Sep. 19, 2024



A new algorithm tested on NASA’s Perseverance Rover on Mars may lead to better forecasting of hurricanes, wildfires, and other extreme weather events that impact millions globally.
Georgia Tech Ph.D. student Austin P. Wright is first author of a paper that introduces Nested Fusion. The new algorithm improves scientists’ ability to search for past signs of life on the Martian surface.
In addition to supporting NASA’s Mars 2020 mission, scientists from other fields working with large, overlapping datasets can use Nested Fusion’s methods toward their studies.
Wright presented Nested Fusion at the 2024 International Conference on Knowledge Discovery and Data Mining (KDD 2024) where it was a runner-up for the best paper award. KDD is widely considered the world's most prestigious conference for knowledge discovery and data mining research.
“Nested Fusion is really useful for researchers in many different domains, not just NASA scientists,” said Wright. “The method visualizes complex datasets that can be difficult to get an overall view of during the initial exploratory stages of analysis.”
Nested Fusion combines datasets with different resolutions to produce a single, high-resolution visual distribution. Using this method, NASA scientists can more easily analyze multiple datasets from various sources at the same time. This can lead to faster studies of Mars’ surface composition to find clues of previous life.
The algorithm demonstrates how data science impacts traditional scientific fields like chemistry, biology, and geology.
Even further, Wright is developing Nested Fusion applications to model shifting climate patterns, plant and animal life, and other concepts in the earth sciences. The same method can combine overlapping datasets from satellite imagery, biomarkers, and climate data.
“Users have extended Nested Fusion and similar algorithms toward earth science contexts, which we have received very positive feedback,” said Wright, who studies machine learning (ML) at Georgia Tech.
“Cross-correlational analysis takes a long time to do and is not done in the initial stages of research when patterns appear and form new hypotheses. Nested Fusion enables people to discover these patterns much earlier.”
Wright is the data science and ML lead for PIXLISE, the software that NASA JPL scientists use to study data from the Mars Perseverance Rover.
Perseverance uses its Planetary Instrument for X-ray Lithochemistry (PIXL) to collect data on mineral composition of Mars’ surface. PIXL’s two main tools that accomplish this are its X-ray Fluorescence (XRF) Spectrometer and Multi-Context Camera (MCC).
When PIXL scans a target area, it creates two co-aligned datasets from the components. XRF collects a sample's fine-scale elemental composition. MCC produces images of a sample to gather visual and physical details like size and shape.
A single XRF spectrum corresponds to approximately 100 MCC imaging pixels for every scan point. Each tool’s unique resolution makes mapping between overlapping data layers challenging. However, Wright and his collaborators designed Nested Fusion to overcome this hurdle.
In addition to progressing data science, Nested Fusion improves NASA scientists' workflow. Using the method, a single scientist can form an initial estimate of a sample’s mineral composition in a matter of hours. Before Nested Fusion, the same task required days of collaboration between teams of experts on each different instrument.
“I think one of the biggest lessons I have taken from this work is that it is valuable to always ground my ML and data science problems in actual, concrete use cases of our collaborators,” Wright said.
“I learn from collaborators what parts of data analysis are important to them and the challenges they face. By understanding these issues, we can discover new ways of formalizing and framing problems in data science.”
Wright presented Nested Fusion at KDD 2024, held Aug. 25-29 in Barcelona, Spain. KDD is an official special interest group of the Association for Computing Machinery. The conference is one of the world’s leading forums for knowledge discovery and data mining research.
Nested Fusion won runner-up for the best paper in the applied data science track, which comprised of over 150 papers. Hundreds of other papers were presented at the conference’s research track, workshops, and tutorials.
Wright’s mentors, Scott Davidoff and Polo Chau, co-authored the Nested Fusion paper. Davidoff is a principal research scientist at the NASA Jet Propulsion Laboratory. Chau is a professor at the Georgia Tech School of Computational Science and Engineering (CSE).
“I was extremely happy that this work was recognized with the best paper runner-up award,” Wright said. “This kind of applied work can sometimes be hard to find the right academic home, so finding communities that appreciate this work is very encouraging.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Aug. 28, 2024

The National Science Foundation has awarded $2 million to Clark Atlanta University in partnership with the HBCU CHIPS Network, a collaborative effort involving historically black colleges and universities (HBCUs), government agencies, academia, and industry that will serve as a national resource for semiconductor research and education.
“This is an exciting time for the HBCU CHIPS Network,” said George White, senior director for Strategic Partnerships at Georgia Tech. “This funding, and the support of Georgia Tech Executive Vice President for Research Chaouki Abdallah, is integral for the successful launch of the CHIPS Network.”
The HBCU Chips Network works to cultivate a diverse and skilled workforce that supports the national semiconductor industry. The student research and internship opportunities along with the development of specialized curricula in semiconductor design, fabrication, and related fields will expand the microelectronics workforce. As part of the network, Georgia Tech will optimize the packaging of chips into systems.
News Contact
Georgia Tech Contact:
Amelia Neumeister | Research Communications Program Manager
Clark Atlanta University Contact:
Frances Williams
Aug. 21, 2024

Montage of five portraits, L to R, T to B: Josiah Hester, Peng Chen, Yongsheng Chen, Rosemarie Santa González, and Joe Bozeman.
