty can be enough to deter drivers from purchasing an EV altogether.
New research from Georgia Tech, Harvard University, and Massachusetts Institute of Technology suggests that state governments should step in to help. The right policy could inspire data transparency by station hosts, ensuring that EV drivers have reliable networks — and thus encourage EV ownership. The researchers presented their findings in the paper, “Charger Data Transparency: Curing Range Anxiety, Powering EV Adoption,” in September’s Brookings.
Data Deserts
The researchers conducted a field experiment to discover the extent of the problem. This analysis showed that just 34% of EV charging stations provide real-time status updates across six major interstates in 40 U.S. states. The researchers found 150 to 350-mile stretches without real-time charger availability, longer than the stated range of many EV models. This leaves thousands of miles of highways in a data desert.
“We just don't have real-time data infrastructure necessary to build confidence in the reliability of charging, especially in communities along transit corridors,” said Omar Asensio, an associate professor in the Jimmy and Rosalynn Carter School of Public Policy. “It's not that the capability isn’t there. It's that there aren't clear incentives to encourage EV charging station operators to do the right thing and share the data.”
Charging Transparency
Government regulation is necessary to improve charging reliability, according to the researchers. State governments could offer funding for charging stations only if the station host agrees to data transparency. A simpler policy proposal would be for all fast chargers on highways to post their real-time status to an application programming interface, where software developers could access it. This approach would provide reliable information on whether a public charger is operational, and it can make government spending more efficient by leveraging network effects. The research team is already collaborating with state governments from Massachusetts to Georgia to discuss how to make this government regulation a reality.
State governments will also benefit, as EVs can help them close the gap on decreasing carbon emissions.
“Electric vehicles are a key strategy for decarbonizing the transportation sector and delivering public health co-benefits, but consumers need to trust that public chargers will work when they need them,” Asensio said. “Until real-time data disclosure standards are addressed, reliable, widespread adoption will be hard. A data-centric approach can enhance the efficiency of existing transportation investments.”
Many states, including Georgia, have also supported EV manufacturing. EV brand Rivian recently broke ground on an assembly plant outside Atlanta. More widespread EV adoption is paramount to making these plants economic successes. Data transparency regulations could be a start toward finally making EVs the ideal road trip vehicle.
News Contact
Tess Malone, Senior Research Writer/Editor
tess.malone@gatech.edu
Sep. 26, 2025

Two Georgia Tech Ph.D. students created a student-run, faculty-graded, fully-accredited course that links math, engineering and machine learning.
Andrew Rosemberg, with assistance from Michael Klamkin, both student researchers with the U.S. National Science Foundation AI Research Institute for Advances in Optimization (AI4OPT), designed the course to bridge gaps they saw in existing classrooms.
“While Georgia Tech offers excellent courses on optimization, control, and learning, we found no single class that connected all these fields in a cohesive way,” Rosemberg said. “In our research, it was clear these topics are deeply interconnected.”
Problem-driven learning
The course starts with fundamental problems and works backward to the methods required to solve them. Rosemberg said this approach was intentional. He said that courses often center around methods in isolation rather than showing how the methods contribute to the larger context. This keeps the course focused on problem-driven discovery.
The class also serves as a way for Rosemberg and Klamkin to strengthen their own teaching and mentoring skills.
Goals and structure
The primary goal of the course is to help students build a clear understanding of how mathematical programming, classical optimal control, and machine learning techniques such as reinforcement learning connect to one another. Students are also working to produce a structured book by the end of the semester.
“The hope is that this resource will not only solidify our own learning but also serve as a guide for other students who want to approach these problems in the future,” Rosemberg said.
Responsibilities are distributed across participants, with each student delivering lectures, reviewing peers’ work, and contributing to collective discussions. Rosemberg and Klamkin provide additional support where needed, while faculty mentor and director of AI4OPT, Pascal Van Hentenryck, ensures the class stays aligned with broader academic objectives.
Student ownership and collaboration
Rosemberg noted that the student-led model gives students a deeper sense of ownership, making them responsible for their own learning, and having a stronger impact. This model allows students to determine what to learn and why, which promotes critical thinking.
