Apr. 13, 2026

Vibe coding programmers are releasing batches of vulnerable code, according to researchers at the School of Cybersecurity and Privacy (SCP) at Georgia Tech, who have scanned over 43,000 security advisories across the web.
The programming style relies on using generative artificial intelligence (AI) to create software code using tools like Claude, Gemini, and GitHub Copilot. According to graduate research assistant Hanqing Zhao of the Systems Software & Security Lab (SSLab), no one had been tracking these common vulnerabilities and exposures before the launch of their Vibe Security Radar.
“The vulnerabilities we found lead to breaches,” he said. “Everyone is using these tools now. We need a feedback loop to identify which tools, which patterns, and which workflows create the most risk.”
The radar extensively scans public vulnerability databases, finds the error for each vulnerability, and then examines the code’s history to find who introduced the bug. If they discover an AI tool's signature, the radar flags it.
Of the 74 confirmed cases uncovered so far by the tool, 14 are critical risks, and 25 are high. These vulnerabilities include command injection, authentication bypass, and server-side request forgery. Zhao explained that since AI models tend to repeat the same mistakes, an attacker would need to find these bugs just once.
“Millions of developers using the same models means the same bugs showing up across different projects,” he said. “Find one pattern in one AI codebase, you can scan for it across thousands of repositories.”
Despite its success, the team has only scratched the surface of the problem. The radar can trace metadata like co-author tags, bot emails, and other known tool signatures, but it can't identify an issue if these markers have been removed.
The next step is behavioral detection. AI-written code has patterns in how it names variables, structures functions, and handles errors.
“We're building models that can identify AI code from the code itself, no metadata needed,” said Zhao. “That opens up a lot of cases we currently can't touch.”
The team is also improving its verification pipeline and expanding its sources to include more vulnerability databases. The goal is to get a more complete picture of AI-introduced vulnerabilities across open source, not just the ones that happen to leave signatures behind.
As more programmers rely on vibe coding, Zhao warns that it still needs to be reviewed as thoroughly as any other project.
“The whole point of vibe coding is not reading it afterward, I know,” he said. “But if you're shipping AI output to production, review it the way you'd review a junior developer's pull request. Especially anything around input handling and authentication.”
When prompting AI, SSLab also recommends providing more detailed instructions to get it closer to production-ready. There are also tools to check the code for vulnerabilities after code it has been generated. Not double-checking could lead to a catastrophe.
“The attack surface keeps growing,” said Zhao. “More people running AI agents locally means the attacker doesn't need to break into the company infrastructure. They just need one vulnerability in a model context protocol server that someone installed and never reviewed.”
One reason the attack surfaces are expanding rapidly is AI’s evolution. In the second half of 2025, the Vibe Security Radar found about 18 cases across seven months. Then, in the first three months of 2026, it identified 56. March 2026 alone had 35, more than all of 2025 combined.
Many tools, like Claude, are now more autonomous, allowing developers to write entire features, create files, and even make architecture decisions.
“When an agent builds something without authentication, that's not a typo,” said Zhao. “It's a design flaw baked in from the start. Claude Code and Copilot together account for most of what we detect, but that's partly because they leave the clearest signatures.”
News Contact
John Popham
Communications Officer II at the School of Cybersecurity and Privacy
Apr. 09, 2026

Researchers at Georgia Tech are using math, science, and artificial intelligence to better understand how people think, move, and perceive the world.

Caption: This image shows a topographic vision model trained to have a brain-like organization.

Caption: This shows how spinal cord activity guides transitions in muscle output for extensor muscles.

Caption: This shows how mice behave differently when they are pursuing different goals.

Caption: This shows the spike patterns of a hawk moth. Motor systems use spike codes to control motor output.

Caption: This shows how visual data from the retina is directed to the correct cognitive domain in the brain through a region of the visual cortex.
Nothing rivals the human brain’s complexity. Its 86 billion neurons and 85 billion other cells make an estimated 100 trillion connections. If the brain were a computer, it would perform an exaflop (a billion-billion) mathematical calculations every second and use the equivalent of only 20 watts of power. As impressive as the brain is, neurologists can’t fully explain how neurons work together.
To help find answers, researchers at the Institute for Neuroscience, Neurotechnology, and Society (INNS) are using math, data, and AI to unlock the secrets of thought. Together they are helping turn the brain’s raw electrical “noise” into real insights about how people think, move, and perceive the world.
Fair warning: Prepare your neurons for the complexity of this brain research ahead.
Building AI Like a Brain
What if artificial neurons in AI programs were arranged as they are in the brain?
AI programs would then help us understand why the brain is organized the way it is. This neuro-AI synthesis would also work faster, use less energy, and be easier to interpret. Creating such systems is the goal of Apurva Ratan Murty, an assistant professor of Psychology who is creating topographic AI models like the one above of three domains — vision, audition, and language inspired by the brain. In the near future, he predicts doctors might be able to use these patterns to predict the effects of brain lesions and other disorders. “We’re not there yet,” he says. “But our work brings us significantly closer to that future than ever before.”
Computing Thought and Movement
How cats walk keeps Chethan Pandarinath on his toes. This biomedical engineer uses sensors to analyze how two sets of feline leg muscles — flexors and extensors — are controlled by the spinal cord. Understanding how that happens could help patients partially paralyzed from spinal cord injuries, strokes, or progressive neuro-degenerative diseases get back on their feet again. “My lab is using AI tools that allow us to turn complex spinal cord activity data into something we can interpret. It tells us there’s a simple underlying structure behind the complex activity patterns,” says the associate professor.