- Written by Benjamin Wright -
As Georgia Tech establishes itself as a national leader in AI research and education, some researchers on campus are putting AI to work to help meet sustainability goals in a range of areas including climate change adaptation and mitigation, urban farming, food distribution, and life cycle assessments while also focusing on ways to make sure AI is used ethically.
Josiah Hester, interim associate director for Community-Engaged Research in the Brook Byers Institute for Sustainable Systems (BBISS) and associate professor in the School of Interactive Computing, sees these projects as wins from both a research standpoint and for the local, national, and global communities they could affect.
“These faculty exemplify Georgia Tech's commitment to serving and partnering with communities in our research,” he says. “Sustainability is one of the most pressing issues of our time. AI gives us new tools to build more resilient communities, but the complexities and nuances in applying this emerging suite of technologies can only be solved by community members and researchers working closely together to bridge the gap. This approach to AI for sustainability strengthens the bonds between our university and our communities and makes lasting impacts due to community buy-in.”
Flood Monitoring and Carbon Storage
Peng Chen, assistant professor in the School of Computational Science and Engineering in the College of Computing, focuses on computational mathematics, data science, scientific machine learning, and parallel computing. Chen is combining these areas of expertise to develop algorithms to assist in practical applications such as flood monitoring and carbon dioxide capture and storage.
He is currently working on a National Science Foundation (NSF) project with colleagues in Georgia Tech’s School of City and Regional Planning and from the University of South Florida to develop flood models in the St. Petersburg, Florida area. As a low-lying state with more than 8,400 miles of coastline, Florida is one of the states most at risk from sea level rise and flooding caused by extreme weather events sparked by climate change.
Chen’s novel approach to flood monitoring takes existing high-resolution hydrological and hydrographical mapping and uses machine learning to incorporate real-time updates from social media users and existing traffic cameras to run rapid, low-cost simulations using deep neural networks. Current flood monitoring software is resource and time-intensive. Chen’s goal is to produce live modeling that can be used to warn residents and allocate emergency response resources as conditions change. That information would be available to the general public through a portal his team is working on.
“This project focuses on one particular community in Florida,” Chen says, “but we hope this methodology will be transferable to other locations and situations affected by climate change.”
In addition to the flood-monitoring project in Florida, Chen and his colleagues are developing new methods to improve the reliability and cost-effectiveness of storing carbon dioxide in underground rock formations. The process is plagued with uncertainty about the porosity of the bedrock, the optimal distribution of monitoring wells, and the rate at which carbon dioxide can be injected without over-pressurizing the bedrock, leading to collapse. The new simulations are fast, inexpensive, and minimize the risk of failure, which also decreases the cost of construction.
“Traditional high-fidelity simulation using supercomputers takes hours and lots of resources,” says Chen. “Now we can run these simulations in under one minute using AI models without sacrificing accuracy. Even when you factor in AI training costs, this is a huge savings in time and financial resources.”
Flood monitoring and carbon capture are passion projects for Chen, who sees an opportunity to use artificial intelligence to increase the pace and decrease the cost of problem-solving.
“I’m very excited about the possibility of solving grand challenges in the sustainability area with AI and machine learning models,” he says. “Engineering problems are full of uncertainty, but by using this technology, we can characterize the uncertainty in new ways and propagate it throughout our predictions to optimize designs and maximize performance.”
Urban Farming and Optimization
Yongsheng Chen works at the intersection of food, energy, and water. As the Bonnie W. and Charles W. Moorman Professor in the School of Civil and Environmental Engineering and director of the Nutrients, Energy, and Water Center for Agriculture Technology, Chen is focused on making urban agriculture technologically feasible, financially viable, and, most importantly, sustainable. To do that he’s leveraging AI to speed up the design process and optimize farming and harvesting operations.
Chen’s closed-loop hydroponic system uses anaerobically treated wastewater for fertilization and irrigation by extracting and repurposing nutrients as fertilizer before filtering the water through polymeric membranes with nano-scale pores. Advancing filtration and purification processes depends on finding the right membrane materials to selectively separate contaminants, including antibiotics and per- and polyfluoroalkyl substances (PFAS). Chen and his team are using AI and machine learning to guide membrane material selection and fabrication to make contaminant separation as efficient as possible. Similarly, AI and machine learning are assisting in developing carbon capture materials such as ionic liquids that can retain carbon dioxide generated during wastewater treatment and redirect it to hydroponics systems, boosting food productivity.
“A fundamental angle of our research is that we do not see municipal wastewater as waste,” explains Chen. “It is a resource we can treat and recover components from to supply irrigation, fertilizer, and biogas, all while reducing the amount of energy used in conventional wastewater treatment methods.”
In addition to aiding in materials development, which reduces design time and production costs, Chen is using machine learning to optimize the growing cycle of produce, maximizing nutritional value. His USDA-funded vertical farm uses autonomous robots to measure critical cultivation parameters and take pictures without destroying plants. This data helps determine optimum environmental conditions, fertilizer supply, and harvest timing, resulting in a faster-growing, optimally nutritious plant with less fertilizer waste and lower emissions.
