Feb. 10, 2025

When Ashley Cotsman arrived as a freshman at Georgia Tech, she didn’t know how to code. Now, the fourth-year Public Policy student is leading a research project on AI and decarbonization technologies.
When Cotsman joined the Data Science and Policy Lab as a first-year student, “I had zero skills or knowledge in big data, coding, anything like that,” she said.
But she was enthusiastic about the work. And the lab, led by Associate Professor Omar Asensio in the School of Public Policy, included Ph.D., master’s, and undergraduate students from a variety of degree programs who taught Cotsman how to code on the fly.
She learned how to run simple scripts and web scrapes and assisted with statistical analyses, policy research, writing, and editing. At 19, Cotsman was published for the first time. Now, she’s gone from mentee to mentor and is leading one of the research projects in the lab.
“I feel like I was just this little freshman who had no clue what I was doing, and I blinked, and now I’m conceptualizing a project and coming up with the research design and writing — it’s a very surreal moment,” she said.

Cotsman, right, presenting a research poster on electric vehicle charging infrastructure, another project she worked on with Asensio and the Data Science and Policy Lab.
What’s the project about?
Cotsman’s project. “Scaling Sustainability Evaluations Through Generative Artificial Intelligence.” uses the large language model GPT-4 to analyze the sea of sustainability reports organizations in every sector publish each year.
The authors, including Celina Scott-Buechler at Stanford University, Lucrezia Nava at University of Exeter, David Reiner at University of Cambridge Judge Business School and Asensio, aim to understand how favorability toward decarbonization technologies vary by industry and over time.
“There are thousands of reports, and they are often long and filled with technical jargon,” Cotsman said. “From a policymaker’s standpoint, it’s difficult to get through. So, we are trying to create a scalable, efficient, and accurate way to quickly read all these reports and get the information.”
How is it done?
The team trained a GPT-4 model to search, analyze, and see trends across 95,000 mentions of specific technologies over 25 years of sustainability reports. What would take someone 80 working days to read and evaluate took the model about eight hours, Cotsman said. And notably, GPT-4 did not require extensive task-specific training data and uniformly applied the same rules to all the data it analyzed, she added.
So, rather than fine-tuning with thousands of human-labeled examples, “it’s more like prompt engineering,” Cotsman said. “Our research demonstrates what logic and safeguards to include in a prompt and the best way to create prompts to get these results.”
The team used chain-of-thought prompting, which guides generative AI systems through each step of its reasoning process with context reasoning, counterexamples, and exceptions, rather than just asking for the answer. They combined this with few-shot learning for misidentified cases, which provides increasingly refined examples for additional guidance, a process the AI community calls “alignment.”
The final prompt included definitions of favorable, neutral, and opposing communications, an example of how each might appear in the text, and an example of how to classify nuanced wording, values, or human principles as well.
It achieved a .86 F1 score, which essentially measures how well the model gets things right on a scale from zero to one. The score is “very high” for a project with essentially zero training data and a specialized dataset, Cotsman said. In contrast, her first project with the group used a large language model called BERT and required 9,000 lines of expert-labeled training data to achieve a similar F1 score.
“It’s wild to me that just two years ago, we spent months and months training these models,” Cotsman said. “We had to annotate all this data and secure dedicated compute nodes or GPUs. It was painstaking. It was expensive. It took so long. And now, two years later, here I am. Just one person with zero training data, able to use these tools in such a scalable, efficient, and accurate way.”

Through the Federal Jackets Fellowship program, Cotsman was able to spend the Fall 2024 semester as a legislative intern in Washington, D.C.
Why does it matter?
While Cotsman’s colleagues focus on the results of the project, she is more interested in the methodology. The prompts can be used for preference learning on any type of “unstructured data,” such as video or social media posts, especially those examining technology adoption for environmental issues. Asensio and the Data Science and Policy team use the technique in many of their recent projects.
“We can very quickly use GPT-4 to read through these things and pull out insights that are difficult to do with traditional coding,” Cotsman said. “Obviously, the results will be interesting on the electrification and carbon side. But what I’ve found so interesting is how we can use these emerging technologies as tools for better policymaking.”
While concerns over the speed of development of AI is justifiable, she said, Cotsman’s research experience at Georgia Tech has given her an optimistic view of the new technology.
“I’ve seen very quickly how, when used for good, these things will transform our world for the better. From the policy standpoint, we’re going to need a lot of regulation. But from the standpoint of academia and research, if we embrace these things and use them for good, I think the opportunities are endless for what we can do.”
Dec. 04, 2024