The course uses GitHub as its primary workflow platform. Rosemberg said adds transparency and prepares students for real-world research practices.
“GitHub functions much like university systems such as Canvas or Piazza. It also has the added benefit of making all contributions visible to the world,” Rosemberg explained. “This helps students take pride and ownership of their work, while also introducing them to Git, an essential tool for software development and modern STEM research.”
Emerging insights and challenges
Students have begun aligning their research with course themes, including shaping qualifying exam topics around the intersections of operations research, optimal control and reinforcement learning. Rosemberg said exploring the comparative strengths of these fields side by side has been one of the most rewarding outcomes.
Balancing independence with guidance has proven to be the greatest challenge. He said they have been evolving alongside the students in real time and have learned to emphasize mutual responsibility to promote the collective progress of the class.
Looking ahead
Rosemberg said future iterations of the course may place more emphasis on setting expectations early, given the effort required to deliver a lecture in this format.
His advice for others who may want to replicate the model is to focus on building a committed core team.
“Start with a small, motivated group,” Rosemberg said. “Like a startup, success depends less on the structure and more on the dedication of the people involved.”
News Contact
Jaci Bjorne
Sep. 04, 2025
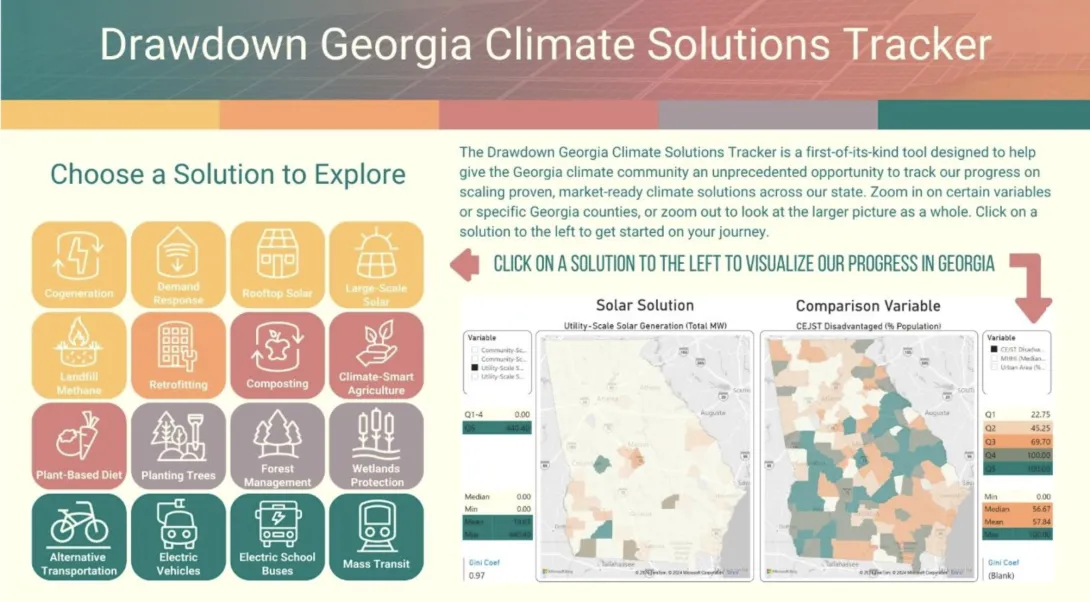
Electric vehicles. Rooftop solar. Cycling to work. Knowing where to start when reducing your personal carbon footprint can be daunting. But a new tool from Georgia Tech makes it easier for anyone to figure out how they can help address climate change.
The Drawdown Georgia Solutions Tracker is a digital dashboard that enables everyday Georgians to see how effective various technologies could be for each county. The tracker analyzes public data for 16 solutions — from planting trees to public transit — that can lower greenhouse gas emissions. The tracker is equally essential for policymakers and business leaders, enabling them to identify opportunities to propose legislation or adjust operations to reduce carbon emissions.