Chen’s work has received considerable federal funding. As the Urban Resilience and Sustainability Thrust Leader within the NSF-funded AI Institute for Advances in Optimization (AI4OPT), he has received additional funding to foster international collaboration in digital agriculture with colleagues across the United States and in Japan, Australia, and India.
Optimizing Food Distribution
At the other end of the agricultural spectrum is postdoc Rosemarie Santa González in the H. Milton Stewart School of Industrial and Systems Engineering, who is conducting her research under the supervision of Professor Chelsea White and Professor Pascal Van Hentenryck, the director of Georgia Tech’s AI Hub as well as the director of AI4OPT.
Santa González is working with the Wisconsin Food Hub Cooperative to help traditional farmers get their products into the hands of consumers as efficiently as possible to reduce hunger and food waste. Preventing food waste is a priority for both the EPA and USDA. Current estimates are that 30 to 40% of the food produced in the United States ends up in landfills, which is a waste of resources on both the production end in the form of land, water, and chemical use, as well as a waste of resources when it comes to disposing of it, not to mention the impact of the greenhouses gases when wasted food decays.
To tackle this problem, Santa González and the Wisconsin Food Hub are helping small-scale farmers access refrigeration facilities and distribution chains. As part of her research, she is helping to develop AI tools that can optimize the logistics of the small-scale farmer supply chain while also making local consumers in underserved areas aware of what’s available so food doesn’t end up in landfills.
“This solution has to be accessible,” she says. “Not just in the sense that the food is accessible, but that the tools we are providing to them are accessible. The end users have to understand the tools and be able to use them. It has to be sustainable as a resource.”
Making AI accessible to people in the community is a core goal of the NSF’s AI Institute for Intelligent Cyberinfrastructure with Computational Learning in the Environment (ICICLE), one of the partners involved with the project.
“A large segment of the population we are working with, which includes historically marginalized communities, has a negative reaction to AI. They think of machines taking over, or data being stolen. Our goal is to democratize AI in these decision-support tools as we work toward the UN Sustainable Development Goal of Zero Hunger. There is so much power in these tools to solve complex problems that have very real results. More people will be fed and less food will spoil before it gets to people’s homes.”
Santa González hopes the tools they are building can be packaged and customized for food co-ops everywhere.
AI and Ethics
Like Santa González, Joe Bozeman III is also focused on the ethical and sustainable deployment of AI and machine learning, especially among marginalized communities. The assistant professor in the School of Civil and Environmental Engineering is an industrial ecologist committed to fostering ethical climate change adaptation and mitigation strategies. His SEEEL Lab works to make sure researchers understand the consequences of decisions before they move from academic concepts to policy decisions, particularly those that rely on data sets involving people and communities.
“With the administration of big data, there is a human tendency to assume that more data means everything is being captured, but that's not necessarily true,” he cautions. “More data could mean we're just capturing more of the data that already exists, while new research shows that we’re not including information from marginalized communities that have historically not been brought into the decision-making process. That includes underrepresented minorities, rural populations, people with disabilities, and neurodivergent people who may not interface with data collection tools.”
Bozeman is concerned that overlooking marginalized communities in data sets will result in decisions that at best ignore them and at worst cause them direct harm.
“Our lab doesn't wait for the negative harms to occur before we start talking about them,” explains Bozeman, who holds a courtesy appointment in the School of Public Policy. “Our lab forecasts what those harms will be so decision-makers and engineers can develop technologies that consider these things.”
He focuses on urbanization, the food-energy-water nexus, and the circular economy. He has found that much of the research in those areas is conducted in a vacuum without consideration for human engagement and the impact it could have when implemented.
Bozeman is lobbying for built-in tools and safeguards to mitigate the potential for harm from researchers using AI without appropriate consideration. He already sees a disconnect between the academic world and the public. Bridging that trust gap will require ethical uses of AI.
“We have to start rigorously including their voices in our decision-making to begin gaining trust with the public again. And with that trust, we can all start moving toward sustainable development. If we don't do that, I don't care how good our engineering solutions are, we're going to miss the boat entirely on bringing along the majority of the population.”
BBISS Support
Moving forward, Hester is excited about the impact the Brooks Byers Institute for Sustainable Systems can have on AI and sustainability research through a variety of support mechanisms.
“BBISS continues to invest in faculty development and training in community-driven research strategies, including the Community Engagement Faculty Fellows Program (with the Center for Sustainable Communities Research and Education), while empowering multidisciplinary teams to work together to solve grand engineering challenges with AI by supporting the AI+Climate Faculty Interest Group, as well as partnering with and providing administrative support for community-driven research projects.”
News Contact
Brent Verrill, Research Communications Program Manager, BBISS
Aug. 20, 2024

For three days, a cybercriminal unleashed a crippling ransomware attack on the futuristic city of Northbridge. The attack shut down the city’s infrastructure and severely impacted public services, until Georgia Tech cybersecurity experts stepped in to stop it.
This scenario played out this weekend at the DARPA AI Cyber Challenge (AIxCC) semi-final competition held at DEF CON 32 in Las Vegas. Team Atlanta, which included the Georgia Tech experts, were among the contest’s winners.
Team Atlanta will now compete against six other teams in the final round that takes place at DEF CON 33 in August 2025. The finalists will keep their AI system and improve it over the next 12 months using the $2 million semi-final prize.