Georgia Tech researchers have created a dataset that trains computer models to understand nuances in human speech during financial earnings calls. The dataset provides a new resource to study how public correspondence affects businesses and markets.
SubjECTive-QA is the first human-curated dataset on question-answer pairs from earnings call transcripts (ECTs). The dataset teaches models to identify subjective features in ECTs, like clarity and cautiousness.
The dataset lays the foundation for a new approach to identifying disinformation and misinformation caused by nuances in speech. While ECT responses can be technically true, unclear or irrelevant information can misinform stakeholders and affect their decision-making.
Tests on White House press briefings showed that the dataset applies to other sectors with frequent question-and-answer encounters, notably politics, journalism, and sports. This increases the odds of effectively informing audiences and improving transparency across public spheres.
The intersecting work between natural language processing and finance earned the paper acceptance to NeurIPS 2024, the 38th Annual Conference on Neural Information Processing Systems. NeurIPS is one of the world’s most prestigious conferences on artificial intelligence (AI) and machine learning (ML) research.
"SubjECTive-QA has the potential to revolutionize nowcasting predictions with enhanced clarity and relevance,” said Agam Shah, the project’s lead researcher.
“Its nuanced analysis of qualities in executive responses, like optimism and cautiousness, deepens our understanding of economic forecasts and financial transparency."
[MICROSITE: Georgia Tech at NeurIPS 2024]
SubjECTive-QA offers a new means to evaluate financial discourse by characterizing language's subjective and multifaceted nature. This improves on traditional datasets that quantify sentiment or verify claims from financial statements.
The dataset consists of 2,747 Q&A pairs taken from 120 ECTs from companies listed on the New York Stock Exchange from 2007 to 2021. The Georgia Tech researchers annotated each response by hand based on six features for a total of 49,446 annotations.
The group evaluated answers on:
- Relevance: the speaker answered the question with appropriate details.
- Clarity: the speaker was transparent in the answer and the message conveyed.
- Optimism: the speaker answered with a positive outlook regarding future outcomes.
- Specificity: the speaker included sufficient and technical details in their answer.
- Cautiousness: the speaker answered using a conservative, risk-averse approach.
- Assertiveness: the speaker answered with certainty about the company’s events and outcomes.
The Georgia Tech group validated their dataset by training eight computer models to detect and score these six features. Test models comprised of three BERT-based pre-trained language models (PLMs), and five popular large language models (LLMs) including Llama and ChatGPT.
All eight models scored the highest on the relevance and clarity features. This is attributed to domain-specific pretraining that enables the models to identify pertinent and understandable material.
The PLMs achieved higher scores on the clear, optimistic, specific, and cautious categories. The LLMs scored higher in assertiveness and relevance.
In another experiment to test transferability, a PLM trained with SubjECTive-QA evaluated 65 Q&A pairs from White House press briefings and gaggles. Scores across all six features indicated models trained on the dataset could succeed in other fields outside of finance.
"Building on these promising results, the next step for SubjECTive-QA is to enhance customer service technologies, like chatbots,” said Shah, a Ph.D. candidate studying machine learning.
“We want to make these platforms more responsive and accurate by integrating our analysis techniques from SubjECTive-QA."
SubjECTive-QA culminated from two semesters of work through Georgia Tech’s Vertically Integrated Projects (VIP) Program. The VIP Program is an approach to higher education where undergraduate and graduate students work together on long-term project teams led by faculty.
Undergraduate students earn academic credit and receive hands-on experience through VIP projects. The extra help advances ongoing research and gives graduate students mentorship experience.
Computer science major Huzaifa Pardawala and mathematics major Siddhant Sukhani co-led the SubjECTive-QA project with Shah.
Fellow collaborators included Veer Kejriwal, Abhishek Pillai, Rohan Bhasin, Andrew DiBiasio, Tarun Mandapati, and Dhruv Adha. All six researchers are undergraduate students studying computer science.
Sudheer Chava co-advises Shah and is the faculty lead of SubjECTive-QA. Chava is a professor in the Scheller College of Business and director of the M.S. in Quantitative and Computational Finance (QCF) program.
Chava is also an adjunct faculty member in the College of Computing’s School of Computational Science and Engineering (CSE).
"Leading undergraduate students through the VIP Program taught me the powerful impact of balancing freedom with guidance,” Shah said.
“Allowing students to take the helm not only fosters their leadership skills but also enhances my own approach to mentoring, thus creating a mutually enriching educational experience.”
Presenting SubjECTive-QA at NeurIPS 2024 exposes the dataset for further use and refinement. NeurIPS is one of three primary international conferences on high-impact research in AI and ML. The conference occurs Dec. 10-15.
The SubjECTive-QA team is among the 162 Georgia Tech researchers presenting over 80 papers at NeurIPS 2024. The Georgia Tech contingent includes 46 faculty members, like Chava. These faculty represent Georgia Tech’s Colleges of Business, Computing, Engineering, and Sciences, underscoring the pertinence of AI research across domains.
"Presenting SubjECTive-QA at prestigious venues like NeurIPS propels our research into the spotlight, drawing the attention of key players in finance and tech,” Shah said.
“The feedback we receive from this community of experts validates our approach and opens new avenues for future innovation, setting the stage for transformative applications in industry and academia.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Dec. 04, 2024


A new machine learning (ML) model from Georgia Tech could protect communities from diseases, better manage electricity consumption in cities, and promote business growth, all at the same time.
Researchers from the School of Computational Science and Engineering (CSE) created the Large Pre-Trained Time-Series Model (LPTM) framework. LPTM is a single foundational model that completes forecasting tasks across a broad range of domains.
Along with performing as well or better than models purpose-built for their applications, LPTM requires 40% less data and 50% less training time than current baselines. In some cases, LPTM can be deployed without any training data.
The key to LPTM is that it is pre-trained on datasets from different industries like healthcare, transportation, and energy. The Georgia Tech group created an adaptive segmentation module to make effective use of these vastly different datasets.
The Georgia Tech researchers will present LPTM in Vancouver, British Columbia, Canada, at the 2024 Conference on Neural Information Processing Systems (NeurIPS 2024). NeurIPS is one of the world’s most prestigious conferences on artificial intelligence (AI) and ML research.
“The foundational model paradigm started with text and image, but people haven’t explored time-series tasks yet because those were considered too diverse across domains,” said B. Aditya Prakash, one of LPTM’s developers.
“Our work is a pioneer in this new area of exploration where only few attempts have been made so far.”
[MICROSITE: Georgia Tech at NeurIPS 2024]
Foundational models are trained with data from different fields, making them powerful tools when assigned tasks. Foundational models drive GPT, DALL-E, and other popular generative AI platforms used today. LPTM is different though because it is geared toward time-series, not text and image generation.
The Georgia Tech researchers trained LPTM on data ranging from epidemics, macroeconomics, power consumption, traffic and transportation, stock markets, and human motion and behavioral datasets.
After training, the group pitted LPTM against 17 other models to make forecasts as close to nine real-case benchmarks. LPTM performed the best on five datasets and placed second on the other four.
The nine benchmarks contained data from real-world collections. These included the spread of influenza in the U.S. and Japan, electricity, traffic, and taxi demand in New York, and financial markets.
The competitor models were purpose-built for their fields. While each model performed well on one or two benchmarks closest to its designed purpose, the models ranked in the middle or bottom on others.
In another experiment, the Georgia Tech group tested LPTM against seven baseline models on the same nine benchmarks in zero-shot forecasting tasks. Zero-shot means the model is used out of the box and not given any specific guidance during training. LPTM outperformed every model across all benchmarks in this trial.
LPTM performed consistently as a top-runner on all nine benchmarks, demonstrating the model’s potential to achieve superior forecasting results across multiple applications with less and resources.
“Our model also goes beyond forecasting and helps accomplish other tasks,” said Prakash, an associate professor in the School of CSE.
“Classification is a useful time-series task that allows us to understand the nature of the time-series and label whether that time-series is something we understand or is new.”
One reason traditional models are custom-built to their purpose is that fields differ in reporting frequency and trends.
For example, epidemic data is often reported weekly and goes through seasonal peaks with occasional outbreaks. Economic data is captured quarterly and typically remains consistent and monotone over time.
LPTM’s adaptive segmentation module allows it to overcome these timing differences across datasets. When LPTM receives a dataset, the module breaks data into segments of different sizes. Then, it scores all possible ways to segment data and chooses the easiest segment from which to learn useful patterns.
LPTM’s performance, enhanced through the innovation of adaptive segmentation, earned the model acceptance to NeurIPS 2024 for presentation. NeurIPS is one of three primary international conferences on high-impact research in AI and ML. NeurIPS 2024 occurs Dec. 10-15.
Ph.D. student Harshavardhan Kamarthi partnered with Prakash, his advisor, on LPTM. The duo are among the 162 Georgia Tech researchers presenting over 80 papers at the conference.
Prakash is one of 46 Georgia Tech faculty with research accepted at NeurIPS 2024. Nine School of CSE faculty members, nearly one-third of the body, are authors or co-authors of 17 papers accepted at the conference.
Along with sharing their research at NeurIPS 2024, Prakash and Kamarthi released an open-source library of foundational time-series modules that data scientists can use in their applications.
“Given the interest in AI from all walks of life, including business, social, and research and development sectors, a lot of work has been done and thousands of strong papers are submitted to the main AI conferences,” Prakash said.
“Acceptance of our paper speaks to the quality of the work and its potential to advance foundational methodology, and we hope to share that with a larger audience.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Oct. 24, 2024