Revealing the Brain’s Spike Patterns
“The brain is like a symphony conductor,” says Simon Sponberg. “Individual instruments have some independent control, but most of the music comes from the brain’s precise coordination of notes among the different players in the body.” This physics professor studies the fantastically fast-beating wings of the hummingbird-sized hawk moth (Manduca sexta). Its agile flight movement comes as a result of spikes in electrical activity in 10 muscles. Sponberg found something that surprised him — the brain focuses less on creating the number of spikes than in orchestrating their precise patterns over time. To Sponberg, every millisecond matters. “We are just beginning to understand how the nervous system first acquires precisely timed spiking patterns during development,” he says.
Predicting Decisions Through Statistics
Put a mouse in a maze with food far away, and it will learn to find it. But life for mice — and people — isn’t so simple. Sometimes they want to explore, only want water, or just want to go home. What’s more, animals make decisions based on their history, not just on how they feel at the moment. To dig deeper into the decision-making process, Anqi Wu, an assistant professor in the School of Computational Science and Engineering, is giving mice more options. By using a new computational framework called SWIRL (Switching Inverse Reinforcement Learning), her findings have outperformed models that fail to take historical behavior into account. “We’re seeking to understand not only animal behavior but also human behavior to gain insight into the human decision-making process over a long period of time,” she says.
Modeling the Mind’s Wiring With Math
Connectivity shapes cognition in the cerebral cortex, a layered structure in the brain. The visual cortex, in particular, processes visual data from the retina relayed through the Lateral Geniculate Nucleus (LGN) in the thalamus, and directs it to the correct cognitive domain in the brain. How it does this is the mystery that computational neuroscientist Hannah Choi wants to solve. “The big question I’m interested in is how network connectivity patterns in the architecture of the LGN are related to computations,” says this assistant math professor. To find answers, she shows mice repeated image patterns such as flower-cat-dog-house and then disrupts the pattern. The goal? To grasp how the thalamus’s nonlinear dynamical system works. If scientists and doctors better understand how brain regions are wired together, such knowledge could lead to better disease treatment.
This story was originally published through the Georgia Tech Alumni Magazine. Read the original publication here.
Apr. 02, 2026

As students increasingly turn to artificial intelligence (AI) to help with coursework, some worry that their learning could be compromised. Georgia Tech researchers are working to counter this potential decline with an AI tool they hope will promote learning rather than hinder it.
TokenSmith is a citation-supported large language model (LLM) tutor that can be hosted locally on a user’s personal computer. The tutor only provides answers based on course materials, such as the textbook or lecture slides.
Associate Professor Joy Arulraj began the project with support from the Bill Kent Family Foundation AI in Higher Education Faculty Fellowship last year. The fellowship, led by Georgia Tech’s Center for 21st Century Universities, supports faculty projects exploring innovative and ethical uses of AI in teaching.
Arulraj has enlisted assistant professors Kexin Rong and Steve Mussmann to help build TokenSmith.
Mussmann said TokenSmith is a synergistic blend of a database system and a machine learning system. The model stores textbooks, textbook annotations by course staff, common questions and answers, a learning state of the student, and student feedback in a structured database system. However, machine learning plays a key role in the answer generation as well as adapting the system to the student, course staff guidance, and user feedback.
"What excites me most is demonstrating how data-driven ML and principled database systems design can reinforce each other — one providing adaptability and flexibility, the other providing structure and traceability — in a way that benefits students," Mussmann said.
Keeping the model local has been an important focus of the project. The team wanted to create an AI tutor that helps students learn from their class resources rather than just giving answers. With each response, TokenSmith cites the origin of the answer in the provided documents.
“One problem with LLMs is that they can hallucinate and provide wrong answers, but in this controlled environment, we can add these guardrails to make sure it’s actually helpful in an educational setting,” Rong said.
Rong said she feels that students often undervalue textbooks, and she hopes TokenSmith can motivate students to make better use of them.
“Textbooks can sometimes be daunting, but maybe if we combine them with the model, students might be more willing to read a paragraph or page in the textbook, and that could help clarify something for them,” she said.
Running the model locally is more cost-effective and helps preserve the user’s privacy. But running the new tool locally comes with technical challenges.
One challenge with creating the model is speed. Since it is a locally based model, TokenSmith depends solely on the user’s computer memory. Tests have also shown that the tutor currently struggles to answer more complex questions.
“We are interested in pushing the boundaries of these local models so that they give students good answers and also run fast enough to keep students engaged,” Arulraj said.
News Contact
Morgan Usry, Communications Officer
Mar. 31, 2026


While people use search engines, chatbots, and generative artificial intelligence tools every day, most don’t know how they work. This sets unrealistic expectations for AI and leads to misuse. It also slows progress toward building new AI applications.
Georgia Tech researchers are making AI easier to understand through their work on Transformer Explainer. The free, online tool shows non-experts how ChatGPT, Claude, and other large language models (LLMs) process language.
Transformer Explainer is easy to use and runs on any web browser. It quickly went viral after its debut, reaching 150,000 users in its first three months. More than 563,000 people worldwide have used the tool so far.
Global interest in Transformer Explainer continues when the team presents the tool at the 2026 Conference on Human Factors in Computing Systems (CHI 2026). CHI, the world’s most prestigious conference on human-computer interaction, will take place in Barcelona, April 13-17.
“There are moments when LLMs can seem almost like a person with their own will and personality, and that misperception has real consequences. For example, there have been cases where teenagers have made poor decisions based on conversations with LLMs,” said Ph.D. student Aeree Cho.
“Understanding that an LLM is fundamentally a model that predicts the probability distribution of the next token helps users avoid taking its outputs as absolute. What you put in shapes what comes out, and that understanding helps people engage with AI more carefully and critically.”
A transformer is a neural network architecture that changes data input sequence into an output. Text, audio, and images are forms of processed data, which is why transformers are common in generative AI models. They do this by learning context and tracking mathematical relationships between sequence components.