To use the tracker, viewers click on a solution to see its impact. Then, they specify a particular county, and the data is tailored to the most relevant metric. For example, if someone picks “plant-based diet” as a solution, they can see how many vegan restaurants are already in their county. The tracker also contrasts the climate solution with a relevant area that might benefit if the solution is implemented. For the plant-based example, the tracker compares it to urban density.
This tracker is one of the many initiatives of Drawdown Georgia, one of the Ray C. Anderson Foundation’s key funding initiatives based on research conducted by Georgia Tech, Georgia State University, the University of Georgia, and Emory University. Drawdown Georgia's goal is to reduce Georgia’s carbon impact by 57% by 2030 and to accelerate Georgia’s progress toward net-zero greenhouse emissions.
Drawdown Georgia also developed a carbon emissions tracker that shows carbon emission levels by county. The dashboard was a success, but the Drawdown Georgia team wanted to create a more proactive tool. The Solutions Tracker was designed so that anyone could make smalldaily changes to improve the climate — not just track it.
“We began the Drawdown Georgia project with the goal of cutting state pollution significantly,” said Marilyn Brown, Regents' Professor and the Brook Byers Professor of Sustainable Systems in the Jimmy and Rosalynn Carter School of Public Policy. "To get Georgians involved, we decided to focus on local and regional opportunities to reduce emissions.”
Drawdown Data
The data combines federal and state sources from the U.S. Energy Information Administration, the National Renewable Energy Laboratory, and the Department of Agriculture. Some solutions may seem obvious, like planting trees, but others are more niche. For example, decomposing trash often produces methane gas, which means that landfills contribute to greenhouse gas emissions — important information for policymakers to consider when developing carbon reduction strategies.
The researchers hope everyone will use the tracker. Politicians and policymakers can find new ideas for legislation or the adoption of these solutions. Business leaders can find opportunities to hit their decarbonization goals. Georgians can use the tracker to figure out which solutions are most sustainable for their lives. Even scientists can learn which methods to home in on for their research. Since the tracker is available via Creative Commons, anyone can use the data to build their own tools or models.
The tracker is already having a real-world impact. Brown and the Drawdown Georgia team have collaborated with the state of Georgia and the 29-county metro Atlanta area on their carbon action plans. They’ve also partnered with 75 businesses on carbon action plans and other solutions through the Drawdown Georgia Business Compact, managed by the Ray C. Anderson Center for Sustainable Business in the Scheller College of Business. As these stakeholders ask questions about different climate solution impacts, the team has expanded the tracker accordingly. They’ve also recently redesigned the user interface to make it even more accessible for everyday users.
From improved public health to business opportunities, the state requires reduced greenhouse gases, and Georgia Tech is not only tracking emissions but helping to fix the problem, too.
News Contact
Tess Malone, Senior Research Writer/Editor
tess.malone@gatech.edu
Sep. 02, 2025

A new version of Georgia Tech’s virtual teaching assistant, Jill Watson, has demonstrated that artificial intelligence can significantly improve the online classroom experience. Developed by the Design Intelligence Laboratory (DILab) and the U.S. National Science Foundation AI Institute for Adult Learning and Online Education (AI-ALOE), the latest version of Jill Watson integrates OpenAI’s ChatGPT and is outperforming OpenAI’s own assistant in real-world educational settings.
Jill Watson not only answers student questions with high accuracy. It also improves teaching presence and correlates with better academic performance. Researchers believe this is the first documented instance of a chatbot enhancing teaching presence in online learning for adult students.
How Jill Watson Shaped Intelligent Teaching Assistants
First introduced in 2016 using IBM’s Watson platform, Jill Watson was the first AI-powered teaching assistant deployed in real classes. It began by responding to student questions on discussion forums like Piazza using course syllabi and a curated knowledge base of past Q&As. Widely covered by major media outlets including The Chronicle of Higher Education, The Wall Street Journal, and The New York Times, the original Jill pioneered new territory in AI-supported learning.
Subsequent iterations addressed early biases in the training data and transitioned to more flexible platforms like Google’s BERT in 2019, allowing Jill to work across learning management systems such as EdStem and Canvas. With the rise of generative AI, the latest version now uses ChatGPT to engage in extended, context-rich dialogue with students using information drawn directly from courseware, textbooks, video transcripts, and more.