Eight Georgia Tech researchers were honored with the ACM Distinguished Paper Award for their groundbreaking contributions to cybersecurity at the recent ACM Conference on Computer and Communications Security (CCS).
Three papers were recognized for addressing critical challenges in the field, spanning areas such as automotive cybersecurity, password security, and cryptographic testing.
“These three projects underscore Georgia Tech's leadership in advancing cybersecurity solutions that have real-world impact, from protecting critical infrastructure to ensuring the security of future computing systems and improving everyday digital practices,” said School of Cybersecurity and Privacy (SCP) Chair Michael Bailey.
One of the papers, ERACAN: Defending Against an Emerging CAN Threat Model, was co-authored by Ph.D. student Zhaozhou Tang, Associate Professor Saman Zonouz, and College of Engineering Dean and Professor Raheem Beyah. This research focuses on securing the controller area network (CAN), a vital system used in modern vehicles that is increasingly targeted by cyber threats.
"This project is led by our Ph.D. student Zhaozhou Tang with the Cyber-Physical Systems Security (CPSec) Lab," said Zonouz. "Impressively, this was Zhaozhou's first paper in his Ph.D., and he deserves special recognition for this groundbreaking work on automotive cybersecurity."
The work introduces a comprehensive defense system to counter advanced threats to vehicular CAN networks, and the team is collaborating with the Hyundai America Technical Center to implement the research. The CPSec Lab is a collaborative effort between SCP and the School of Electrical and Computer Engineering (ECE).
In another paper, Testing Side-Channel Security of Cryptographic Implementations Against Future Microarchitectures, Assistant Professor Daniel Genkin collaborated with international researchers to define security threats in new computing technology.
"We appreciate ACM for recognizing our work," said Genkin. “Tools for early-stage testing of CPUs for emerging side-channel threats are crucial to ensuring the security of the next generation of computing devices.”
The third paper, Unmasking the Security and Usability of Password Masking, was authored by graduate students Yuqi Hu, Suood Al Roomi, Sena Sahin, and Frank Li, SCP and ECE assistant professor. This study investigated the effectiveness and provided recommendations for implementing password masking and the practice of hiding characters as they are typed and offered.
"Password masking is a widely deployed security mechanism that hasn't been extensively investigated in prior works," said Li.
The assistant professor credited the collaborative efforts of his students, particularly Yuqi Hu, for leading the project.
The ACM Conference on Computer and Communications Security (CCS) is the flagship annual conference of the Special Interest Group on Security, Audit and Control (SIGSAC) of the Association for Computing Machinery (ACM). The conference was held from Oct. 14-18 in Salt Lake City.
News Contact
John Popham
Communications Officer II
College of Computing | School of Cybersecurity and Privacy
Oct. 16, 2024