Transformer Explainer demystifies how transformers work. The platform uses visualization and interaction to show, step by step, how text flows through a model and produces predictions.
Using this approach, Transformer Explainer impacts the AI landscape in four main ways:
- It counters hype and misconceptions surrounding AI by showing how transformers work.
- It improves AI literacy among users by removing technical barriers and lowering the entry for learning about AI.
- It expands AI education by helping instructors teach AI mechanisms without extensive setup or computing resources.
- It influences future development of AI tools and educational techniques by providing a blueprint for interpretable AI systems.
“When I first learned about transformers, I felt overwhelmed. A transformer model has many parts, each with its own complex math. Existing resources typically present all this information at once, making it difficult to see how everything fits together,” said Grace Kim, a dual B.S./M.S. computer science student.
“By leveraging interactive visualization, we use levels of abstraction to first show the big picture of the entire model. Then users click into individual parts to reveal the underlying details and math. This way, Transformer Explainer makes learning far less intimidating.”
Many users don’t know what transformers are or how they work. The Georgia Tech team found that people often misunderstand AI. Some label AI with human-like characteristics, such as creativity. Others even describe it as working like magic.
Furthermore, barriers make it hard for students interested in transformers to start learning. Tutorials tend to be too technical and overwhelm beginners with math and code. While visualization tools exist, these often target more advanced AI experts.
Transformer Explainer overcomes these obstacles through its interactive, user-focused platform. It runs a familiar GPT model directly in any web browser, requiring no installation or special hardware.
Users can enter their own text and watch the model predict the next word in real time. Sankey-style diagrams show how information moves through embeddings, attention heads, and transformer blocks.
The platform also lets users switch between high-level concepts and detailed math. By adjusting temperature settings, users can see how randomness affects predictions. This reveals how probabilities drive AI outputs, rather than creativity.
“Millions of people around the world interact with transformer-driven AI. We believe that it is crucial to bridge the gap between day-to-day user experience and the models' technical reality, ensuring these tools are not misinterpreted as human-like or seen as sentient,” said Ph.D. student Alex Karpekov.
“Explaining the architecture helps users recognize that language generated by models is a product of computation, leading to a more grounded engagement with the technology.”
Cho, Karpekov, and Kim led the development of Transformer Explainer. Ph.D. students Alec Helbling, Seongmin Lee, Ben Hoover, and alumni Zijie (Jay) Wang (Ph.D. ML-CSE 2024) and Minsuk Kahng (Ph.D. CS-CSE 2019) assisted on the project.
Professor Polo Chau supervised the group and their work. His lab focuses on data science, human-centered AI, and visualization for social good.
Acceptance at CHI 2026 stems from the team winning the best poster award at the 2024 IEEE Visualization Conference. This recognition from one of the top venues in visualization research highlights Transformer Explainer’s effectiveness in teaching how transformers work.
“Transformer Explainer has reached over half a million learners worldwide,” said Chau, a faculty member in the School of Computational Science and Engineering.
“I'm thrilled to see it extend Georgia Tech's mission of expanding access to higher education, now to anyone with a web browser.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Mar. 31, 2026

Voice-activated, conversational artificial intelligence (AI) agents must provide clear explanations for their suggestions, or older adults aren’t likely to trust them.
That’s one of the main findings from a study by AI Caring on what older adults expect from explainable AI (XAI).
AI Caring is one of three AI Institutions led by Georgia Tech and funded by the National Science Foundation (NSF). The institution supports AI research that benefits older adults and their caregivers.
Niharika Mathur, a Ph.D. candidate in the School of Interactive Computing, was the lead author of a paper based on the study. The paper will be presented in April at the 2026 ACM Conference on Human Factors in Computing Systems (CHI) in Barcelona.
Mathur worked with the Cognitive Empowerment Program at Emory University to interview 23 older adults who live alone and use voice-activated AI assistants like Amazon’s Alexa and Google Home.
Many of them told her they feel excluded from the design of these products.
“The assumption is that all people want interactions the same way and across all kinds of situations, but that isn’t true,” Mathur said. “How older people use AI and what they want from it are different from what younger people prefer.”
One example she gave is that young people tend to be informal when talking with AI. Older people, on the other hand, talk to the agent like they would a person.
“If Older adults are talking to their family members about Alexa, they usually refer to Alexa as ‘she’ instead of ‘it,’” Mathur said. “They tend to humanize these systems a lot more than young people.”
Good Explanations
The study evaluated AI explanations that drew information from four sources of data:
- User history (past conversations with the agent)
- Environmental data (indoor temperature or the weather forecast)
- Activity data (how much time a user spends in different areas of the home)
- Internal reasoning (mathematical probabilities and likely outcomes)
Mathur said older users trust the agent more when it bases its explanations on data from the first three sources. However, internal reasoning creates skepticism.
Internal reasoning means the AI doesn’t have enough data from the other sources to give an explanation. It provides a percentage to reflect its confidence based on what it knows.
“The overwhelming response was negative toward confidence scores,” Mathur said. “If the AI says it’s 92% confident, older adults want to know what that’s based on.”
This is another example that Mathur said points to generational preferences.
“There’s a lot of explainable AI research that shows younger people like to see numbers in explanations, and they also tend to rely too much on explanations that contain numerical confidence. Older adults are the opposite. It makes them trust it less.”
Knowing the Context
Mathur said that AI agents interacting with older adults should serve a dual purpose. They should provide users with companionship and support independence while reducing the caretaking burden often placed on family members.
Some studies have shown that engineers have tended to favor caretakers in the design of these tools. They prioritize daily tasks and routines, leaving some older adults to feel like they are merely a box to be checked.