Future of Personalized, AI-Powered Learning
Designed around the Community of Inquiry (CoI) framework, Jill Watson aims to enhance “teaching presence,” one of three key factors in effective online learning, alongside cognitive and social presence. Teaching presence includes both the design of course materials and facilitation of instruction. Jill supports this by providing accurate, personalized answers while reinforcing the structure and goals of the course.
The system architecture includes a preprocessed knowledge base, a MongoDB-powered memory for storing conversation history, and a pipeline that classifies questions, retrieves contextually relevant content, and moderates responses. Jill is built to avoid generating harmful content and only responds when sufficient verified course material is available.
Field-Tested in Georgia and Beyond
The first AI-powered teaching assistant was developed for Georgia Tech’s Online Master of Science in Computer Science (OMSCS) program. By fall 2023, Jill Watson was deployed in Georgia Tech’s OMSCS artificial intelligence course, serving more than 600 students, as well as in an English course at Wiregrass Georgia Technical College, part of the Technical College System of Georgia (TCSG).
A controlled A/B experiment in the OMSCS course allowed researchers to compare outcomes between students with and without access to Jill Watson, even though all students could use ChatGPT. The findings are striking:
- Jill Watson’s accuracy on synthetic test sets ranged from 75% to 97%, depending on the content source. It consistently outperformed OpenAI’s Assistant, which scored around 30%.
- Students with access to Jill Watson showed stronger perceptions of teaching presence, particularly in course design and organization, as well as higher social presence.
- Academic performance also improved slightly: students with Jill saw more A grades (66% vs. 62%) and fewer C grades (3% vs. 7%).
A Smarter, Safer Chatbot
While Jill Watson uses ChatGPT for natural language generation, it restricts outputs to validated course material and verifies each response using textual entailment. According to a study by Taneja et al. (2024), Jill not only delivers more accurate answers than OpenAI’s Assistant but also avoids producing confusing or harmful content at significantly lower rates.
Compared to OpenAI’s Assistant, Jill Watson (ChatGPT) not only achieves higher accuracy but also produces confusing or harmful content at significantly lower rates. Jill Watson answers correctly 78.7% of the time, with only 2.7% of its errors categorized as harmful and 54.0% as confusing. In contrast, OpenAI’s Assistant demonstrates a much lower accuracy of 30.7%, with harmful failures occurring 14.4% of the time and confusing failures rising to 69.2%. Additionally, Jill Watson has a lower retrieval failure rate of 43.2%, compared to 68.3% for the OpenAI Assistant.
What’s Next for Jill
The team plans to expand testing across introductory computing courses at Georgia Tech and technical colleges. They also aim to explore Jill Watson’s potential to improve cognitive presence, particularly critical thinking and concept application. Although quantitative results for cognitive presence are still inconclusive, anecdotal feedback from students has been positive. One OMSCS student wrote:
“The Jill Watson upgrade is a leap forward. With persistent prompting I managed to coax it from explicit knowledge to tacit knowledge. Kudos to the team!”
The researchers also expect Jill to reduce instructional workload by handling routine questions and enabling more focus on complex student needs.
Additionally, AI-ALOE is collaborating with the publishing company John Wiley & Sons, Inc., to develop a Jill Watson virtual teaching assistant for one of their courses, with the instructor and university chosen by Wiley. If successful, this initiative could potentially scale to hundreds or even thousands of classes across the country and around the world, transforming the way students interact with course content and receive support.
A Georgia Tech-Led Collaboration
The Jill Watson project is supported by Georgia Tech, the US National Science Foundation’s AI-ALOE Institute (Grants #2112523 and #2247790), and the Bill & Melinda Gates Foundation.
Core team members are Saptrishi Basu, Jihou Chen, Jake Finnegan, Isaac Lo, JunSoo Park, Ahamad Shapiro and Karan Taneja, under the direction of professor Ashok Goel and Sandeep Kakar. The team works under Beyond Question LLC, an AI-based educational technology startup.
News Contact
Breon Martin