The AI systems in the finals must be open sourced and ready for immediate, real-world launch. The AIxCC final competition will award a $4 million grand prize to the ultimate champion.
Team Atlanta is made up of past and present Georgia Tech students and was put together with the help of SCP Professor Taesoo Kim. Not only did the team secure a spot in the final competition, they found a zero-day vulnerability in the contest.
“I am incredibly proud to announce that Team Atlanta has qualified for the finals in the DARPA AIxCC competition,” said Taesoo Kim, professor in the School of Cybersecurity and Privacy and a vice president of Samsung Research.
“This achievement is the result of exceptional collaboration across various organizations, including the Georgia Tech Research Institute (GTRI), industry partners like Samsung, and international academic institutions such as KAIST and POSTECH.”
After noticing discrepancies in the competition score board, the team discovered and reported a bug in the competition itself. The type of vulnerability they discovered is known as a zero-day vulnerability, because vendors have zero days to fix the issue.
While this didn’t earn Team Atlanta additional points, the competition organizer acknowledged the team and their finding during the closing ceremony.
“Our team, deeply rooted in Atlanta and largely composed of Georgia Tech alumni, embodies the innovative spirit and community values that define our city,” said Kim.
“With over 30 dedicated students and researchers, we have demonstrated the power of cross-disciplinary teamwork in the semi-final event. As we advance to the finals, we are committed to pushing the boundaries of cybersecurity and artificial intelligence, and I firmly believe the resulting systems from this competition will transform the security landscape in the coming year!”
The team tested their cyber reasoning system (CRS), dubbed Atlantis, on software used for data management, website support, healthcare systems, supply chains, electrical grids, transportation, and other critical infrastructures.
Atlantis is a next-generation, bug-finding and fixing system that can hunt bugs in multiple coding languages. The system immediately issues accurate software patches without any human intervention.
AIxCC is a Pentagon-backed initiative that was announced in August 2023 and will award up to $20 million in prize money throughout the competition. Team Atlanta was among the 42 teams that qualified for the semi-final competition earlier this year.
News Contact
John Popham
Communications Officer II at the School of Cybersecurity and Privacy
Aug. 09, 2024



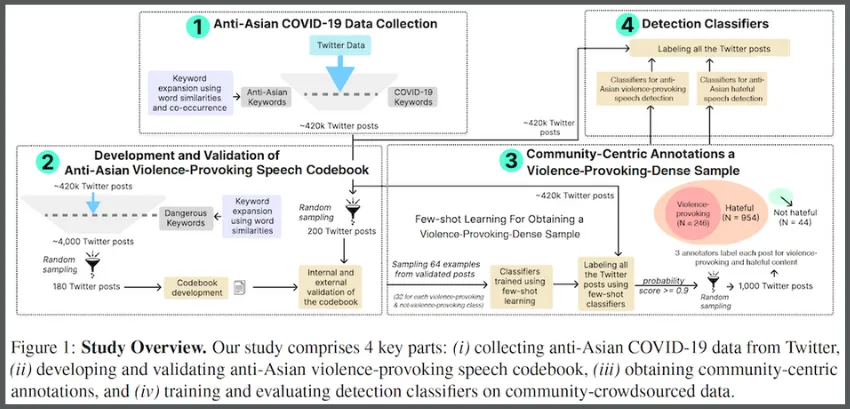
A research group is calling for internet and social media moderators to strengthen their detection and intervention protocols for violent speech.
Their study of language detection software found that algorithms struggle to differentiate anti-Asian violence-provoking speech from general hate speech. Left unchecked, threats of violence online can go unnoticed and turn into real-world attacks.
Researchers from Georgia Tech and the Anti-Defamation League (ADL) teamed together in the study. They made their discovery while testing natural language processing (NLP) models trained on data they crowdsourced from Asian communities.
“The Covid-19 pandemic brought attention to how dangerous violence-provoking speech can be. There was a clear increase in reports of anti-Asian violence and hate crimes,” said Gaurav Verma, a Georgia Tech Ph.D. candidate who led the study.
“Such speech is often amplified on social platforms, which in turn fuels anti-Asian sentiments and attacks.”
Violence-provoking speech differs from more commonly studied forms of harmful speech, like hate speech. While hate speech denigrates or insults a group, violence-provoking speech implicitly or explicitly encourages violence against targeted communities.
Humans can define and characterize violent speech as a subset of hateful speech. However, computer models struggle to tell the difference due to subtle cues and implications in language.
The researchers tested five different NLP classifiers and analyzed their F1 score, which measures a model's performance. The classifiers reported a 0.89 score for detecting hate speech, while detecting violence-provoking speech was only 0.69. This contrast highlights the notable gap between these tools and their accuracy and reliability.
The study stresses the importance of developing more refined methods for detecting violence-provoking speech. Internet misinformation and inflammatory rhetoric escalate tensions that lead to real-world violence.
The Covid-19 pandemic exemplified how public health crises intensify this behavior, helping inspire the study. The group cited that anti-Asian crime across the U.S. increased by 339% in 2021 due to malicious content blaming Asians for the virus.
The researchers believe their findings show the effectiveness of community-centric approaches to problems dealing with harmful speech. These approaches would enable informed decision-making between policymakers, targeted communities, and developers of online platforms.