She discovered that in urgent situations, older users prefer the AI to be straightforward, while in casual settings, they desire more conversation.
“How people interact with technological systems is grounded in what the stakes of the situation are,” she said. “If it had anything to do with their immediate sense of safety, they did not want conversational elaboration. They want the AI to be very direct and factual.”
Not Just Checking Boxes
Mathur said AI agents that interact with older adults are ideally constructed with a dual purpose. They should provide companionship and autonomy for the users while alleviating the burden of caretaking that is often placed on their family members.
Some studies have shown that engineers have strayed toward favoring caretakers in the design of these tools. They prioritize daily tasks and routines, leaving some older adults to feel like they are a box to be checked.
“They’re not being thought of as consumers,” Mathur said. “A lot of products are being made for them but not with them.”
She also said psychological well-being is one of the most important outcomes these tools should produce.
Showing older adults that they are listened to can significantly help in gaining their trust. Some interviewees told Mathur they want agents who are deliberate about understanding their preferences and don’t dismiss their questions.
Meeting these needs reduces the likelihood of protesting and creating conflict with family members.
“It highlights just how important well-designed explanations are,” she said. “We must go beyond a transparency checklist.”
News Contact
Nathan Deen
College of Computing
Georgia Tech
Mar. 24, 2026


By Chris Gaffney, Managing Director of the Georgia Tech Supply Chain and Logistics Institute, Supply Chain Advisor, and former executive at Frito‑Lay, AJC International, and Coca‑Cola
We recently wrapped our semi‑annual industry advisory board meeting, where a core element of the agenda is a set of "hot topics" sourced in advance from our member companies, curated, and facilitated to reflect what is most top of mind in the field. This cycle, one of those topics focused on the impact of AI on supply chain technology investment.
What began as a discussion on technology quickly surfaced a broader issue:
AI is not just changing supply chains—it is raising the standard for execution, and in doing so, redefining what it takes to sustain a brand.
When Capability Becomes Cheap
Within that discussion, a simple example sparked debate. Most of us would trust a platform like DocuSign without hesitation. It has earned that trust through reliability, security, and consistent performance.
But what if a new entrant—call it “FredSign”—offered similar functionality, powered by AI, at lower cost and with comparable features? Would you use it?
The room split. Some argued that established brands are durable because of the trust they have built over time. Others pushed back, suggesting that AI‑enabled challengers could close that gap faster than expected, making brand less relevant.
The discussion quickly moved beyond software to a broader question:
In a world where AI lowers the cost of building capability, does trust shift from brand to performance—or does brand become even more important?
Brand as a Promise
From a supply chain perspective, this is no longer theoretical. It is already happening.
At its core, a brand is a promise. For product companies, that promise is built on quality, consistency, and the experience of using the product over time. For supply chain technology and service providers, it is grounded in reliability, security, and confidence in execution.
Historically, brand has been reinforced by performance—but also protected by time, scale, and familiarity.
AI is changing that balance.
Lower Barriers, Higher Expectations
On one hand, AI lowers barriers to entry. New entrants can replicate functionality faster, improve user experiences, and target specific gaps in incumbent offerings.
In supply chain technology, this is particularly relevant. Many organizations have made significant, long‑term investments in systems that have not always delivered as expected. That creates an opening for AI‑enabled providers to enter through narrow use cases, solve specific problems better, and establish a foothold. Over time, they build credibility.
But there is a second dimension that is more immediate—and more consequential.
AI Raises the Execution Standard
One way to frame this is simple: data is a terrible thing to waste.
For years, supply chains have generated vast amounts of data across planning systems, transportation networks, warehouses, and customer interactions. Much of that data has been underutilized—captured, stored, but not fully leveraged to anticipate risk or improve outcomes.
That is changing.
The capability now exists—and is rapidly maturing—to sense, interpret, and act on that data in ways that were not previously practical. Risks can be identified earlier. Disruptions can be predicted. Corrective actions can be taken before the customer ever feels the impact.
From Disruption to Preventability
Over the past week, in the span of just six days and four unrelated conversations with members of my network, I heard a series of examples that all pointed to this shift.
- A global food company managing risk tied to a critical supplier whose quality issues could impact multiple major brands—raising the question of whether AI could have surfaced a near sole‑source dependency earlier.
- An e‑commerce retailer using machine learning to reduce theft and damage in its fulfillment network, improving the customer experience.
- An organization proactively shifting its fulfillment partner mix based on AI‑driven insights into which nodes can and cannot handle surge capacity.
- A high‑end clothing shipment arriving wet due to a fulfillment breakdown—where the loss was not just the product, but a time‑sensitive moment that could not be recovered.
- A consumer receiving an empty box after successfully purchasing a limited‑release product that could not be replaced.
These are not isolated anecdotes. The common thread is not disruption—it is preventability.
As AI enables earlier detection of risk, better prediction of disruptions, and faster response to exceptions, the tolerance for failure is declining. Companies are no longer judged simply on whether something went wrong. They are judged on whether it should have been avoided.
Brand Is the Delivered Experience
From a brand perspective, that is a fundamental shift.
A product brand may invest heavily in innovation and customer engagement. But if the product arrives damaged, late, or not at all, the customer does not distinguish between the brand owner and the supply chain behind it.
There is only one experience—and therefore only one brand.
In an AI‑enabled supply chain, failure is no longer just a risk—it is increasingly a choice.
The Weakest Node Defines the Brand
A brand is now only as strong as its weakest node.
That node may be a supplier, a logistics provider, a fulfillment partner, or a technology platform. Many sit outside the direct control of the brand owner, yet their performance is inseparable from the customer’s perception of the brand.
AI makes it possible to identify and address these weak points—but it also makes it more apparent when companies fail to do so.