A new surgery planning tool powered by augmented reality (AR) is in development for doctors who need closer collaboration when planning heart operations. Promising results from a recent usability test have moved the platform one step closer to everyday use in hospitals worldwide.
Georgia Tech researchers partnered with medical experts from Children’s Healthcare of Atlanta (CHOA) to develop and test ARCollab. The iOS-based app leverages advanced AR technologies to let doctors collaborate together and interact with a patient’s 3D heart model when planning surgeries.
The usability evaluation demonstrates the app’s effectiveness, finding that ARCollab is easy to use and understand, fosters collaboration, and improves surgical planning.
“This tool is a step toward easier collaborative surgical planning. ARCollab could reduce the reliance on physical heart models, saving hours and even days of time while maintaining the collaborative nature of surgical planning,” said M.S. student Pratham Mehta, the app’s lead researcher.
“Not only can it benefit doctors when planning for surgery, it may also serve as a teaching tool to explain heart deformities and problems to patients.”
Two cardiologists and three cardiothoracic surgeons from CHOA tested ARCollab. The two-day study ended with the doctors taking a 14-question survey assessing the app’s usability. The survey also solicited general feedback and top features.
The Georgia Tech group determined from the open-ended feedback that:
- ARCollab enables new collaboration capabilities that are easy to use and facilitate surgical planning.
- Anchoring the model to a physical space is important for better interaction.
- Portability and real-time interaction are crucial for collaborative surgical planning.
Users rated each of the 14 questions on a 7-point Likert scale, with one being “strongly disagree” and seven being “strongly agree.” The 14 questions were organized into five categories: overall, multi-user, model viewing, model slicing, and saving and loading models.
The multi-user category attained the highest rating with an average of 6.65. This included a unanimous 7.0 rating that it was easy to identify who was controlling the heart model in ARCollab. The scores also showed it was easy for users to connect with devices, switch between viewing and slicing, and view other users’ interactions.
The model slicing category received the lowest, but formidable, average of 5.5. These questions assessed ease of use and understanding of finger gestures and usefulness to toggle slice direction.
Based on feedback, the researchers will explore adding support for remote collaboration. This would assist doctors in collaborating when not in a shared physical space. Another improvement is extending the save feature to support multiple states.
“The surgeons and cardiologists found it extremely beneficial for multiple people to be able to view the model and collaboratively interact with it in real-time,” Mehta said.
The user study took place in a CHOA classroom. CHOA also provided a 3D heart model for the test using anonymous medical imaging data. Georgia Tech’s Institutional Review Board (IRB) approved the study and the group collected data in accordance with Institute policies.
The five test participants regularly perform cardiovascular surgical procedures and are employed by CHOA.
The Georgia Tech group provided each participant with an iPad Pro with the latest iOS version and the ARCollab app installed. Using commercial devices and software meets the group’s intentions to make the tool universally available and deployable.
“We plan to continue iterating ARCollab based on the feedback from the users,” Mehta said.
“The participants suggested the addition of a ‘distance collaboration’ mode, enabling doctors to collaborate even if they are not in the same physical environment. This allows them to facilitate surgical planning sessions from home or otherwise.”
The Georgia Tech researchers are presenting ARCollab and the user study results at IEEE VIS 2024, the Institute of Electrical and Electronics Engineers (IEEE) visualization conference.
IEEE VIS is the world’s most prestigious conference for visualization research and the second-highest rated conference for computer graphics. It takes place virtually Oct. 13-18, moved from its venue in St. Pete Beach, Florida, due to Hurricane Milton.
The ARCollab research group's presentation at IEEE VIS comes months after they shared their work at the Conference on Human Factors in Computing Systems (CHI 2024).
Undergraduate student Rahul Narayanan and alumni Harsha Karanth (M.S. CS 2024) and Haoyang (Alex) Yang (CS 2022, M.S. CS 2023) co-authored the paper with Mehta. They study under Polo Chau, a professor in the School of Computational Science and Engineering.
The Georgia Tech group partnered with Dr. Timothy Slesnick and Dr. Fawwaz Shaw from CHOA on ARCollab’s development and user testing.
"I'm grateful for these opportunities since I get to showcase the team's hard work," Mehta said.
“I can meet other like-minded researchers and students who share these interests in visualization and human-computer interaction. There is no better form of learning.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Sep. 19, 2024



A new algorithm tested on NASA’s Perseverance Rover on Mars may lead to better forecasting of hurricanes, wildfires, and other extreme weather events that impact millions globally.
Georgia Tech Ph.D. student Austin P. Wright is first author of a paper that introduces Nested Fusion. The new algorithm improves scientists’ ability to search for past signs of life on the Martian surface.
In addition to supporting NASA’s Mars 2020 mission, scientists from other fields working with large, overlapping datasets can use Nested Fusion’s methods toward their studies.
Wright presented Nested Fusion at the 2024 International Conference on Knowledge Discovery and Data Mining (KDD 2024) where it was a runner-up for the best paper award. KDD is widely considered the world's most prestigious conference for knowledge discovery and data mining research.
“Nested Fusion is really useful for researchers in many different domains, not just NASA scientists,” said Wright. “The method visualizes complex datasets that can be difficult to get an overall view of during the initial exploratory stages of analysis.”
Nested Fusion combines datasets with different resolutions to produce a single, high-resolution visual distribution. Using this method, NASA scientists can more easily analyze multiple datasets from various sources at the same time. This can lead to faster studies of Mars’ surface composition to find clues of previous life.
The algorithm demonstrates how data science impacts traditional scientific fields like chemistry, biology, and geology.
Even further, Wright is developing Nested Fusion applications to model shifting climate patterns, plant and animal life, and other concepts in the earth sciences. The same method can combine overlapping datasets from satellite imagery, biomarkers, and climate data.
“Users have extended Nested Fusion and similar algorithms toward earth science contexts, which we have received very positive feedback,” said Wright, who studies machine learning (ML) at Georgia Tech.
“Cross-correlational analysis takes a long time to do and is not done in the initial stages of research when patterns appear and form new hypotheses. Nested Fusion enables people to discover these patterns much earlier.”
Wright is the data science and ML lead for PIXLISE, the software that NASA JPL scientists use to study data from the Mars Perseverance Rover.
Perseverance uses its Planetary Instrument for X-ray Lithochemistry (PIXL) to collect data on mineral composition of Mars’ surface. PIXL’s two main tools that accomplish this are its X-ray Fluorescence (XRF) Spectrometer and Multi-Context Camera (MCC).
When PIXL scans a target area, it creates two co-aligned datasets from the components. XRF collects a sample's fine-scale elemental composition. MCC produces images of a sample to gather visual and physical details like size and shape.
A single XRF spectrum corresponds to approximately 100 MCC imaging pixels for every scan point. Each tool’s unique resolution makes mapping between overlapping data layers challenging. However, Wright and his collaborators designed Nested Fusion to overcome this hurdle.
In addition to progressing data science, Nested Fusion improves NASA scientists' workflow. Using the method, a single scientist can form an initial estimate of a sample’s mineral composition in a matter of hours. Before Nested Fusion, the same task required days of collaboration between teams of experts on each different instrument.
“I think one of the biggest lessons I have taken from this work is that it is valuable to always ground my ML and data science problems in actual, concrete use cases of our collaborators,” Wright said.
“I learn from collaborators what parts of data analysis are important to them and the challenges they face. By understanding these issues, we can discover new ways of formalizing and framing problems in data science.”
Wright presented Nested Fusion at KDD 2024, held Aug. 25-29 in Barcelona, Spain. KDD is an official special interest group of the Association for Computing Machinery. The conference is one of the world’s leading forums for knowledge discovery and data mining research.
Nested Fusion won runner-up for the best paper in the applied data science track, which comprised of over 150 papers. Hundreds of other papers were presented at the conference’s research track, workshops, and tutorials.
Wright’s mentors, Scott Davidoff and Polo Chau, co-authored the Nested Fusion paper. Davidoff is a principal research scientist at the NASA Jet Propulsion Laboratory. Chau is a professor at the Georgia Tech School of Computational Science and Engineering (CSE).
“I was extremely happy that this work was recognized with the best paper runner-up award,” Wright said. “This kind of applied work can sometimes be hard to find the right academic home, so finding communities that appreciate this work is very encouraging.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Sep. 10, 2024