Along with stronger models for detecting violence-provoking speech, the group discusses a direct solution: a tiered penalty system on online platforms. Tiered systems align penalties with severity of offenses, acting as both deterrent and intervention to different levels of harmful speech.
“We believe that we cannot tackle a problem that affects a community without involving people who are directly impacted,” said Jiawei Zhou, a Ph.D. student who studies human-centered computing at Georgia Tech.
“By collaborating with experts and community members, we ensure our research builds on front-line efforts to combat violence-provoking speech while remaining rooted in real experiences and needs of the targeted community.”
The researchers trained their tested NLP classifiers on a dataset crowdsourced from a survey of 120 participants who self-identified as Asian community members. In the survey, the participants labeled 1,000 posts from X (formerly Twitter) as containing either violence-provoking speech, hateful speech, or neither.
Since characterizing violence-provoking speech is not universal, the researchers created a specialized codebook for survey participants. The participants studied the codebook before their survey and used an abridged version while labeling.
To create the codebook, the group used an initial set of anti-Asian keywords to scan posts on X from January 2020 to February 2023. This tactic yielded 420,000 posts containing harmful, anti-Asian language.
The researchers then filtered the batch through new keywords and phrases. This refined the sample to 4,000 posts that potentially contained violence-provoking content. Keywords and phrases were added to the codebook while the filtered posts were used in the labeling survey.
The team used discussion and pilot testing to validate its codebook. During trial testing, pilots labeled 100 Twitter posts to ensure the sound design of the Asian community survey. The group also sent the codebook to the ADL for review and incorporated the organization’s feedback.
“One of the major challenges in studying violence-provoking content online is effective data collection and funneling down because most platforms actively moderate and remove overtly hateful and violent material,” said Tech alumnus Rynaa Grover (M.S. CS 2024).
“To address the complexities of this data, we developed an innovative pipeline that deals with the scale of this data in a community-aware manner.”
Emphasis on community input extended into collaboration within Georgia Tech’s College of Computing. Faculty members Srijan Kumar and Munmun De Choudhury oversaw the research that their students spearheaded.
Kumar, an assistant professor in the School of Computational Science and Engineering, advises Verma and Grover. His expertise is in artificial intelligence, data mining, and online safety.
De Choudhury is an associate professor in the School of Interactive Computing and advises Zhou. Their research connects societal mental health and social media interactions.
The Georgia Tech researchers partnered with the ADL, a leading non-governmental organization that combats real-world hate and extremism. ADL researchers Binny Mathew and Jordan Kraemer co-authored the paper.
The group will present its paper at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), which takes place in Bangkok, Thailand, Aug. 11-16
ACL 2024 accepted 40 papers written by Georgia Tech researchers. Of the 12 Georgia Tech faculty who authored papers accepted at the conference, nine are from the College of Computing, including Kumar and De Choudhury.
“It is great to see that the peers and research community recognize the importance of community-centric work that provides grounded insights about the capabilities of leading language models,” Verma said.
“We hope the platform encourages more work that presents community-centered perspectives on important societal problems.”
Visit https://sites.gatech.edu/research/acl-2024/ for news and coverage of Georgia Tech research presented at ACL 2024.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Aug. 08, 2024

Social media users may need to think twice before hitting that “Post” button.
A new large-language model (LLM) developed by Georgia Tech researchers can help them filter content that could risk their privacy and offer alternative phrasing that keeps the context of their posts intact.
According to a new paper that will be presented at the 2024 Association for Computing Linguistics(ACL) conference, social media users should tread carefully about the information they self-disclose in their posts.
Many people use social media to express their feelings about their experiences without realizing the risks to their privacy. For example, a person revealing their gender identity or sexual orientation may be subject to doxing and harassment from outside parties.
Others want to express their opinions without their employers or families knowing.
Ph.D. student Yao Dou and associate professors Alan Ritter and Wei Xu originally set out to study user awareness of self-disclosure privacy risks on Reddit. Working with anonymous users, they created an LLM to detect at-risk content.
While the study boosted user awareness of the personal information they revealed, many called for an intervention. They asked the researchers for assistance to rewrite their posts so they didn’t have to be concerned about privacy.
The researchers revamped the model to suggest alternative phrases that reduce the risk of privacy invasion.
One user disclosed, “I’m 16F I think I want to be a bi M.” The new tool offered alternative phrases such as:
- “I am exploring my sexual identity.”
- “I have a desire to explore new options.”
- “I am attracted to the idea of exploring different gender identities.”
Dou said the challenge is making sure the model provides suggestions that don’t change or distort the desired context of the post.
“That’s why instead of providing one suggestion, we provide three suggestions that are different from each other, and we allow the user to choose which one they want,” Dou said. “In some cases, the discourse information is important to the post, and in that case, they can choose what to abstract.”
WEIGHING THE RISKS
The researchers sampled 10,000 Reddit posts from a pool of 4 million that met their search criteria. They annotated those posts and created 19 categories of self-disclosures, including age, sexual orientation, gender, race or nationality, and location.
From there, they worked with Reddit users to test the effectiveness and accuracy of their model, with 82% giving positive feedback.
However, a contingent thought the model was “oversensitive,” highlighting content they did not believe posed a risk.