Implications for the Supply Chain Ecosystem
This dynamic extends directly to platform and software providers. In an AI‑enabled environment, it is no longer sufficient for supply chain technology to be stable or functionally adequate. It must evolve—continuously—to sense risk earlier, enable better decisions, and improve execution outcomes. If it does not, its limitations will be exposed quickly, and alternatives will emerge.
Technology providers are not insulated by their brand; they are judged by the outcomes they enable. Their brand will strengthen if their platforms improve execution—and erode if they do not.
Product companies must use AI to protect the customer experience end‑to‑end. Logistics providers must adopt AI to remain credible partners. Technology providers must evolve their platforms to meet a higher execution standard.
If one part of the system advances while another does not, the gap will be visible—and acted upon quickly.
Winners and losers are being judged daily.
What This Means for Leaders
None of this suggests that brand is no longer important. In high‑trust, high‑risk environments—contracts, financial transactions, healthcare, and other sensitive use cases—brand remains critical.
Even in this environment, trust must be continuously reinforced through performance. Leaders must clearly understand what underpins their brand. Brand is not an asset to be protected; it is the result of consistently delivering on a promise. Any performance gaps must be addressed before others move in. AI‑enabled challengers will not challenge strengths—they will target weaknesses.
Finally, leaders must elevate their ecosystem. Brand performance is now inseparable from partner performance. That requires greater visibility, tighter integration, and higher expectations—not only internally, but across suppliers, logistics providers, and technology partners.
One Question to Answer Now
This execution dimension is only one part of how AI is reshaping brand—but it is already decisive.
A great product can still win. A strong brand can still endure. But in an AI‑driven world, where disruptions can be anticipated and failures mitigated, the margin for error is disappearing.
And in many cases—especially where the purchase is infrequent or the moment is critical—you only get one shot. At the conclusion of our discussion, one participant framed it simply:
What is our secret sauce—and what are we doing to build on it?
That is the question every supply chain leader should be answering now.
Because in an AI‑enabled world, your brand will be defined by what your system consistently delivers.
Feb. 27, 2026



Georgia Tech researchers applied their expertise to a national research program that will shape the future of computing. Their work may yield more energy-efficient computers and better predictions for environmental challenges like carbon storage, tsunamis, wildfires, and sustainable energy.
The Department of Energy Office of Science recently released two reports through its Advanced Scientific Computing Research (ASCR) program. The reports were produced by workshops that brought together researchers from universities, national labs, government, and industry to set priorities for scientific computing.
Professor Felix Herrmann served on the organizing committee for the Workshop on Inverse Methods for Complex Systems under Uncertainty. Assistant Professor Peng Chen joined Herrmann as a workshop participant, contributing expertise in data science and machine learning.
Inverse methods work backward from outcomes to find their causes. Scientists use these tools to study complex systems, like designing new materials with targeted properties and using past wildfires to map vulnerable areas and behavior of future fires.
The ASCR report highlighted Herrmann’s work on seismic exploration and monitoring through digital twins. Founded on inverse methods, digital twins upgrade from static models to virtual systems that accurately mirror their physical counterparts.
Digital twins integrate real-time data sources, including fluid flows, monitoring and control systems, risk assessments, and human decisions. These models also account for uncertainty and address data gaps or limitations.
The DOE organized the workshop to support the growing role of inverse modeling. The group identified four priority research directions (PRDs) to guide future work. The PRDs are:
- PRD 1: Discovering, exploiting, and preserving structure
- PRD 2: Identifying and overcoming model limitations
- PRD 3: Integrating disparate multimodal and/or dynamic data
- PRD 4: Solving goal-oriented inverse problems for downstream tasks
“A digital twin is a system you can control, like to optimize operations or to minimize risk,” said Herrmann, who holds joint appointments in the Schools of Earth and Atmospheric Sciences, Electrical and Computer Engineering, and Computational Science and Engineering.
“Digital twins give you a principled way to consider uncertainties, which there are a lot in subsurface monitoring. If you inject carbon dioxide too fast, you will will increase the pressure and may fracture the rock. If you inject too slow, then the process may become too costly. Digital twins help us make balanced decisions under uncertainty.”
Supercomputers, algorithms, and artificial intelligence now power modern science. However, these tools consume enormous amounts of energy. This raises concerns about how to sustain computing and scientific research as we know them in the decades ahead.
Professors Rich Vuduc and Hyesoon Kim co-authored the report from the Workshop on Energy-Efficient Computing for Science. At the three-day ASCR workshop, participants identified five key research directions:
- PRD 1: Co-design energy-efficient hardware devices and architectures for important workloads
- PRD 2: Define the algorithmic foundations of energy-efficient scientific computing
- PRD 3: Reconceptualize software ecosystems for energy efficiency
- PRD 4: Enable energy-efficient data management for data centers, instruments, and users
- PRD 5: Develop integrated, scalable energy measurement and modeling capabilities for next-generation computing systems
“I’m cautiously optimistic about the future of energy-efficient computing. The ASCR report says, from a technological point of view, there are things we can do,” said Vuduc.
“The report lays out paths for how we might design better apps, hardware systems, and algorithms that will use less energy. This is recognition that we should think about how architectures and software work together to drive down energy usage for systems.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Feb. 26, 2026

Georgia Tech’s faculty startup engine Quadrant-i, together with the Space Research Institute (SRI), launched the first cohort of the CreationsVC Space Fellows Program. Funded by space technology venture capital firm CreationsVC, the program enables faculty to explore promising early-stage innovations and their potential for future commercial impact.
“This first set of CreationsVC Fellows offers an exciting cross-section of innovative hardware and software technologies built on Georgia Tech’s legacy of space exploration, hardware development, and product commercialization,” said Jud Ready, SRI executive director.