Digital media Ph.D. candidate Yuchen Zhao’s startup aims to revolutionize fitness with VR and biofeedback integration in her startup, BioVR.

Business administration major Ty Christian Thompson and biomedical engineering major Sydney Brown developed their startup, DivineDrive, to maximize hydration and energy while minimizing the risk of injury due to dehydration.

To tackle the issue of too much screen time for kids, Georgia Tech School of Industrial Design research assistant Palak Gupta created Fidgital-Play, a mobile app that reimagines play.

Georgia Tech structural mechanics and materials alumna Katy Bradford and co-founder Jonathan Valz created their Cassette panels to reduce labor needs and construction timelines.

Katy Bradford

Tackling the problem of expensive testing for hospital-acquired infections, Danae Rammos, biomedical engineering major, founded Qualitic Biotechnology LLC, which produces a rapid C. difficile bacterial screening device.

Kicking off a new decade of startup production at Georgia Tech, CREATE-X hosted its 11th Demo Day, showcasing 100 startups created by Georgia Tech students, faculty, researchers, and alumni over 12 weeks this summer. More than 1,500 attendees, including Georgia government and business leaders, viewed new solutions ranging from fashion to healthcare in a bustling Exhibition Hall on Aug. 29.
The event traditionally begins shortly after the semester starts, giving the entrepreneurially curious a preview of what’s to come if they join the program’s accelerator during the next application cycle.
Demo Day is the culmination of the 12-week summer accelerator, Startup Launch, where founders receive mentorship, $5,000 in optional funding, and $150,000 in services to help build their businesses. Teams can be interdisciplinary, made up of co-founders even outside of Georgia Tech, and solopreneurs, ready to solve real-world problems.
Each year, Startup Launch has grown, from an initial cohort of eight startups to over 100 this year. The Office of Commercialization, the home of CREATE-X, plans to keep expanding opportunities for the Georgia Tech community to grow their entrepreneurial skills.
Counting courses, events, programming, and partnerships, CREATE-X has had more than 32,000 participants. The ultimate goal and mission of the program is to instill entrepreneurial confidence in all Tech students. Rahul Saxena, director of the program, spoke about how far the Institute has come in the last decade.
“I’ve been plugged into Georgia Tech for over 10 years. In the past, when you said Georgia Tech and entrepreneurship in the same sentence, they’d laugh, believe it or not,” he said. “Fast-forward, we’re one of the top entrepreneurial schools in the country. Our first four cohorts value over $100 million, with one of them being a unicorn, and our last four cohorts are well on their way. We want our students to have as many shots at gold as possible before they graduate. And even if they decide on a traditional career pathway, we believe they’ll be ahead with this entrepreneurial mindset, which is something lacking in corporate.”
This year, CREATE-X reached over 560 startup teams launched. Founders represented 38 academic majors, and their total startup portfolio valuation exceeds $2 billion.
CREATE-X opened its Startup Launch application for its next cohort on Aug. 30. For those interested, the priority deadline is Nov. 17. Early applicants have a higher chance at acceptance and the opportunity for more feedback. So, send in your applications to Startup Launch and become the next founder at Georgia Tech.
Missed out on Demo Day? Check out the CREATE-X Flickr page to see photos from the event and the Demo Day page to see other teams. For more opportunities to engage, visit the CREATE-X Engage page for upcoming events.
Spotlight on Startups
Some of the standout startups from this year’s Demo Day include:
News Contact
Breanna Durham
Marketing Strategist
Aug. 21, 2024