Ultimately, the researchers say users must decide what they will post.
“It’s a personal decision,” Ritter said. “People need to look at this and think about what they’re writing and decide between this tradeoff of what benefits they are getting from sharing information versus what privacy risks are associated with that.”
Xu acknowledged that future work on the project should include a metric that gives users a better idea of what types of content are more at risk than others.
“It’s kind of the way passwords work,” she said. “Years ago, they never told you your password strength, and now there’s a bar telling you how good your password is. Then you realize you need to add a special character and capitalize some letters, and that’s become a standard. This is telling the public how they can protect themselves. The risk isn’t zero, but it helps them think about it.”
WHAT ARE THE CONSEQUENCES?
While doxing and harassment are the most likely consequences of posting sensitive personal information, especially for those who belong to minority groups, the researchers say users have other privacy concerns.
Users should know that when they draft posts on a site, their input can be extracted by the site’s application programming interface (API). If that site has a data breach, a user’s personal information could fall into unwanted hands.
“I think we should have a path toward having everything work locally on the user’s computer, so it doesn’t rely on any external APIs to send this data off their local machine,” Ritter said.
Ritter added that users could also be targets of popular scams like phishing without ever knowing it.
“People trying targeted phishing attacks can learn personal information about people online that might help them craft more customized attacks that could make users vulnerable,” he said.
The safest way to avoid a breach of privacy is to stay off social media. But Xu said that’s impractical as there are resources and support these sites can provide that users may not get from anywhere else.
“We want people who may be afraid of social media to use it and feel safe when they post,” she said. “Maybe the best way to get an answer to a question is to ask online, but some people don’t feel comfortable doing that, so a tool like this can make them more comfortable sharing without much risk.”
For more information about Georgia Tech research at ACL, please visit https://sites.gatech.edu/research/acl-2024/.
News Contact
Nathan Deen
Communications Officer
School of Interactive Computing
Aug. 01, 2024

A Georgia Tech researcher will continue to mitigate harmful post-deployment effects created by artificial intelligence (AI) as he joins the 2024-2025 cohort of fellows selected by the Berkman-Klein Center (BKC) for Internet and Society at Harvard University.
Upol Ehsan is the first Georgia Tech graduate selected by BKC. As a fellow, he will contribute to its mission of exploring and understanding cyberspace, focusing on AI, social media, and university discourse.
Entering its 25th year, the BKC Harvard fellowship program addresses pressing issues and produces impactful research that influences academia and public policy. It offers a global perspective, a vibrant intellectual community, and significant funding and resources that attract top scholars and leaders.
The program is highly competitive and sought after by early career candidates and veteran academic and industry professionals. Cohorts hail from numerous backgrounds, including law, computer science, sociology, political science, neuroscience, philosophy, and media studies.
“Having the opportunity to join such a talented group of people and working with them is a treat,” Ehsan said. “I’m looking forward to adding to the prismatic network of BKC Harvard and learning from the cohesively diverse community.”
While at Georgia Tech, Ehsan expanded the field of explainable AI (XAI) and pioneered a subcategory he labeled human-centered explainable AI (HCXAI). Several of his papers introduced novel and foundational concepts into that subcategory of XAI.
Ehsan works with Professor Mark Riedl in the School of Interactive Computing and the Human-centered AI and Entertainment Intelligence Lab.
Ehsan says he will continue to work on research he introduced in his 2022 paper The Algorithmic Imprint, which shows how the potential harm from algorithms can linger even after an algorithm is no longer used. His research has informed the United Nations’ algorithmic reparations policies and has been incorporated into the National Institute of Standards and Technology AI Risk Management Framework.
“It’s a massive honor to receive this recognition of my work,” Ehsan said. “The Algorithmic Imprint remains a globally applicable Responsible AI concept developed entirely from the Global South. This recognition is dedicated to the participants who made this work possible. I want to take their stories even further."
While at BKC Harvard, Ehsan will develop a taxonomy of potentially harmful AI effects after a model is no longer used. He will also design a process to anticipate these effects and create interventions. He said his work addresses an “accountability blindspot” in responsible AI, which tends to focus on potential harmful effects created during AI deployment.
News Contact
Nathan Deen
Communications Officer
School of Interactive Computing
Jul. 11, 2024


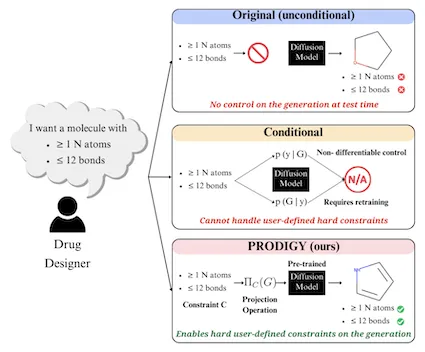
New research from Georgia Tech is giving scientists more control options over generative artificial intelligence (AI) models in their studies. Greater customization from this research can lead to discovery of new drugs, materials, and other applications tailor-made for consumers.
The Tech group dubbed its method PRODIGY (PROjected DIffusion for controlled Graph Generation). PRODIGY enables diffusion models to generate 3D images of complex structures, such as molecules from chemical formulas.