In the first year of the three-year program, CreationsVC provides $125,000 to promote and accelerate innovations that have both space and terrestrial applications. The series offers participants training focused on customer discovery, engaging and compelling storytelling, value proposition design and quantification, and lean/agile project/product management.
“CreationsVC is centered on a deep appreciation for innovation and big thinking,” said Steve Braverman, co-founder and managing partner of CreationsVC. “We felt this was the right time to align our efforts in sourcing and supporting dual-value technologies that will have an impact on both Earth and space.”
The six startups tackle real-world space research problems like supply chain management, how artificial intelligence works in space, and navigation.
“We are excited CreationsVC is providing us with an opportunity to try new approaches to accelerate deep tech development,” said Jonathan Goldman, Quadrant-i’s director. “These are the toughest kinds of startups to build, and we look forward to the learning we will gain from forcing our innovators out of their comfort zones to embrace some new and valuable skills.”
Meet the cohort:
Company: CIMTech.ai
Founders: Shimeng Yu, James Read
School: School of Electrical and Computer Engineering (ECE)
Objective: To develop energy-efficient, radiation-tolerant artificial intelligence processors using a persistent type of ferroelectric memory. The startup aims to improve applications requiring high power efficiency, such as battery-powered devices and space-based systems.
Why Q-i: “The advantage of Q-i is in helping technical founders turn their research into products that solve customers’ problems,” noted James Read. “For us, that means talking with potential customers and hearing their pain points directly from the source. Now we’re use that information to build a convincing narrative around our startup’s value for stakeholders and investors.”
Company: SkyCT
Founders: Morris Cohen, Matthew Strong
School: ECE
Objective: To provide up-to-date mapping of the electrical properties of the upper atmosphere, with applications to GPS-free navigation, long-range communication, and satellite and launch vehicle viability. The startup uses the radio energy released by lightning strikes to create this map.
Why Q-i: “This weird region about 50 miles up from Earth’s surface is both really hard to track and measure, and also impacts a surprising array of applications,” said Cohen. “It’s sometimes called the `ignorosphere’ because of how difficult it is to measure, and it’s time we change that.”
Company: Penumbra Autonomy
Founders: Panagiotis Tsiotras, Juan Diego Florez-Castillo, Iason Velentzas
School: Daniel Guggenheim School of Aerospace Engineering (AE)
Objective: To commercialize algorithms that help spacecraft maneuver when they have limited information on their environment. The algorithms use state-of-the-art computer vision and localization techniques. This could benefit manufacturing, assembly, and refueling in orbit, as well as enable monitoring, situational awareness, and debris removal.
Why Q-i: “The program offers a conduit to entrepreneurship opportunities and spinoff companies in the space domain by providing guidance and commercialization ‘know-how,’” said Panagiotis Tsiotras.
Company: TerraMorph
Founders: Yashwanth Kumar Nakka, Sadhana Kumar, Vincent Griffo, Sachin Kelkar
School: AE
Objective: To create an autonomous rover platform with adaptive, reconfigurable mobility. The rover will implement software and sensing algorithms to automatically detect terrain type and improve traction and energy usage. This could be used on the moon or Mars, or even terrestrial search and rescue.
Why Q-i: “TerraMorph was developed to address fundamental challenges in mobility and autonomy across uncertain terrain, but successfully translating that work into impact requires creative guidance, critical feedback, and experienced perspectives beyond the lab,” said Yashwanth Kumar Nakka. “Q-i’s culture of leading by example and fostering strong, ethical teams aligns closely with how we want to build TerraMorph: iteratively, thoughtfully, and with a focus on real-world deployment.”
Company: OpenWerks
Founders: Shreyes Melkote, Mike Yan
School: George W. Woodruff School of Mechanical Engineering
Objective: To deliver real-time manufacturing supply chain visibility for the space and national security industries. OpenWerks technology aims to dramatically reduce current sourcing cycles from eight months down to weeks by connecting corporate buyers directly with verified supplier manufacturing capability and capacity data.
Why Q-i: “From the very beginning, principals at VentureLab and Q-i offered a clear pathway to translate academic research into a viable business,” said Mike Yan. “Their reputation for guiding Georgia Tech startups through both business and technology derisking, combined with their comprehensive ecosystem of programs and coaches, made them the natural partner for our entrepreneurial journey.”
Company: 8Seven8
Founders: Chandra Raman
School: School of Physics
Objective: To manufacture quantum hardware in Georgia. 8Seven8 aims to put high-precision atomic clocks and gyroscopes on a chip for applications ranging from aircraft navigation to industrial automation.
Why Q-i: “They have mentored me and my students through the commercialization process, providing opportunities such as the Space Fellows Cohort,” Chandra Raman said. “One of my former students, Alexandra Crawford, gained valuable business experience through a Q-i entrepreneur’s assistantship, and is now working at 8Seven8 full-time. They have also guided me through the process of obtaining funding through the Georgia Research Alliance for our commercialization effort.”
News Contact
Tess Malone
Senior Research Writer/Editor
Georgia Tech
Feb. 24, 2026

Written by: Anne Wainscott-Sargent
As artificial intelligence (AI) drives explosive growth in data centers, communities across the U.S. are facing rising electricity costs, new industrial development, and mounting strain on an aging power grid.
At Georgia Tech, several faculty members are approaching these sustainability challenges from different but complementary angles: examining how data center policy affects local communities, modeling how AI-driven demand reshapes regional energy systems, and building tools that help the public understand the tradeoffs embedded in grid planning. Together, their work highlights how better data, thoughtful policy, and public engagement can guide more resilient and equitable decisions in an AI-powered future.