Montage of five portraits, L to R, T to B: Josiah Hester, Peng Chen, Yongsheng Chen, Rosemarie Santa González, and Joe Bozeman.
- Written by Benjamin Wright -
As Georgia Tech establishes itself as a national leader in AI research and education, some researchers on campus are putting AI to work to help meet sustainability goals in a range of areas including climate change adaptation and mitigation, urban farming, food distribution, and life cycle assessments while also focusing on ways to make sure AI is used ethically.
Josiah Hester, interim associate director for Community-Engaged Research in the Brook Byers Institute for Sustainable Systems (BBISS) and associate professor in the School of Interactive Computing, sees these projects as wins from both a research standpoint and for the local, national, and global communities they could affect.
“These faculty exemplify Georgia Tech's commitment to serving and partnering with communities in our research,” he says. “Sustainability is one of the most pressing issues of our time. AI gives us new tools to build more resilient communities, but the complexities and nuances in applying this emerging suite of technologies can only be solved by community members and researchers working closely together to bridge the gap. This approach to AI for sustainability strengthens the bonds between our university and our communities and makes lasting impacts due to community buy-in.”
Flood Monitoring and Carbon Storage
Peng Chen, assistant professor in the School of Computational Science and Engineering in the College of Computing, focuses on computational mathematics, data science, scientific machine learning, and parallel computing. Chen is combining these areas of expertise to develop algorithms to assist in practical applications such as flood monitoring and carbon dioxide capture and storage.
He is currently working on a National Science Foundation (NSF) project with colleagues in Georgia Tech’s School of City and Regional Planning and from the University of South Florida to develop flood models in the St. Petersburg, Florida area. As a low-lying state with more than 8,400 miles of coastline, Florida is one of the states most at risk from sea level rise and flooding caused by extreme weather events sparked by climate change.
Chen’s novel approach to flood monitoring takes existing high-resolution hydrological and hydrographical mapping and uses machine learning to incorporate real-time updates from social media users and existing traffic cameras to run rapid, low-cost simulations using deep neural networks. Current flood monitoring software is resource and time-intensive. Chen’s goal is to produce live modeling that can be used to warn residents and allocate emergency response resources as conditions change. That information would be available to the general public through a portal his team is working on.
“This project focuses on one particular community in Florida,” Chen says, “but we hope this methodology will be transferable to other locations and situations affected by climate change.”
In addition to the flood-monitoring project in Florida, Chen and his colleagues are developing new methods to improve the reliability and cost-effectiveness of storing carbon dioxide in underground rock formations. The process is plagued with uncertainty about the porosity of the bedrock, the optimal distribution of monitoring wells, and the rate at which carbon dioxide can be injected without over-pressurizing the bedrock, leading to collapse. The new simulations are fast, inexpensive, and minimize the risk of failure, which also decreases the cost of construction.
“Traditional high-fidelity simulation using supercomputers takes hours and lots of resources,” says Chen. “Now we can run these simulations in under one minute using AI models without sacrificing accuracy. Even when you factor in AI training costs, this is a huge savings in time and financial resources.”
Flood monitoring and carbon capture are passion projects for Chen, who sees an opportunity to use artificial intelligence to increase the pace and decrease the cost of problem-solving.
“I’m very excited about the possibility of solving grand challenges in the sustainability area with AI and machine learning models,” he says. “Engineering problems are full of uncertainty, but by using this technology, we can characterize the uncertainty in new ways and propagate it throughout our predictions to optimize designs and maximize performance.”
Urban Farming and Optimization
Yongsheng Chen works at the intersection of food, energy, and water. As the Bonnie W. and Charles W. Moorman Professor in the School of Civil and Environmental Engineering and director of the Nutrients, Energy, and Water Center for Agriculture Technology, Chen is focused on making urban agriculture technologically feasible, financially viable, and, most importantly, sustainable. To do that he’s leveraging AI to speed up the design process and optimize farming and harvesting operations.
Chen’s closed-loop hydroponic system uses anaerobically treated wastewater for fertilization and irrigation by extracting and repurposing nutrients as fertilizer before filtering the water through polymeric membranes with nano-scale pores. Advancing filtration and purification processes depends on finding the right membrane materials to selectively separate contaminants, including antibiotics and per- and polyfluoroalkyl substances (PFAS). Chen and his team are using AI and machine learning to guide membrane material selection and fabrication to make contaminant separation as efficient as possible. Similarly, AI and machine learning are assisting in developing carbon capture materials such as ionic liquids that can retain carbon dioxide generated during wastewater treatment and redirect it to hydroponics systems, boosting food productivity.
“A fundamental angle of our research is that we do not see municipal wastewater as waste,” explains Chen. “It is a resource we can treat and recover components from to supply irrigation, fertilizer, and biogas, all while reducing the amount of energy used in conventional wastewater treatment methods.”
In addition to aiding in materials development, which reduces design time and production costs, Chen is using machine learning to optimize the growing cycle of produce, maximizing nutritional value. His USDA-funded vertical farm uses autonomous robots to measure critical cultivation parameters and take pictures without destroying plants. This data helps determine optimum environmental conditions, fertilizer supply, and harvest timing, resulting in a faster-growing, optimally nutritious plant with less fertilizer waste and lower emissions.
Chen’s work has received considerable federal funding. As the Urban Resilience and Sustainability Thrust Leader within the NSF-funded AI Institute for Advances in Optimization (AI4OPT), he has received additional funding to foster international collaboration in digital agriculture with colleagues across the United States and in Japan, Australia, and India.
Optimizing Food Distribution
At the other end of the agricultural spectrum is postdoc Rosemarie Santa González in the H. Milton Stewart School of Industrial and Systems Engineering, who is conducting her research under the supervision of Professor Chelsea White and Professor Pascal Van Hentenryck, the director of Georgia Tech’s AI Hub as well as the director of AI4OPT.
Santa González is working with the Wisconsin Food Hub Cooperative to help traditional farmers get their products into the hands of consumers as efficiently as possible to reduce hunger and food waste. Preventing food waste is a priority for both the EPA and USDA. Current estimates are that 30 to 40% of the food produced in the United States ends up in landfills, which is a waste of resources on both the production end in the form of land, water, and chemical use, as well as a waste of resources when it comes to disposing of it, not to mention the impact of the greenhouses gases when wasted food decays.
To tackle this problem, Santa González and the Wisconsin Food Hub are helping small-scale farmers access refrigeration facilities and distribution chains. As part of her research, she is helping to develop AI tools that can optimize the logistics of the small-scale farmer supply chain while also making local consumers in underserved areas aware of what’s available so food doesn’t end up in landfills.
“This solution has to be accessible,” she says. “Not just in the sense that the food is accessible, but that the tools we are providing to them are accessible. The end users have to understand the tools and be able to use them. It has to be sustainable as a resource.”
Making AI accessible to people in the community is a core goal of the NSF’s AI Institute for Intelligent Cyberinfrastructure with Computational Learning in the Environment (ICICLE), one of the partners involved with the project.
“A large segment of the population we are working with, which includes historically marginalized communities, has a negative reaction to AI. They think of machines taking over, or data being stolen. Our goal is to democratize AI in these decision-support tools as we work toward the UN Sustainable Development Goal of Zero Hunger. There is so much power in these tools to solve complex problems that have very real results. More people will be fed and less food will spoil before it gets to people’s homes.”
Santa González hopes the tools they are building can be packaged and customized for food co-ops everywhere.
AI and Ethics
Like Santa González, Joe Bozeman III is also focused on the ethical and sustainable deployment of AI and machine learning, especially among marginalized communities. The assistant professor in the School of Civil and Environmental Engineering is an industrial ecologist committed to fostering ethical climate change adaptation and mitigation strategies. His SEEEL Lab works to make sure researchers understand the consequences of decisions before they move from academic concepts to policy decisions, particularly those that rely on data sets involving people and communities.
“With the administration of big data, there is a human tendency to assume that more data means everything is being captured, but that's not necessarily true,” he cautions. “More data could mean we're just capturing more of the data that already exists, while new research shows that we’re not including information from marginalized communities that have historically not been brought into the decision-making process. That includes underrepresented minorities, rural populations, people with disabilities, and neurodivergent people who may not interface with data collection tools.”
Bozeman is concerned that overlooking marginalized communities in data sets will result in decisions that at best ignore them and at worst cause them direct harm.
“Our lab doesn't wait for the negative harms to occur before we start talking about them,” explains Bozeman, who holds a courtesy appointment in the School of Public Policy. “Our lab forecasts what those harms will be so decision-makers and engineers can develop technologies that consider these things.”
He focuses on urbanization, the food-energy-water nexus, and the circular economy. He has found that much of the research in those areas is conducted in a vacuum without consideration for human engagement and the impact it could have when implemented.
Bozeman is lobbying for built-in tools and safeguards to mitigate the potential for harm from researchers using AI without appropriate consideration. He already sees a disconnect between the academic world and the public. Bridging that trust gap will require ethical uses of AI.
“We have to start rigorously including their voices in our decision-making to begin gaining trust with the public again. And with that trust, we can all start moving toward sustainable development. If we don't do that, I don't care how good our engineering solutions are, we're going to miss the boat entirely on bringing along the majority of the population.”
BBISS Support
Moving forward, Hester is excited about the impact the Brooks Byers Institute for Sustainable Systems can have on AI and sustainability research through a variety of support mechanisms.
“BBISS continues to invest in faculty development and training in community-driven research strategies, including the Community Engagement Faculty Fellows Program (with the Center for Sustainable Communities Research and Education), while empowering multidisciplinary teams to work together to solve grand engineering challenges with AI by supporting the AI+Climate Faculty Interest Group, as well as partnering with and providing administrative support for community-driven research projects.”
News Contact
Brent Verrill, Research Communications Program Manager, BBISS
Aug. 09, 2024