Scientists in pharmacology, materials science, social network analysis, and other fields can use PRODIGY to simulate large-scale networks. By generating 3D molecules from multiple graph datasets, the group proved that PRODIGY could handle complex structures.
In keeping with its name, PRODIGY is the first plug-and-play machine learning (ML) approach to controllable graph generation in diffusion models. This method overcomes a known limitation inhibiting diffusion models from broad use in science and engineering.
“We hope PRODIGY enables drug designers and scientists to generate structures that meet their precise needs,” said Kartik Sharma, lead researcher on the project. “It should also inspire future innovations to precisely control modern generative models across domains.”
PRODIGY works on diffusion models, a generative AI model for computer vision tasks. While suitable for image creation and denoising, diffusion methods are limited because they cannot accurately generate graph representations of custom parameters a user provides.
PRODIGY empowers any pre-trained diffusion model for graph generation to produce graphs that meet specific, user-given constraints. This capability means, as an example, that a drug designer could use any diffusion model to design a molecule with a specific number of atoms and bonds.
The group tested PRODIGY on two molecular and five generic datasets to generate custom 2D and 3D structures. This approach ensured the method could create such complex structures, accounting for the atoms, bonds, structures, and other properties at play in molecules.
Molecular generation experiments with PRODIGY directly impact chemistry, biology, pharmacology, materials science, and other fields. The researchers say PRODIGY has potential in other fields using large networks and datasets, such as social sciences and telecommunications.
These features led to PRODIGY’s acceptance for presentation at the upcoming International Conference on Machine Learning (ICML 2024). ICML 2024 is the leading international academic conference on ML. The conference is taking place July 21-27 in Vienna.
Assistant Professor Srijan Kumar is Sharma’s advisor and paper co-author. They worked with Tech alumnus Rakshit Trivedi (Ph.D. CS 2020), a Massachusetts Institute of Technology postdoctoral associate.
Twenty-four Georgia Tech faculty from the Colleges of Computing and Engineering will present 40 papers at ICML 2024. Kumar is one of six faculty representing the School of Computational Science and Engineering (CSE) at the conference.
Sharma is a fourth-year Ph.D. student studying computer science. He researches ML models for structured data that are reliable and easily controlled by users. While preparing for ICML, Sharma has been interning this summer at Microsoft Research in the Research for Industry lab.
“ICML is the pioneering conference for machine learning,” said Kumar. “A strong presence at ICML from Georgia Tech illustrates the ground-breaking research conducted by our students and faculty, including those in my research group.”
Visit https://sites.gatech.edu/research/icml-2024 for news and coverage of Georgia Tech research presented at ICML 2024.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Jul. 11, 2024


A new machine learning (ML) model created at Georgia Tech is helping neuroscientists better understand communications between brain regions. Insights from the model could lead to personalized medicine, better brain-computer interfaces, and advances in neurotechnology.
The Georgia Tech group combined two current ML methods into their hybrid model called MRM-GP (Multi-Region Markovian Gaussian Process).
Neuroscientists who use MRM-GP learn more about communications and interactions within the brain. This in turn improves understanding of brain functions and disorders.
“Clinically, MRM-GP could enhance diagnostic tools and treatment monitoring by identifying and analyzing neural activity patterns linked to various brain disorders,” said Weihan Li, the study’s lead researcher.
“Neuroscientists can leverage MRM-GP for its robust modeling capabilities and efficiency in handling large-scale brain data.”
MRM-GP reveals where and how communication travels across brain regions.
The group tested MRM-GP using spike trains and local field potential recordings, two kinds of measurements of brain activity. These tests produced representations that illustrated directional flow of communication among brain regions.
Experiments also disentangled brainwaves, called oscillatory interactions, into organized frequency bands. MRM-GP’s hybrid configuration allows it to model frequencies and phase delays within the latent space of neural recordings.
MRM-GP combines the strengths of two existing methods: the Gaussian process (GP) and linear dynamical systems (LDS). The researchers say that MRM-GP is essentially an LDS that mirrors a GP.
LDS is a computationally efficient and cost-effective method, but it lacks the power to produce representations of the brain. GP-based approaches boost LDS's power, facilitating the discovery of variables in frequency bands and communication directions in the brain.
Converting GP outputs into an LDS is a difficult task in ML. The group overcame this challenge by instilling separability in the model’s multi-region kernel. Separability establishes a connection between the kernel and LDS while modeling communication between brain regions.
Through this approach, MRM-GP overcomes two challenges facing both neuroscience and ML fields. The model helps solve the mystery of intraregional brain communication. It does so by bridging a gap between GP and LDS, a feat not previously accomplished in ML.
“The introduction of MRM-GP provides a useful tool to model and understand complex brain region communications,” said Li, a Ph.D. student in the School of Computational Science and Engineering (CSE).
“This marks a significant advancement in both neuroscience and machine learning.”
Fellow doctoral students Chengrui Li and Yule Wang co-authored the paper with Li. School of CSE Assistant Professor Anqi Wu advises the group.
Each MRM-GP student pursues a different Ph.D. degree offered by the School of CSE. W. Li studies computer science, C. Li studies computational science and engineering, and Wang studies machine learning. The school also offers Ph.D. degrees in bioinformatics and bioengineering.
Wu is a 2023 recipient of the Sloan Research Fellowship for neuroscience research. Her work straddles two of the School’s five research areas: machine learning and computational bioscience.