AI’s Hidden Footprint: How Data Centers Reshape Communities
Ahmed Saeed studies the infrastructure most people never see. An assistant professor in the School of Computer Science and a Brook Byers Institute for Sustainable Systems (BBISS) Faculty Fellow, Saeed focuses on how data centers — the backbone of modern AI — are built, operated, and regulated, and what their growth means for host communities.
“Data centers are the infrastructure for our digital life, so more of them are necessary to keep doing what we’re doing,” he said.
Data center energy consumption could double or triple by 2028, accounting for up to 12% of U.S. electricity use, according to a report by Lawrence Berkeley National Laboratory. U.S. spending on data center construction jumped nearly 70% between May 2023 and May 2024, according to the American Edge Project.
Georgia is an AI data center hub, ranked fourth globally, with $4.6 billion in AI-related venture capital invested across 368 deals, the American Edge Project reported. At a recent town hall in DeKalb County, Georgia, Saeed helped residents connect AI’s promise to its local consequences. Training large AI models can require tens of thousands of graphics processing units (GPUs) running for days or weeks, driving an unprecedented wave of data center construction. AI-focused chips, he noted, can consume 10 to 14 times more power than traditional processors.
That demand often shows up as pressure on local infrastructure. Communities are increasingly concerned about electricity and water use, grid upgrades, and who ultimately pays. In Virginia, Saeed pointed to a legal dispute in which consumer advocates warned that data centers could raise electricity bills by 5% in the short term and up to 50% over time, while utilities argued those investments were inevitable and could benefit customers in the long run.
Environmental concerns add another layer. Saeed cited controversies over water use and backup diesel generators in states, including Georgia and Tennessee, alongside a recent Environmental Protection Agency (EPA) ruling that tightened generator regulations. While diesel generators are clearly harmful, he cautioned that long-term, rigorous evidence linking data centers to regional health impacts remains limited.
Saeed’s research aims to reduce those impacts directly. By optimizing how workloads are scheduled across large server fleets, his team has demonstrated power savings of 4 – 12%, a meaningful gain if U.S. data centers approach projected levels of up to 12% of national electricity use by 2028.
For Saeed, data centers are akin to highways: essential to modern life, disruptive to nearby communities, and shaped by policy choices. The question, he argues, is not whether AI infrastructure should exist, but how transparently and fairly it is built.
Economist Probes the Energy Costs of the AI Boom
While headlines often frame AI as an energy crisis, Georgia Tech environmental and energy economist and BBISS Faculty Fellow Tony Harding is focused on measuring its real — and uneven — impacts. Harding, an assistant professor in the Jimmy and Rosalynn Carter School of Public Policy, uses economic modeling to examine how AI adoption affects energy use, emissions, and local communities.
In recent work published in Environmental Research Letters, Harding and his co-author analyzed how productivity gains from AI could influence national energy demand. Their findings suggest that, at a macro level, AI-related activity may increase annual U.S. energy use by about 0.03% and CO₂ emissions by roughly 0.02%.
“Those numbers are small in the context of the overall economy,” Harding said. “But the impacts are highly uneven.”
That unevenness is evident in where data centers are built. While Northern Virginia remains the country’s top data center hub, with 343 operational data centers, states like Georgia, which currently has 94 operational data centers, are rapidly attracting facilities due to reliable power and favorable tax policies.
Harding’s latest research focuses on local effects, asking why data centers cluster in urban areas, how they influence housing markets, what happens to electricity prices, and whether they exacerbate water stress. Early evidence suggests large facilities can increase local electricity rates, contributing to public backlash and regulatory response. In Georgia, the Public Service Commission has begun requiring new, high power draw customers (like data centers) to cover more of the costs associated with grid expansion.
Harding’s goal is to give policymakers better evidence to design incentives and guardrails. “To manage these technologies responsibly,” he said, “we need a clear picture of their intended and unintended consequences.”
Gamifying a Strained and Aging Power Grid
Daniel Molzahn is tackling another side of the problem: how to modernize an aging power grid under growing demand. Electricity demand is expected to rise about 25% by 2030, driven by data centers, electric vehicles, and broadscale electrification. At the same time, much of the U.S. electricity grid is nearing the end of its lifespan, with many transformers being decades old.
To make these challenges tangible, Molzahn, an associate professor in the School of Electrical and Computer Engineering, developed a browser-based game with a group of students through Georgia Tech’s Vertically Integrated Projects program called Current Crisis. Players take on the role of a utility decision-maker, balancing reliability, wildfire risk, renewable integration, and affordability.
The game grew out of Molzahn’s National Science Foundation CAREER award and reflects his belief that complex systems are best understood experientially. Its initial focus is wildfire resilience, modeling how grid infrastructure can both spark and suffer damage from fires.
But resilience comes at a cost. Burying power lines, for example, reduces wildfire risk but dramatically increases expenses. Players must confront the same tradeoffs utilities face: improve reliability or keep rates low.
Molzahn hopes the game will help students and the public grapple with the realities of planning future power systems. “These choices aren’t abstract,” he said. “They shape affordability, resilience, and our path toward a cleaner grid.”
The project now involves nearly 40 students from across campus, supported by Sustainability NEXT funding and a collaboration with Jessica Roberts, former BBISS Faculty Fellow and director of the Technology-Integrated Learning Environments (TILES) Lab in the School of Interactive Computing.
“As a learning scientist, I look at how to engage people with science and scientific data and get people having conversations they might not otherwise have,” says Roberts, who hopes the seed grant helps the team determine first that they are going in the right direction and, second, how to broaden the impact.
One student, Stella Quinto Lima, a graduate research assistant in Human-Centered Computing, has made the game the focus of her doctoral thesis. Through the game, she wants players to notice their misconceptions about the power grid, energy use, and AI, and to use critical thinking to identify, question, and possibly undo those misconceptions.