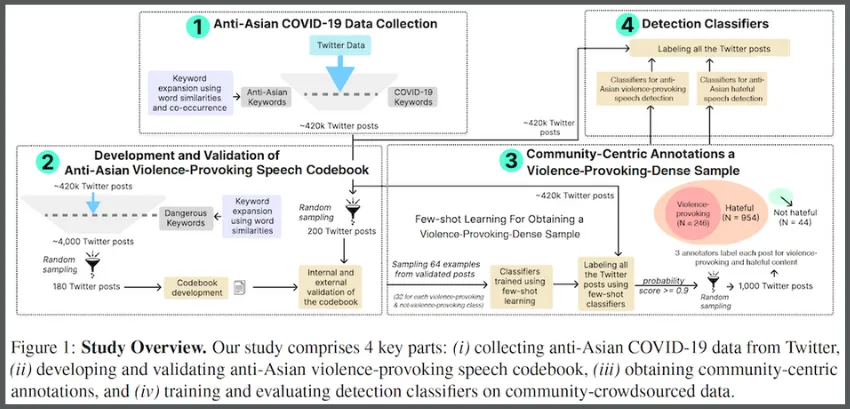
A research group is calling for internet and social media moderators to strengthen their detection and intervention protocols for violent speech.
Their study of language detection software found that algorithms struggle to differentiate anti-Asian violence-provoking speech from general hate speech. Left unchecked, threats of violence online can go unnoticed and turn into real-world attacks.
Researchers from Georgia Tech and the Anti-Defamation League (ADL) teamed together in the study. They made their discovery while testing natural language processing (NLP) models trained on data they crowdsourced from Asian communities.
“The Covid-19 pandemic brought attention to how dangerous violence-provoking speech can be. There was a clear increase in reports of anti-Asian violence and hate crimes,” said Gaurav Verma, a Georgia Tech Ph.D. candidate who led the study.
“Such speech is often amplified on social platforms, which in turn fuels anti-Asian sentiments and attacks.”
Violence-provoking speech differs from more commonly studied forms of harmful speech, like hate speech. While hate speech denigrates or insults a group, violence-provoking speech implicitly or explicitly encourages violence against targeted communities.
Humans can define and characterize violent speech as a subset of hateful speech. However, computer models struggle to tell the difference due to subtle cues and implications in language.
The researchers tested five different NLP classifiers and analyzed their F1 score, which measures a model's performance. The classifiers reported a 0.89 score for detecting hate speech, while detecting violence-provoking speech was only 0.69. This contrast highlights the notable gap between these tools and their accuracy and reliability.
The study stresses the importance of developing more refined methods for detecting violence-provoking speech. Internet misinformation and inflammatory rhetoric escalate tensions that lead to real-world violence.
The Covid-19 pandemic exemplified how public health crises intensify this behavior, helping inspire the study. The group cited that anti-Asian crime across the U.S. increased by 339% in 2021 due to malicious content blaming Asians for the virus.
The researchers believe their findings show the effectiveness of community-centric approaches to problems dealing with harmful speech. These approaches would enable informed decision-making between policymakers, targeted communities, and developers of online platforms.
Along with stronger models for detecting violence-provoking speech, the group discusses a direct solution: a tiered penalty system on online platforms. Tiered systems align penalties with severity of offenses, acting as both deterrent and intervention to different levels of harmful speech.
“We believe that we cannot tackle a problem that affects a community without involving people who are directly impacted,” said Jiawei Zhou, a Ph.D. student who studies human-centered computing at Georgia Tech.
“By collaborating with experts and community members, we ensure our research builds on front-line efforts to combat violence-provoking speech while remaining rooted in real experiences and needs of the targeted community.”
The researchers trained their tested NLP classifiers on a dataset crowdsourced from a survey of 120 participants who self-identified as Asian community members. In the survey, the participants labeled 1,000 posts from X (formerly Twitter) as containing either violence-provoking speech, hateful speech, or neither.
Since characterizing violence-provoking speech is not universal, the researchers created a specialized codebook for survey participants. The participants studied the codebook before their survey and used an abridged version while labeling.
To create the codebook, the group used an initial set of anti-Asian keywords to scan posts on X from January 2020 to February 2023. This tactic yielded 420,000 posts containing harmful, anti-Asian language.
The researchers then filtered the batch through new keywords and phrases. This refined the sample to 4,000 posts that potentially contained violence-provoking content. Keywords and phrases were added to the codebook while the filtered posts were used in the labeling survey.
The team used discussion and pilot testing to validate its codebook. During trial testing, pilots labeled 100 Twitter posts to ensure the sound design of the Asian community survey. The group also sent the codebook to the ADL for review and incorporated the organization’s feedback.
“One of the major challenges in studying violence-provoking content online is effective data collection and funneling down because most platforms actively moderate and remove overtly hateful and violent material,” said Tech alumnus Rynaa Grover (M.S. CS 2024).
“To address the complexities of this data, we developed an innovative pipeline that deals with the scale of this data in a community-aware manner.”
Emphasis on community input extended into collaboration within Georgia Tech’s College of Computing. Faculty members Srijan Kumar and Munmun De Choudhury oversaw the research that their students spearheaded.
Kumar, an assistant professor in the School of Computational Science and Engineering, advises Verma and Grover. His expertise is in artificial intelligence, data mining, and online safety.
De Choudhury is an associate professor in the School of Interactive Computing and advises Zhou. Their research connects societal mental health and social media interactions.
The Georgia Tech researchers partnered with the ADL, a leading non-governmental organization that combats real-world hate and extremism. ADL researchers Binny Mathew and Jordan Kraemer co-authored the paper.
The group will present its paper at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), which takes place in Bangkok, Thailand, Aug. 11-16
ACL 2024 accepted 40 papers written by Georgia Tech researchers. Of the 12 Georgia Tech faculty who authored papers accepted at the conference, nine are from the College of Computing, including Kumar and De Choudhury.
“It is great to see that the peers and research community recognize the importance of community-centric work that provides grounded insights about the capabilities of leading language models,” Verma said.
“We hope the platform encourages more work that presents community-centered perspectives on important societal problems.”
Visit https://sites.gatech.edu/research/acl-2024/ for news and coverage of Georgia Tech research presented at ACL 2024.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Jul. 11, 2024