MRM-GP will be featured at the world’s top conference on ML and artificial intelligence. The group will share their work at the International Conference on Machine Learning (ICML 2024), which will be held July 21-27 in Vienna.
ICML 2024 also accepted for presentation a second paper from Wu’s group intersecting neuroscience and ML. The same authors will present A Differentiable Partially Observable Generalized Linear Model with Forward-Backward Message Passing.
Twenty-four Georgia Tech faculty from the Colleges of Computing and Engineering will present 40 papers at ICML 2024. Wu is one of six faculty representing the School of CSE who will present eight total papers.
The group’s ICML 2024 presentations exemplify Georgia Tech’s focus on neuroscience research as a strategic initiative.
Wu is an affiliated faculty member with the Neuro Next Initiative, a new interdisciplinary program at Georgia Tech that will lead research in neuroscience, neurotechnology, and society. The University System of Georgia Board of Regents recently approved a new neuroscience and neurotechnology Ph.D. program at Georgia Tech.
“Presenting papers at international conferences like ICML is crucial for our group to gain recognition and visibility, facilitates networking with other researchers and industry professionals, and offers valuable feedback for improving our work,” Wu said.
“It allows us to share our findings, stay updated on the latest developments in the field, and enhance our professional development and public speaking skills.”
Visit https://sites.gatech.edu/research/icml-2024 for news and coverage of Georgia Tech research presented at ICML 2024.
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu
Jun. 28, 2024



From weather prediction to drug discovery, math powers the models used in computer simulations. To help these vital tools with their calculations, global experts recently met at Georgia Tech to share ways to make math easier for computers.
Tech hosted the 2024 International Conference on Preconditioning Techniques for Scientific and Industrial Applications (Precond 24), June 10-12.
Preconditioning accelerates matrix computations, a kind of math used in most large-scale models. These computer models become faster, more efficient, and more accessible with help from preconditioned equations.
“Preconditioning transforms complex numerical problems into more easily solved ones,” said Edmond Chow, a professor at Georgia Tech and co-chair of Precond 24’s local organization and program committees.
“The new problem wields a better condition number, giving rise to the name preconditioning.”
Researchers from 13 countries presented their work through 20 mini-symposia and seven invited talks at Precond 24. Their work showcased the practicality of preconditioners.
Vandana Dwarka, an assistant professor at Delft University of Technology, shared newly developed preconditioners for electromagnetic simulations. This technology can be used in further applications ranging from imaging to designing nuclear fusion devices.
Xiaozhe Hu presented a physics-based preconditioner that simulates biophysical processes in the brain, such as blood flow and metabolic waste clearance. Hu brought this research from Tufts University, where he is an associate professor.
Tucker Hartland, a postdoctoral researcher at Lawrence Livermore National Laboratory, discussed preconditioning in contact mechanics. This work improves the modeling of interactions between physical objects that touch each other. Many fields stand to benefit from Hartland’s study, including mechanical engineering, civil engineering, and materials science.
A unique aspect of this year’s conference was an emphasis on machine learning (ML). Between a panel discussion, tutorial, and several talks, experts detailed how to employ ML for preconditioning and how preconditioning can train ML models.
Precond 24 invited seven speakers from institutions around the world to share their research with conference attendees. The presenters were:
- Monica Dessole, CERN, Switzerland
- Selime Gurol, CERFACS, France
- Alexander Heinlein, Delft University of Technology, Netherlands
- Rui Peng Li, Lawrence Livermore National Laboratory, USA
- Will Pazner, Portland State University, USA
- Tyrone Rees, Science and Technology Facilities Council, UK
- Jacob B. Schroder, University of New Mexico, USA
Along with hosting Precond 24, several Georgia Tech researchers participated in the conference through presentations.
Ph.D. students Hua Huang and Shikhar Shah each presented a paper on the conference’s first day. Alumnus Srinivas Eswar (Ph.D. CS 2022) returned to Atlanta to share research from his current role at Argonne National Laboratory. Chow chaired the ML panel and a symposium on preconditioners for matrices.
“It was an engaging and rewarding experience meeting so many people from this very tight-knit community,” said Shah, who studies computational science and engineering (CSE). “Getting to see talks close to my research provided me with a lot of inspiration and direction for future work.”
Precond 2024 was the thirteenth meeting of the conference, which occurs every two years.
The conference returned to Atlanta this year for the first time since 2005. Atlanta joins Minneapolis as one of only two cities in the world to host Precond more than once. Precond 24 marked the sixth time the conference met in the U.S.
Georgia Tech and Emory University’s Department of Mathematics organized and sponsored Precond 24. The U.S. Department of Energy Office of Science co-sponsored the conference with Tech and Emory.
Georgia Tech entities swarmed together in support of Precond 24. The Office of the Associate Vice President for Research Operations and Infrastructure, College of Computing, and School of CSE co-sponsored the conference.
“The enthusiasm at the conference has been very gratifying. So many people organized sessions at the conference and contributed to the very strong attendance,” Chow said.
“This is a testament to the continued importance of preconditioning and related numerical methods in a rapidly changing technological world.”
News Contact
Bryant Wine, Communications Officer
bryant.wine@cc.gatech.edu