“I hope that we can really engage adults and help them see it’s not black and white. The game is not only about power grids, but how AI affects the grid, how it affects our lives, and how it will impact our future.”
The team plans to expand the game’s features, use it in outreach programs, and analyze player decisions as a source of data to study energy-system decision-making.
“We want to change the conversation about power and power grid stability, reliability, and sustainability, Roberts said, “and find a way to get this message to a larger public.”
News Contact
Brent Verrill, Research Communications Program Manager, BBISS
Feb. 24, 2026
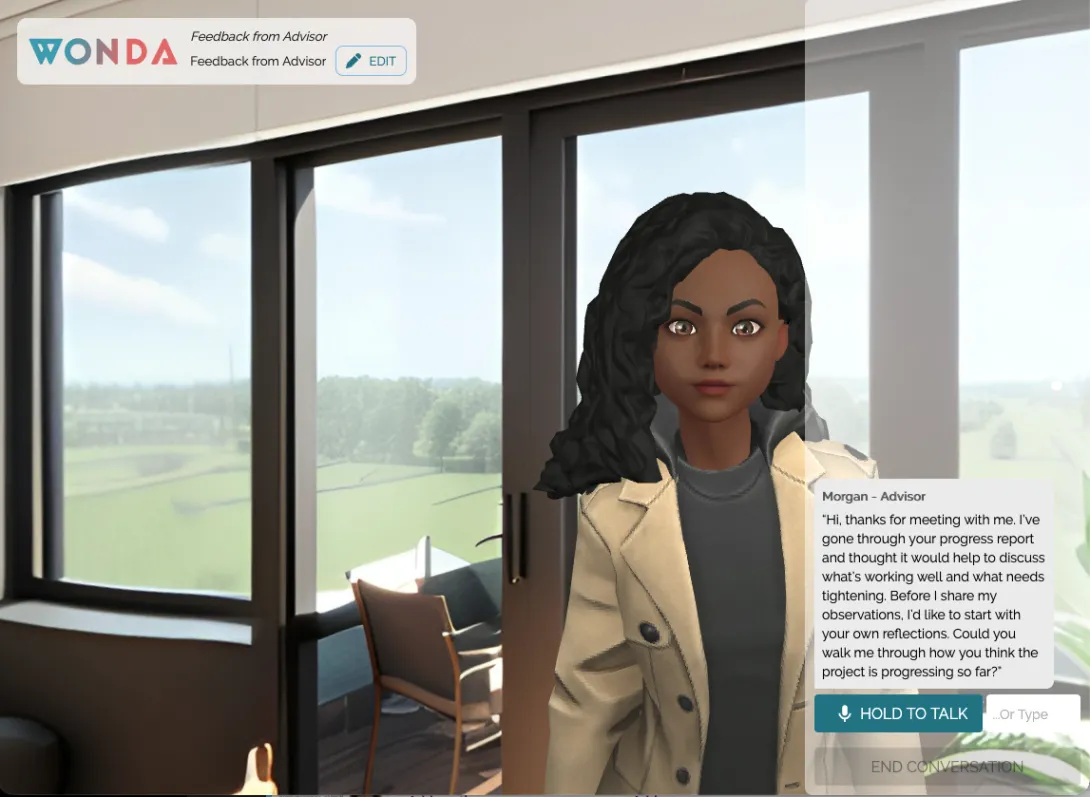
Two research teams within the College of Lifetime Learning are piloting new approaches to online education that integrate artificial intelligence and immersive virtual reality with thoughtful instructional design. More than technology experiments, these projects show how the College refines learning innovations before scaling them across programs.
Research Scientists Eunhye Grace Flavin, Abeera Rehmat, and Jeonghyun (Jonna) Lee are developing an AI-assisted course titled Design of Learning Environments. The course is being piloted within the College to gather feedback and data before broader implementation.
“We want to study how AI can meaningfully support learning,” Flavin said, “and how it can deepen engagement and enhance instructional design rather than distract from it.”
Faculty and staff are contributing in two ways: some are enrolling in the course and participating in AI-supported activities and surveys, while others are reviewing instructional models and providing feedback. Insights from both groups will guide refinements before future rollout.
Meanwhile, Research Scientists Meryem Yılmaz Soylu and Jeonghyun (Jonna) Lee, along with Research Associate Eric Sembrat, are piloting an immersive VR module within the Online Master of Science in Analytics (OMSA) program. The module features case-based scenarios with a virtual agent, enabling students to practice leadership and workplace decision-making in realistic environments.
“Technical expertise alone is no longer enough. Our students need opportunities to practice leadership, navigate conflict, and communicate across stakeholders in realistic settings. Virtual reality allows us to create emotionally resonant, high-stakes scenarios in a safe environment where students can experiment, reflect, and grow,” Yılmaz Soylu said.
The VR experience uses branching 360° scenarios in which students’ communication choices and strategic decisions influence virtual stakeholders’ responses in real time. Insights from the pilot will inform refinements to strengthen usability, instructional alignment, and scalability before broader implementation.
“In many ways, we are building the future of online learning. We’re asking what works and what supports learning. It’s incredibly exciting to be part of a college that embraces this sort of thoughtful experimentation. Innovation like this can help us responsibly design courses for the individuals we serve,” Flavin said.
The VR module is being developed in collaboration with Lifetime Learning colleagues in instructional design, media production, and technology, as well as partners across Georgia Tech, including OMSA leadership and faculty collaborators.
Together, these initiatives reflect the College’s approach to innovation: integrating research, technology, and delivery to improve learning systems. By piloting and refining new models before scaling, the College strengthens its capacity to expand access while preserving quality and meaningful outcomes for learners across career stages.
News Contact
Yelena M. Rivera-Vale (she/her(s)/ella)
Communications Program Manager
C21U, College of Lifetime Learning