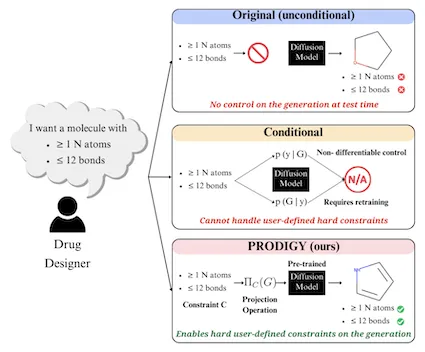
New research from Georgia Tech is giving scientists more control options over generative artificial intelligence (AI) models in their studies. Greater customization from this research can lead to discovery of new drugs, materials, and other applications tailor-made for consumers.
The Tech group dubbed its method PRODIGY (PROjected DIffusion for controlled Graph Generation). PRODIGY enables diffusion models to generate 3D images of complex structures, such as molecules from chemical formulas.
Scientists in pharmacology, materials science, social network analysis, and other fields can use PRODIGY to simulate large-scale networks. By generating 3D molecules from multiple graph datasets, the group proved that PRODIGY could handle complex structures.
In keeping with its name, PRODIGY is the first plug-and-play machine learning (ML) approach to controllable graph generation in diffusion models. This method overcomes a known limitation inhibiting diffusion models from broad use in science and engineering.
“We hope PRODIGY enables drug designers and scientists to generate structures that meet their precise needs,” said Kartik Sharma, lead researcher on the project. “It should also inspire future innovations to precisely control modern generative models across domains.”
PRODIGY works on diffusion models, a generative AI model for computer vision tasks. While suitable for image creation and denoising, diffusion methods are limited because they cannot accurately generate graph representations of custom parameters a user provides.
PRODIGY empowers any pre-trained diffusion model for graph generation to produce graphs that meet specific, user-given constraints. This capability means, as an example, that a drug designer could use any diffusion model to design a molecule with a specific number of atoms and bonds.
The group tested PRODIGY on two molecular and five generic datasets to generate custom 2D and 3D structures. This approach ensured the method could create such complex structures, accounting for the atoms, bonds, structures, and other properties at play in molecules.
Molecular generation experiments with PRODIGY directly impact chemistry, biology, pharmacology, materials science, and other fields. The researchers say PRODIGY has potential in other fields using large networks and datasets, such as social sciences and telecommunications.
These features led to PRODIGY’s acceptance for presentation at the upcoming International Conference on Machine Learning (ICML 2024). ICML 2024 is the leading international academic conference on ML. The conference is taking place July 21-27 in Vienna.
Assistant Professor Srijan Kumar is Sharma’s advisor and paper co-author. They worked with Tech alumnus Rakshit Trivedi (Ph.D. CS 2020), a Massachusetts Institute of Technology postdoctoral associate.
Twenty-four Georgia Tech faculty from the Colleges of Computing and Engineering will present 40 papers at ICML 2024. Kumar is one of six faculty representing the School of Computational Science and Engineering (CSE) at the conference.
Sharma is a fourth-year Ph.D. student studying computer science. He researches ML models for structured data that are reliable and easily controlled by users. While preparing for ICML, Sharma has been interning this summer at Microsoft Research in the Research for Industry lab.
“ICML is the pioneering conference for machine learning,” said Kumar. “A strong presence at ICML from Georgia Tech illustrates the ground-breaking research conducted by our students and faculty, including those in my research group.”
Visit https://sites.gatech.edu/research/icml-2024 for news and coverage of Georgia Tech research presented at ICML 2024.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu